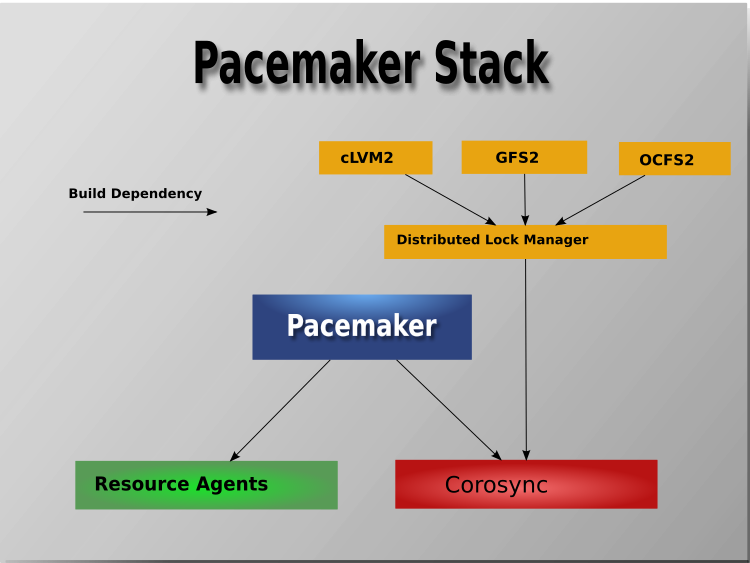
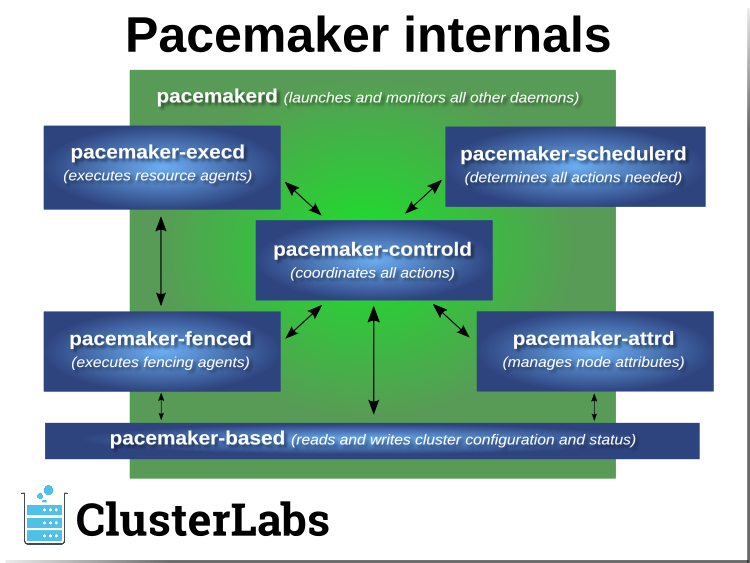
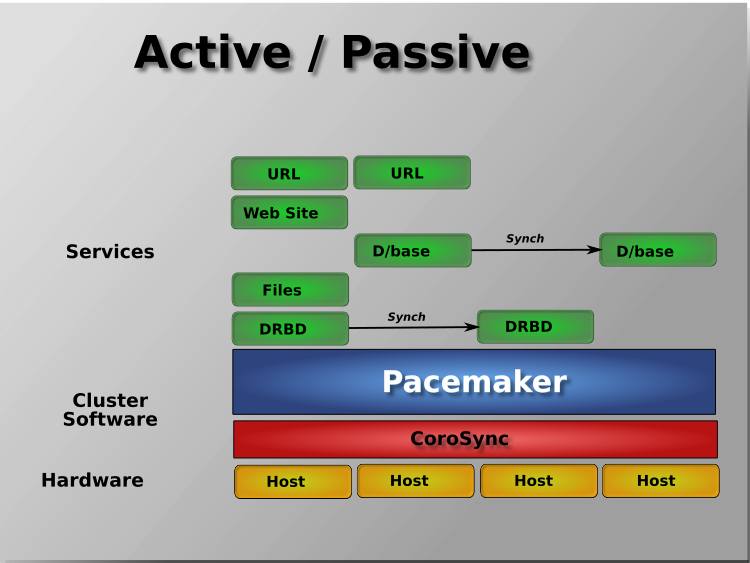
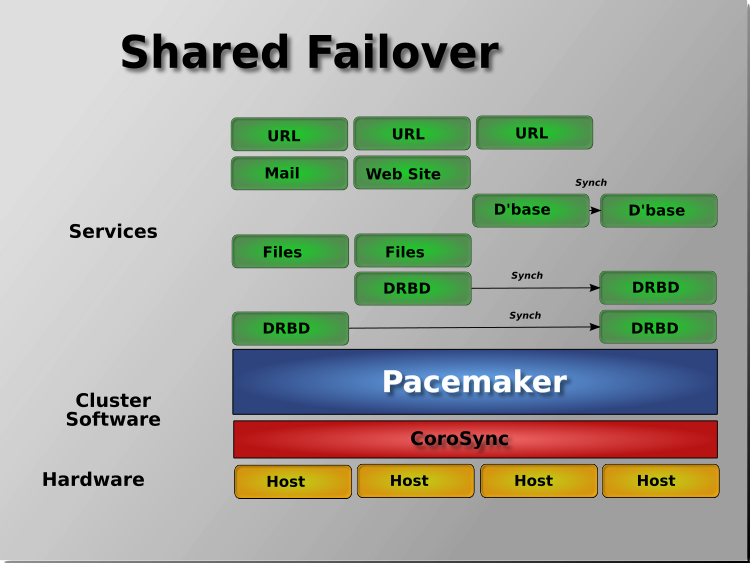
Edition 11
Abstract
Table of Contents
List of Figures
List of Examples
Table of Contents
Mono-spaced Bold
To see the contents of the filemy_next_bestselling_novelin your current working directory, enter thecat my_next_bestselling_novelcommand at the shell prompt and press Enter to execute the command.
Press Enter to execute the command.Press Ctrl+Alt+F2 to switch to a virtual terminal.
mono-spaced bold. For example:
File-related classes includefilesystemfor file systems,filefor files, anddirfor directories. Each class has its own associated set of permissions.
Choose → → from the main menu bar to launch Mouse Preferences. In the Buttons tab, select the Left-handed mouse check box and click to switch the primary mouse button from the left to the right (making the mouse suitable for use in the left hand).To insert a special character into a gedit file, choose → → from the main menu bar. Next, choose → from the Character Map menu bar, type the name of the character in the Search field and click . The character you sought will be highlighted in the Character Table. Double-click this highlighted character to place it in the Text to copy field and then click the button. Now switch back to your document and choose → from the gedit menu bar.
Mono-spaced Bold Italic or Proportional Bold Italic
To connect to a remote machine using ssh, typessh username@domain.nameat a shell prompt. If the remote machine isexample.comand your username on that machine is john, typessh john@example.com.Themount -o remount file-systemcommand remounts the named file system. For example, to remount the/homefile system, the command ismount -o remount /home.To see the version of a currently installed package, use therpm -q packagecommand. It will return a result as follows:package-version-release.
Publican is a DocBook publishing system.
