Edition 7
Abstract
Table of Contents
List of Figures
List of Tables
Table of Contents
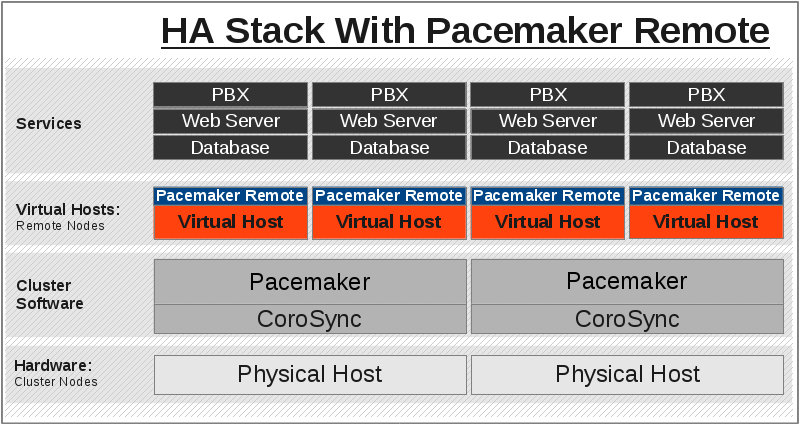
crm_mon, crm_resource and so on), execute fencing actions, count toward cluster quorum, and serve as the cluster’s Designated Controller (DC).
Note
Note
1.1.18
1.1.16
1.1.15
1.1.14
1.1.13
#kind built-in node attribute for use with rules
1.1.12
1.1.11
1.1.10
1.1.9
crm_mon output as nodes.
Table of Contents
/etc/pacemaker/authkey on every cluster node and virtual machine. This secures remote communication.
dd if=/dev/urandom of=/etc/pacemaker/authkey bs=4096 count=1
yum install pacemaker-remote resource-agents systemctl enable pacemaker_remote firewall-cmd --add-port 3121/tcp --permanent
Note
# pcs resource create vm-guest1 VirtualDomain hypervisor="qemu:///system" config="vm-guest1.xml" meta remote-node="guest1"
<primitive class="ocf" id="vm-guest1" provider="heartbeat" type="VirtualDomain"> <instance_attributes id="vm-guest-instance_attributes"> <nvpair id="vm-guest1-instance_attributes-hypervisor" name="hypervisor" value="qemu:///system"/> <nvpair id="vm-guest1-instance_attributes-config" name="config" value="guest1.xml"/> </instance_attributes> <operations> <op id="vm-guest1-interval-30s" interval="30s" name="monitor"/> </operations> <meta_attributes id="vm-guest1-meta_attributes"> <nvpair id="vm-guest1-meta_attributes-remote-node" name="remote-node" value="guest1"/> </meta_attributes> </primitive>
Note
crm_mon output as normal:
crm_mon output after guest1 is integrated into clusterLast updated: Wed Mar 13 13:52:39 2013 Last change: Wed Mar 13 13:25:17 2013 via crmd on node1 Stack: corosync Current DC: node1 (24815808) - partition with quorum Version: 1.1.10 2 Nodes configured, unknown expected votes 2 Resources configured. Online: [ node1 guest1] vm-guest1 (ocf::heartbeat:VirtualDomain): Started node1
# pcs resource create webserver apache params configfile=/etc/httpd/conf/httpd.conf op monitor interval=30s # pcs constraint location webserver prefers guest1
Last updated: Wed Mar 13 13:52:39 2013 Last change: Wed Mar 13 13:25:17 2013 via crmd on node1 Stack: corosync Current DC: node1 (24815808) - partition with quorum Version: 1.1.10 2 Nodes configured, unknown expected votes 2 Resources configured. Online: [ node1 guest1] vm-guest1 (ocf::heartbeat:VirtualDomain): Started node1 webserver (ocf::heartbeat::apache): Started guest1
crm_mon, crm_resource, and crm_attribute will work natively on the guest node, as long as the connection between the guest node and a cluster node exists. This is particularly important for any master/slave resources executing on the guest node that need access to crm_master to set transient attributes.