mono-spaced roman and presented thus:
books Desktop documentation drafts mss photos stuff svn books_tests Desktop1 downloads images notes scripts svgs
mono-spaced roman but add syntax highlighting as follows:
package org.jboss.book.jca.ex1;
import javax.naming.InitialContext;
public class ExClient
{
public static void main(String args[])
throws Exception
{
InitialContext iniCtx = new InitialContext();
Object ref = iniCtx.lookup("EchoBean");
EchoHome home = (EchoHome) ref;
Echo echo = home.create();
System.out.println("Created Echo");
System.out.println("Echo.echo('Hello') = " + echo.echo("Hello"));
}
}Note
Important
Warning
Table of Contents
Fencing
Old daemon names
| Old name | New name |
|---|---|
|
attrd
|
pacemaker-attrd
|
|
cib
|
pacemaker-based
|
|
crmd
|
pacemaker-controld
|
|
lrmd
|
pacemaker-execd
|
|
stonithd
|
pacemaker-fenced
|
|
pacemaker_remoted
|
pacemaker-remoted
|
Table of Contents
Important
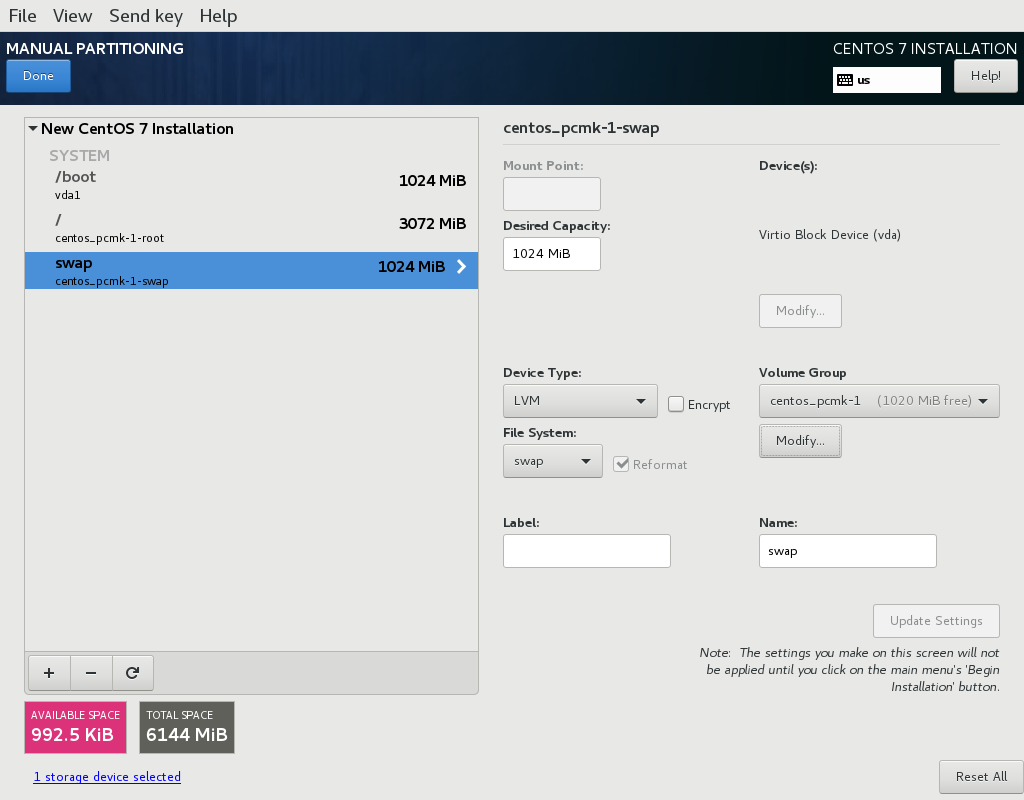
/ (aka. root) partition, which cannot be reduced in size later (dynamic increases are fine).
/ mountpoint, and reduce the desired capacity by 1GiB or so. Select Modify… by the volume group name, and change the Size policy: to As large as possible, to make the reclaimed space available inside the LVM volume group. We’ll add the additional volume later.
Note
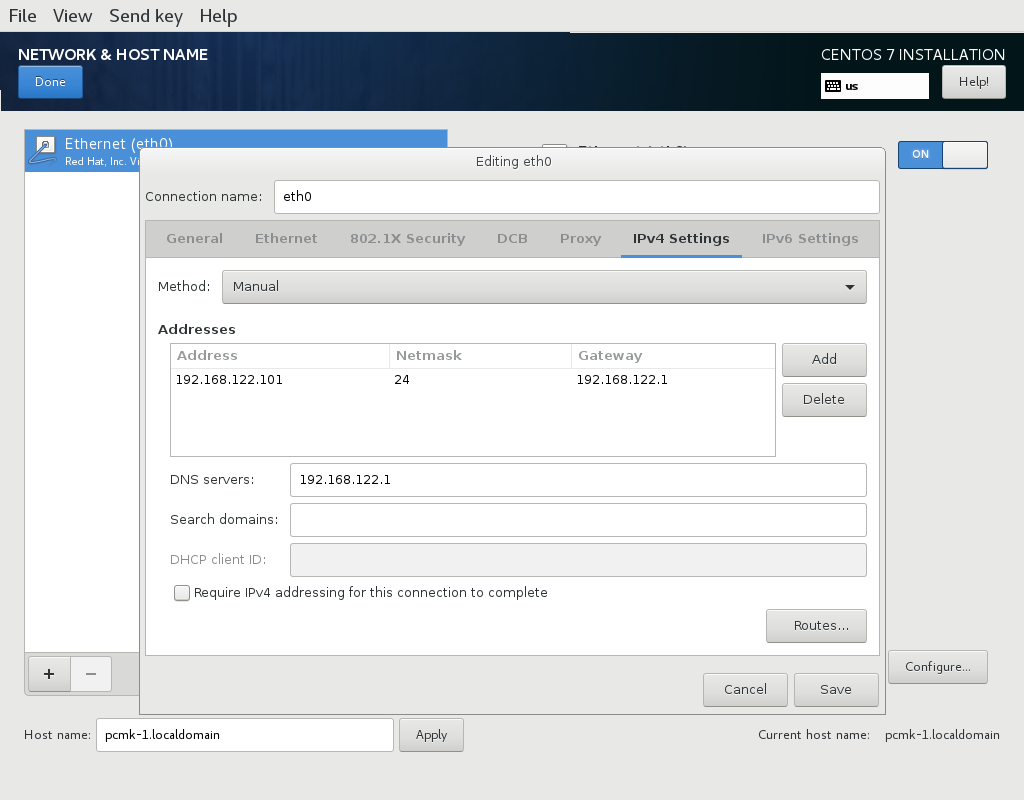
[root@pcmk-1 ~]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 52:54:00:8e:eb:41 brd ff:ff:ff:ff:ff:ff
inet 192.168.122.101/24 brd 192.168.122.255 scope global noprefixroute eth0
valid_lft forever preferred_lft forever
inet6 fe80::e45:c99b:34c0:c657/64 scope link noprefixroute
valid_lft forever preferred_lft foreverNote
[root@pcmk-1 ~]# vi /etc/sysconfig/network-scripts/ifcfg-${device} # manually edit as desired
[root@pcmk-1 ~]# nmcli dev disconnect ${device}
[root@pcmk-1 ~]# nmcli con reload ${device}
[root@pcmk-1 ~]# nmcli con up ${device}[root@pcmk-1 ~]# ip route default via 192.168.122.1 dev eth0 proto static metric 100 192.168.122.0/24 dev eth0 proto kernel scope link src 192.168.122.101 metric 100
GATEWAY="192.168.122.1"
[root@pcmk-1 ~]# ping -c 1 192.168.122.1 PING 192.168.122.1 (192.168.122.1) 56(84) bytes of data. 64 bytes from 192.168.122.1: icmp_seq=1 ttl=64 time=0.254 ms --- 192.168.122.1 ping statistics --- 1 packets transmitted, 1 received, 0% packet loss, time 0ms rtt min/avg/max/mdev = 0.254/0.254/0.254/0.000 ms
[root@pcmk-1 ~]# ping -c 1 www.clusterlabs.org PING oss-uk-1.clusterlabs.org (109.74.197.241) 56(84) bytes of data. 64 bytes from oss-uk-1.clusterlabs.org (109.74.197.241): icmp_seq=1 ttl=49 time=333 ms --- oss-uk-1.clusterlabs.org ping statistics --- 1 packets transmitted, 1 received, 0% packet loss, time 0ms rtt min/avg/max/mdev = 333.204/333.204/333.204/0.000 ms
beekhof@f16 ~ # ping -c 1 192.168.122.101 PING 192.168.122.101 (192.168.122.101) 56(84) bytes of data. 64 bytes from 192.168.122.101: icmp_req=1 ttl=64 time=1.01 ms --- 192.168.122.101 ping statistics --- 1 packets transmitted, 1 received, 0% packet loss, time 0ms rtt min/avg/max/mdev = 1.012/1.012/1.012/0.000 ms
beekhof@f16 ~ # ssh -l root 192.168.122.101 The authenticity of host '192.168.122.101 (192.168.122.101)' can't be established. ECDSA key fingerprint is 6e:b7:8f:e2:4c:94:43:54:a8:53:cc:20:0f:29:a4:e0. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added '192.168.122.101' (ECDSA) to the list of known hosts. root@192.168.122.101's password: Last login: Tue Aug 11 13:14:39 2015 [root@pcmk-1 ~]#
[root@pcmk-1 ~]# yum update
[root@pcmk-1 ~]# uname -n pcmk-1.localdomain
hostnamectl tool to strip off the domain name:
[root@pcmk-1 ~]# hostnamectl set-hostname $(uname -n | sed s/\\..*//)
[root@pcmk-1 ~]# uname -n pcmk-1