Table of Contents
Table 3.1. Meta-attributes for configuring VM resources as guest nodes
| Option | Default | Description |
|---|---|---|
remote-node
|
none
|
The node name of the guest node this resource defines. This both enables the resource as a guest node and defines the unique name used to identify the guest node. If no other parameters are set, this value will also be assumed as the hostname to use when connecting to pacemaker_remote on the VM. This value must not overlap with any resource or node IDs.
|
remote-port
|
3121
|
The port on the virtual machine that the cluster will use to connect to pacemaker_remote.
|
remote-addr
|
value of
remote-node
|
The IP address or hostname to use when connecting to pacemaker_remote on the VM.
|
remote-connect-timeout
|
60s
|
How long before a pending guest connection will time out.
|
pcs command:
# pcs resource describe remote
ocf:pacemaker:remote - remote resource agent
Resource options:
server: Server location to connect to. This can be an ip address or hostname.
port: tcp port to connect to.
reconnect_interval: Interval in seconds at which Pacemaker will attempt to
reconnect to a remote node after an active connection to
the remote node has been severed. When this value is
nonzero, Pacemaker will retry the connection
indefinitely, at the specified interval. As with any
time-based actions, this is not guaranteed to be checked
more frequently than the value of the
cluster-recheck-interval cluster option.# pcs resource create remote1 remote
# pcs resource create remote1 remote server=192.168.122.200 port=8938
/etc/pacemaker/authkey on each node.
/etc/sysconfig/pacemaker or /etc/default/pacemaker file.
#==#==# Pacemaker Remote # Use a custom directory for finding the authkey. PCMK_authkey_location=/etc/pacemaker/authkey # # Specify a custom port for Pacemaker Remote connections PCMK_remote_port=3121
# crm_node --force --remove $NODE_NAME
Warning
Table of Contents
Note
# firewall-cmd --permanent --add-service=high-availability success # firewall-cmd --reload success
Note
[root@pcmk-1 ~]# setenforce 0 [root@pcmk-1 ~]# sed -i.bak "s/SELINUX=enforcing/SELINUX=permissive/g" /etc/selinux/config [root@pcmk-1 ~]# systemctl mask firewalld.service [root@pcmk-1 ~]# systemctl stop firewalld.service [root@pcmk-1 ~]# iptables --flush
/etc/corosync/corosync.conf. That config file must be initialized with information about the cluster nodes before pacemaker can start.
pcs command, replacing the cluster name and hostname as desired:
# pcs cluster setup --force --local --name mycluster example-host
Note
# mkdir -p --mode=0750 /etc/pacemaker # chgrp haclient /etc/pacemaker
# dd if=/dev/urandom of=/etc/pacemaker/authkey bs=4096 count=1
Note
# pcs cluster start
# pcs status corosync
Membership information
----------------------
Nodeid Votes Name
1 1 example-host (local)# pcs status Cluster name: mycluster WARNING: no stonith devices and stonith-enabled is not false Last updated: Fri Oct 9 15:18:32 2015 Last change: Fri Oct 9 12:42:21 2015 by root via cibadmin on example-host Stack: corosync Current DC: NONE 1 node and 0 resources configured Node example-host: UNCLEAN (offline) Full list of resources: PCSD Status: example-host: Online Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
# pcs status Cluster name: mycluster WARNING: no stonith devices and stonith-enabled is not false Last updated: Fri Oct 9 15:20:05 2015 Last change: Fri Oct 9 12:42:21 2015 by root via cibadmin on example-host Stack: corosync Current DC: example-host (version 1.1.13-a14efad) - partition WITHOUT quorum 1 node and 0 resources configured Online: [ example-host ] Full list of resources: PCSD Status: example-host: Online Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
# pcs property set stonith-enabled=false # pcs property set no-quorum-policy=ignore
Warning
stonith-enabled=false is completely inappropriate for a production cluster. It tells the cluster to simply pretend that failed nodes are safely powered off. Some vendors will refuse to support clusters that have STONITH disabled. We disable STONITH here only to focus the discussion on pacemaker_remote, and to be able to use a single physical host in the example.