[root@pcmk-1 ~]# ping -c 3 192.168.122.102 PING 192.168.122.102 (192.168.122.102) 56(84) bytes of data. 64 bytes from 192.168.122.102: icmp_seq=1 ttl=64 time=0.343 ms 64 bytes from 192.168.122.102: icmp_seq=2 ttl=64 time=0.402 ms 64 bytes from 192.168.122.102: icmp_seq=3 ttl=64 time=0.558 ms --- 192.168.122.102 ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 2000ms rtt min/avg/max/mdev = 0.343/0.434/0.558/0.092 ms
/etc/hosts on both nodes. Below are the entries for my cluster nodes:
[root@pcmk-1 ~]# grep pcmk /etc/hosts 192.168.122.101 pcmk-1.clusterlabs.org pcmk-1 192.168.122.102 pcmk-2.clusterlabs.org pcmk-2
[root@pcmk-1 ~]# ping -c 3 pcmk-2 PING pcmk-2.clusterlabs.org (192.168.122.101) 56(84) bytes of data. 64 bytes from pcmk-1.clusterlabs.org (192.168.122.101): icmp_seq=1 ttl=64 time=0.164 ms 64 bytes from pcmk-1.clusterlabs.org (192.168.122.101): icmp_seq=2 ttl=64 time=0.475 ms 64 bytes from pcmk-1.clusterlabs.org (192.168.122.101): icmp_seq=3 ttl=64 time=0.186 ms --- pcmk-2.clusterlabs.org ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 2001ms rtt min/avg/max/mdev = 0.164/0.275/0.475/0.141 ms
Warning
[root@pcmk-1 ~]# ssh-keygen -t dsa -f ~/.ssh/id_dsa -N "" Generating public/private dsa key pair. Your identification has been saved in /root/.ssh/id_dsa. Your public key has been saved in /root/.ssh/id_dsa.pub. The key fingerprint is: 91:09:5c:82:5a:6a:50:08:4e:b2:0c:62:de:cc:74:44 root@pcmk-1.clusterlabs.org The key's randomart image is: +--[ DSA 1024]----+ |==.ooEo.. | |X O + .o o | | * A + | | + . | | . S | | | | | | | | | +-----------------+ [root@pcmk-1 ~]# cp ~/.ssh/id_dsa.pub ~/.ssh/authorized_keys
[root@pcmk-1 ~]# scp -r ~/.ssh pcmk-2: The authenticity of host 'pcmk-2 (192.168.122.102)' can't be established. ECDSA key fingerprint is SHA256:63xNPkPYq98rYznf3T9QYJAzlaGiAsSgFVNHOZjPWqc. ECDSA key fingerprint is MD5:d9:bf:6e:32:88:be:47:3d:96:f1:96:27:65:05:0b:c3. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added 'pcmk-2,192.168.122.102' (ECDSA) to the list of known hosts. root@pcmk-2's password: id_dsa id_dsa.pub authorized_keys known_hosts
[root@pcmk-1 ~]# ssh pcmk-2 -- uname -n pcmk-2
Table of Contents
pcs and crmsh. Clusters from Scratch is based on pcs because it comes with CentOS, but both have similar functionality. Choosing a shell or GUI is a matter of personal preference and what comes with (and perhaps is supported by) your choice of operating system.
# yum install -y pacemaker pcs psmisc policycoreutils-python
Important
# prompt. Be sure to run them on each node individually.
Note
pcs for cluster management. Other alternatives, such as crmsh, are available, but their syntax will differ from the examples used here.
# firewall-cmd --permanent --add-service=high-availability success # firewall-cmd --reload success
Note
[root@pcmk-1 ~]# setenforce 0 [root@pcmk-1 ~]# sed -i.bak "s/SELINUX=enforcing/SELINUX=permissive/g" /etc/selinux/config [root@pcmk-1 ~]# systemctl mask firewalld.service [root@pcmk-1 ~]# systemctl stop firewalld.service [root@pcmk-1 ~]# iptables --flush
# systemctl start pcsd.service # systemctl enable pcsd.service Created symlink from /etc/systemd/system/multi-user.target.wants/pcsd.service to /usr/lib/systemd/system/pcsd.service.
pcs commands locally, the account needs a login password in order to perform such tasks as syncing the corosync configuration, or starting and stopping the cluster on other nodes.
# passwd hacluster Changing password for user hacluster. New password: Retype new password: passwd: all authentication tokens updated successfully.
Note
--stdin option for passwd:
[root@pcmk-1 ~]# ssh pcmk-2 -- 'echo mysupersecretpassword | passwd --stdin hacluster'
pcs cluster auth to authenticate as the hacluster user:
[root@pcmk-1 ~]# pcs cluster auth pcmk-1 pcmk-2 Username: hacluster Password: pcmk-2: Authorized pcmk-1: Authorized
Note
pcs host auth:
[root@pcmk-1 ~]# pcs host auth pcmk-1 pcmk-2 Username: hacluster Password: pcmk-2: Authorized pcmk-1: Authorized
pcs cluster setup on the same node to generate and synchronize the corosync configuration:
[root@pcmk-1 ~]# pcs cluster setup --name mycluster pcmk-1 pcmk-2 Destroying cluster on nodes: pcmk-1, pcmk-2... pcmk-2: Stopping Cluster (pacemaker)... pcmk-1: Stopping Cluster (pacemaker)... pcmk-1: Successfully destroyed cluster pcmk-2: Successfully destroyed cluster Sending 'pacemaker_remote authkey' to 'pcmk-1', 'pcmk-2' pcmk-2: successful distribution of the file 'pacemaker_remote authkey' pcmk-1: successful distribution of the file 'pacemaker_remote authkey' Sending cluster config files to the nodes... pcmk-1: Succeeded pcmk-2: Succeeded Synchronizing pcsd certificates on nodes pcmk-1, pcmk-2... pcmk-2: Success pcmk-1: Success Restarting pcsd on the nodes in order to reload the certificates... pcmk-2: Success pcmk-1: Success
Note
--name option has been dropped:
[root@pcmk-1 ~]# pcs cluster setup mycluster pcmk-1 pcmk-2 No addresses specified for host 'pcmk-1', using 'pcmk-1' No addresses specified for host 'pcmk-2', using 'pcmk-2' Destroying cluster on hosts: 'pcmk-1', 'pcmk-2'... pcmk-1: Successfully destroyed cluster pcmk-2: Successfully destroyed cluster Requesting remove 'pcsd settings' from 'pcmk-1', 'pcmk-2' pcmk-1: successful removal of the file 'pcsd settings' pcmk-2: successful removal of the file 'pcsd settings' Sending 'corosync authkey', 'pacemaker authkey' to 'pcmk-1', 'pcmk-2' pcmk-2: successful distribution of the file 'corosync authkey' pcmk-2: successful distribution of the file 'pacemaker authkey' pcmk-1: successful distribution of the file 'corosync authkey' pcmk-1: successful distribution of the file 'pacemaker authkey' Synchronizing pcsd SSL certificates on nodes 'pcmk-1', 'pcmk-2'... pcmk-1: Success pcmk-2: Success Sending 'corosync.conf' to 'pcmk-1', 'pcmk-2' pcmk-2: successful distribution of the file 'corosync.conf' pcmk-1: successful distribution of the file 'corosync.conf' Cluster has been successfully set up.