# pcs status Cluster name: mycluster Last updated: Fri Oct 9 15:22:49 2015 Last change: Fri Oct 9 15:22:46 2015 by root via cibadmin on example-host Stack: corosync Current DC: example-host (version 1.1.13-a14efad) - partition with quorum 1 node and 0 resources configured Online: [ example-host ] Full list of resources: PCSD Status: example-host: Online Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
# pcs cluster stop --force
# yum install -y kvm libvirt qemu-system qemu-kvm bridge-utils virt-manager # systemctl enable libvirtd.service
Note
# yum install -y pacemaker pacemaker-remote resource-agents # systemctl enable pacemaker_remote.service
# mkdir -p --mode=0750 /etc/pacemaker # chgrp haclient /etc/pacemaker # scp root@example-host:/etc/pacemaker/authkey /etc/pacemaker
# systemctl start pacemaker_remote
# systemctl status pacemaker_remote
pacemaker_remote.service - Pacemaker Remote Service
Loaded: loaded (/usr/lib/systemd/system/pacemaker_remote.service; enabled)
Active: active (running) since Thu 2013-03-14 18:24:04 EDT; 2min 8s ago
Main PID: 1233 (pacemaker_remot)
CGroup: name=systemd:/system/pacemaker_remote.service
└─1233 /usr/sbin/pacemaker_remoted
Mar 14 18:24:04 guest1 systemd[1]: Starting Pacemaker Remote Service...
Mar 14 18:24:04 guest1 systemd[1]: Started Pacemaker Remote Service.
Mar 14 18:24:04 guest1 pacemaker_remoted[1233]: notice: lrmd_init_remote_tls_server: Starting a tls listener on port 3121./etc/hosts file if you haven’t already. This is required unless you have DNS setup in a way where guest1’s address can be discovered.
# cat << END >> /etc/hosts 192.168.122.10 guest1 END
# ssh -p 3121 guest1 ssh_exchange_identification: read: Connection reset by peer
# ssh -p 3121 guest1 ssh: connect to host guest1 port 3121: No route to host
# ssh -p 3121 guest1 ssh: connect to host guest1 port 3121: Connection refused
# pcs cluster start
pcs status should look as it did in Section 4.1.6, “Disable STONITH and Quorum”.
/etc/hosts file so we can connect by hostname. For this example:
# cat << END >> /etc/hosts 192.168.122.10 guest1 END
# virsh list --all Id Name State ---------------------------------------------------- - guest1 shut off
# virsh dumpxml guest1 > /etc/pacemaker/guest1.xml
# pcs resource create vm-guest1 VirtualDomain hypervisor="qemu:///system" \
config="/etc/pacemaker/guest1.xml" meta remote-node=guest1Note
setenforce 0. If it works after that, see SELinux documentation for how to troubleshoot, if you wish to reenable SELinux.
Note
pcs status output as a node. The final pcs status output should look something like this.
# pcs status Cluster name: mycluster Last updated: Fri Oct 9 18:00:45 2015 Last change: Fri Oct 9 17:53:44 2015 by root via crm_resource on example-host Stack: corosync Current DC: example-host (version 1.1.13-a14efad) - partition with quorum 2 nodes and 2 resources configured Online: [ example-host ] GuestOnline: [ guest1@example-host ] Full list of resources: vm-guest1 (ocf::heartbeat:VirtualDomain): Started example-host PCSD Status: example-host: Online Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
# pcs resource create FAKE1 ocf:pacemaker:Dummy # pcs resource create FAKE2 ocf:pacemaker:Dummy # pcs resource create FAKE3 ocf:pacemaker:Dummy # pcs resource create FAKE4 ocf:pacemaker:Dummy # pcs resource create FAKE5 ocf:pacemaker:Dummy
pcs status output. In the resource section, you should see something like the following, where some of the resources started on the cluster node, and some started on the guest node.
Full list of resources: vm-guest1 (ocf::heartbeat:VirtualDomain): Started example-host FAKE1 (ocf::pacemaker:Dummy): Started guest1 FAKE2 (ocf::pacemaker:Dummy): Started guest1 FAKE3 (ocf::pacemaker:Dummy): Started example-host FAKE4 (ocf::pacemaker:Dummy): Started guest1 FAKE5 (ocf::pacemaker:Dummy): Started example-host
# pcs constraint location FAKE3 prefers guest1
pcs status output you’ll see FAKE3 is on guest1.
Full list of resources: vm-guest1 (ocf::heartbeat:VirtualDomain): Started example-host FAKE1 (ocf::pacemaker:Dummy): Started guest1 FAKE2 (ocf::pacemaker:Dummy): Started guest1 FAKE3 (ocf::pacemaker:Dummy): Started guest1 FAKE4 (ocf::pacemaker:Dummy): Started example-host FAKE5 (ocf::pacemaker:Dummy): Started example-host
# kill -9 `pidof pacemaker_remoted`
pcs status output will show a monitor failure, and the guest1 node will not be shown while it is being recovered.