Note
pcs for cluster administration, follow whatever procedures are appropriate for your tools to create a corosync.conf and copy it to all nodes.
pcs can do.
[root@pcmk-1 ~]# pcs
Usage: pcs [-f file] [-h] [commands]...
Control and configure pacemaker and corosync.
Options:
-h, --help Display usage and exit.
-f file Perform actions on file instead of active CIB.
--debug Print all network traffic and external commands run.
--version Print pcs version information. List pcs capabilities if
--full is specified.
--request-timeout Timeout for each outgoing request to another node in
seconds. Default is 60s.
--force Override checks and errors, the exact behavior depends on
the command. WARNING: Using the --force option is
strongly discouraged unless you know what you are doing.
Commands:
cluster Configure cluster options and nodes.
resource Manage cluster resources.
stonith Manage fence devices.
constraint Manage resource constraints.
property Manage pacemaker properties.
acl Manage pacemaker access control lists.
qdevice Manage quorum device provider on the local host.
quorum Manage cluster quorum settings.
booth Manage booth (cluster ticket manager).
status View cluster status.
config View and manage cluster configuration.
pcsd Manage pcs daemon.
node Manage cluster nodes.
alert Manage pacemaker alerts.pcs category help. Below is an example of all the options available under the status category.
[root@pcmk-1 ~]# pcs status help
Usage: pcs status [commands]...
View current cluster and resource status
Commands:
[status] [--full | --hide-inactive]
View all information about the cluster and resources (--full provides
more details, --hide-inactive hides inactive resources).
resources [<resource id> | --full | --groups | --hide-inactive]
Show all currently configured resources or if a resource is specified
show the options for the configured resource. If --full is specified,
all configured resource options will be displayed. If --groups is
specified, only show groups (and their resources). If --hide-inactive
is specified, only show active resources.
groups
View currently configured groups and their resources.
cluster
View current cluster status.
corosync
View current membership information as seen by corosync.
quorum
View current quorum status.
qdevice <device model> [--full] [<cluster name>]
Show runtime status of specified model of quorum device provider. Using
--full will give more detailed output. If <cluster name> is specified,
only information about the specified cluster will be displayed.
nodes [corosync | both | config]
View current status of nodes from pacemaker. If 'corosync' is
specified, view current status of nodes from corosync instead. If
'both' is specified, view current status of nodes from both corosync &
pacemaker. If 'config' is specified, print nodes from corosync &
pacemaker configuration.
pcsd [<node>]...
Show current status of pcsd on nodes specified, or on all nodes
configured in the local cluster if no nodes are specified.
xml
View xml version of status (output from crm_mon -r -1 -X).[root@pcmk-1 ~]# pacemakerd --features Pacemaker 1.1.18-11.el7_5.3 (Build: 2b07d5c5a9) Supporting v3.0.14: generated-manpages agent-manpages ncurses libqb-logging libqb-ipc systemd nagios corosync-native atomic-attrd acls
Table of Contents
pcs cluster auth command on earlier, you must authenticate on the current node you are logged into before you will be allowed to start the cluster.
[root@pcmk-1 ~]# pcs cluster start --all pcmk-1: Starting Cluster... pcmk-2: Starting Cluster...
Note
pcs cluster start --all command is to issue either of the below command sequences on each node in the cluster separately:
# pcs cluster start Starting Cluster...
# systemctl start corosync.service # systemctl start pacemaker.service
Important
pcs cluster start nodename (or --all) to start the cluster on it. While you could enable the services to start at boot, requiring a manual start of cluster services gives you the opportunity to do a post-mortem investigation of a node failure before returning it to the cluster.
corosync-cfgtool to check whether cluster communication is happy:
[root@pcmk-1 ~]# corosync-cfgtool -s
Printing ring status.