# pcs status
Cluster name: mycluster
Last updated: Fri Oct 9 18:08:35 2015 Last change: Fri Oct 9 18:07:00 2015 by root via cibadmin on example-host
Stack: corosync
Current DC: example-host (version 1.1.13-a14efad) - partition with quorum
2 nodes and 7 resources configured
Online: [ example-host ]
Full list of resources:
vm-guest1 (ocf::heartbeat:VirtualDomain): Started example-host
FAKE1 (ocf::pacemaker:Dummy): Stopped
FAKE2 (ocf::pacemaker:Dummy): Stopped
FAKE3 (ocf::pacemaker:Dummy): Stopped
FAKE4 (ocf::pacemaker:Dummy): Started example-host
FAKE5 (ocf::pacemaker:Dummy): Started example-host
Failed Actions:
* guest1_monitor_30000 on example-host 'unknown error' (1): call=8, status=Error, exitreason='none',
last-rc-change='Fri Oct 9 18:08:29 2015', queued=0ms, exec=0ms
PCSD Status:
example-host: Online
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabledNote
pcs status output should look something like this.
Cluster name: mycluster
Last updated: Fri Oct 9 18:18:30 2015 Last change: Fri Oct 9 18:07:00 2015 by root via cibadmin on example-host
Stack: corosync
Current DC: example-host (version 1.1.13-a14efad) - partition with quorum
2 nodes and 7 resources configured
Online: [ example-host ]
GuestOnline: [ guest1@example-host ]
Full list of resources:
vm-guest1 (ocf::heartbeat:VirtualDomain): Started example-host
FAKE1 (ocf::pacemaker:Dummy): Started guest1
FAKE2 (ocf::pacemaker:Dummy): Started guest1
FAKE3 (ocf::pacemaker:Dummy): Started guest1
FAKE4 (ocf::pacemaker:Dummy): Started example-host
FAKE5 (ocf::pacemaker:Dummy): Started example-host
Failed Actions:
* guest1_monitor_30000 on example-host 'unknown error' (1): call=8, status=Error, exitreason='none',
last-rc-change='Fri Oct 9 18:08:29 2015', queued=0ms, exec=0ms
PCSD Status:
example-host: Online
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled# pcs resource disable vm-guest1 --wait # pcs resource cleanup guest1 # pcs resource enable vm-guest1
crm_resource, crm_mon, crm_attribute, crm_master, etc.) to work on guest nodes natively.
crm_mon on the guest after pacemaker has integrated the guest node into the cluster. These tools just work. This means resource agents such as master/slave resources which need access to tools like crm_master work seamlessly on the guest nodes.
pcs may have partial support on guest nodes, but it is recommended to run them from a cluster node.
Table of Contents
# firewall-cmd --permanent --add-service=high-availability success # firewall-cmd --reload success
Note
# setenforce 0 # sed -i.bak "s/SELINUX=enforcing/SELINUX=permissive/g" /etc/selinux/config # systemctl mask firewalld.service # systemctl stop firewalld.service # iptables --flush
# yum install -y pacemaker-remote resource-agents pcs
# mkdir -p --mode=0750 /etc/pacemaker # chgrp haclient /etc/pacemaker
# dd if=/dev/urandom of=/etc/pacemaker/authkey bs=4096 count=1
# systemctl enable pacemaker_remote.service # systemctl start pacemaker_remote.service
# systemctl status pacemaker_remote
pacemaker_remote.service - Pacemaker Remote Service
Loaded: loaded (/usr/lib/systemd/system/pacemaker_remote.service; enabled)
Active: active (running) since Fri 2015-08-21 15:21:20 CDT; 20s ago
Main PID: 21273 (pacemaker_remot)
CGroup: /system.slice/pacemaker_remote.service
└─21273 /usr/sbin/pacemaker_remoted
Aug 21 15:21:20 remote1 systemd[1]: Starting Pacemaker Remote Service...
Aug 21 15:21:20 remote1 systemd[1]: Started Pacemaker Remote Service.
Aug 21 15:21:20 remote1 pacemaker_remoted[21273]: notice: crm_add_logfile: Additional logging available in /var/log/pacemaker.log
Aug 21 15:21:20 remote1 pacemaker_remoted[21273]: notice: lrmd_init_remote_tls_server: Starting a tls listener on port 3121.
Aug 21 15:21:20 remote1 pacemaker_remoted[21273]: notice: bind_and_listen: Listening on address ::/etc/hosts files if you haven’t already. This is required unless you have DNS set up in a way where remote1’s address can be discovered.
# cat << END >> /etc/hosts 192.168.122.10 remote1 END
# ssh -p 3121 remote1 ssh_exchange_identification: read: Connection reset by peer
# ssh -p 3121 remote1 ssh: connect to host remote1 port 3121: No route to host
# ssh -p 3121 remote1 ssh: connect to host remote1 port 3121: Connection refused
# yum install -y pacemaker corosync pcs resource-agents
# mkdir -p --mode=0750 /etc/pacemaker # chgrp haclient /etc/pacemaker # scp remote1:/etc/pacemaker/authkey /etc/pacemaker/authkey
/etc/corosync/corosync.conf. That config file must be initialized with information about the two cluster nodes before pacemaker can start.
# pcs cluster setup --force --local --name mycluster <node1 ip or hostname> <node2 ip or hostname>
# pcs cluster start
# pcs status corosync
Membership information
----------------------
Nodeid Votes Name
1 1 node1 (local)pcs cluster status output will look like this.
# pcs status Cluster name: mycluster Last updated: Fri Aug 21 16:14:05 2015 Last change: Fri Aug 21 14:02:14 2015 Stack: corosync Current DC: NONE Version: 1.1.12-a14efad 1 Nodes configured, unknown expected votes 0 Resources configured
# pcs status Cluster name: mycluster Last updated: Fri Aug 21 16:16:32 2015 Last change: Fri Aug 21 14:02:14 2015 Stack: corosync Current DC: node1 (1) - partition with quorum Version: 1.1.12-a14efad 2 Nodes configured 0 Resources configured Online: [ node1 node2 ]
# pcs property set stonith-enabled=false
/usr/lib/ocf/resource.d/pacemaker/remote file that describes what options are available, but there is no actual ocf:pacemaker:remote resource agent script that performs any work.
# pcs resource create remote1 ocf:pacemaker:remote
Cluster name: mycluster Last updated: Fri Aug 21 17:13:09 2015 Last change: Fri Aug 21 17:02:02 2015 Stack: corosync Current DC: node1 (1) - partition with quorum Version: 1.1.12-a14efad 3 Nodes configured 1 Resources configured Online: [ node1 node2 ] RemoteOnline: [ remote1 ] Full list of resources: remote1 (ocf::pacemaker:remote): Started node1 PCSD Status: node1: Online node2: Online Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
Warning
crm_resource, crm_mon, crm_attribute, crm_master, etc.) to work on remote nodes natively.
crm_mon on the remote node after pacemaker has integrated it into the cluster. These tools just work. These means resource agents such as master/slave resources which need access to tools like crm_master work seamlessly on the remote nodes.
pcs may have partial support on remote nodes, but it is recommended to run them from a cluster node.
Table of Contents
pacemaker_remote inside a container, following the process for guest nodes. This is not recommended but can be useful, for example, in testing scenarios, to simulate a large number of guest nodes.
libvirt-daemon-lxc package to get the libvirt-lxc driver for LXC containers.
pacemaker-cts package includes a script for this purpose, /usr/share/pacemaker/tests/cts/lxc_autogen.sh. Run it with the --help option for details on how to use it. It is intended for testing purposes only, and hardcodes various parameters that would need to be set appropriately in real usage. Of course, you can create XML definitions manually, following the appropriate libvirt driver documentation.
/etc/pacemaker directory with the container, or copy the key into the container’s filesystem.
| Revision History | |||
|---|---|---|---|
| Revision 1-0 | Tue Mar 19 2013 | ||
| |||
| Revision 2-0 | Tue May 13 2013 | ||
| |||
| Revision 3-0 | Fri Oct 18 2013 | ||
| |||
| Revision 4-0 | Tue Aug 25 2015 | ||
| |||
| Revision 5-0 | Tue Dec 8 2015 | ||
| |||
| Revision 6-0 | Tue May 3 2016 | ||
| |||
| Revision 7-0 | Mon Oct 31 2016 | ||
| |||