Local node ID 1
RING ID 0
id = 192.168.122.101
status = ring 0 active with no faults[root@pcmk-1 ~]# corosync-cmapctl | grep members
runtime.totem.pg.mrp.srp.members.1.config_version (u64) = 0
runtime.totem.pg.mrp.srp.members.1.ip (str) = r(0) ip(192.168.122.101)
runtime.totem.pg.mrp.srp.members.1.join_count (u32) = 1
runtime.totem.pg.mrp.srp.members.1.status (str) = joined
runtime.totem.pg.mrp.srp.members.2.config_version (u64) = 0
runtime.totem.pg.mrp.srp.members.2.ip (str) = r(0) ip(192.168.122.102)
runtime.totem.pg.mrp.srp.members.2.join_count (u32) = 1
runtime.totem.pg.mrp.srp.members.2.status (str) = joined
[root@pcmk-1 ~]# pcs status corosync
Membership information
\----------------------
Nodeid Votes Name
1 1 pcmk-1 (local)
2 1 pcmk-2[root@pcmk-1 ~]# ps axf
PID TTY STAT TIME COMMAND
2 ? S 0:00 [kthreadd]
...lots of processes...
11635 ? SLsl 0:03 corosync
11642 ? Ss 0:00 /usr/sbin/pacemakerd -f
11643 ? Ss 0:00 \_ /usr/libexec/pacemaker/cib
11644 ? Ss 0:00 \_ /usr/libexec/pacemaker/stonithd
11645 ? Ss 0:00 \_ /usr/libexec/pacemaker/lrmd
11646 ? Ss 0:00 \_ /usr/libexec/pacemaker/attrd
11647 ? Ss 0:00 \_ /usr/libexec/pacemaker/pengine
11648 ? Ss 0:00 \_ /usr/libexec/pacemaker/crmdpcs status output:
[root@pcmk-1 ~]# pcs status Cluster name: mycluster WARNING: no stonith devices and stonith-enabled is not false Stack: corosync Current DC: pcmk-2 (version 1.1.18-11.el7_5.3-2b07d5c5a9) - partition with quorum Last updated: Mon Sep 10 16:37:34 2018 Last change: Mon Sep 10 16:30:53 2018 by hacluster via crmd on pcmk-2 2 nodes configured 0 resources configured Online: [ pcmk-1 pcmk-2 ] No resources Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
[root@pcmk-1 ~]# journalctl -b | grep -i error
Note
/var/log/messages.
pcs cluster cib command.
Example 4.1. The last XML you’ll see in this document
[root@pcmk-1 ~]# pcs cluster cib
<cib crm_feature_set="3.0.14" validate-with="pacemaker-2.10" epoch="5" num_updates="4" admin_epoch="0" cib-last-written="Mon Sep 10 16:30:53 2018" update-origin="pcmk-2" update-client="crmd" update-user="hacluster" have-quorum="1" dc-uuid="2"> <configuration> <crm_config> <cluster_property_set id="cib-bootstrap-options"> <nvpair id="cib-bootstrap-options-have-watchdog" name="have-watchdog" value="false"/> <nvpair id="cib-bootstrap-options-dc-version" name="dc-version" value="1.1.18-11.el7_5.3-2b07d5c5a9"/> <nvpair id="cib-bootstrap-options-cluster-infrastructure" name="cluster-infrastructure" value="corosync"/> <nvpair id="cib-bootstrap-options-cluster-name" name="cluster-name" value="mycluster"/> </cluster_property_set> </crm_config> <nodes> <node id="1" uname="pcmk-1"/> <node id="2" uname="pcmk-2"/> </nodes> <resources/> <constraints/> </configuration> <status> <node_state id="1" uname="pcmk-1" in_ccm="true" crmd="online" crm-debug-origin="do_state_transition" join="member" expected="member"> <lrm id="1"> <lrm_resources/> </lrm> </node_state> <node_state id="2" uname="pcmk-2" in_ccm="true" crmd="online" crm-debug-origin="do_state_transition" join="member" expected="member"> <lrm id="2"> <lrm_resources/> </lrm> </node_state> </status> </cib>
[root@pcmk-1 ~]# crm_verify -L -V error: unpack_resources: Resource start-up disabled since no STONITH resources have been defined error: unpack_resources: Either configure some or disable STONITH with the stonith-enabled option error: unpack_resources: NOTE: Clusters with shared data need STONITH to ensure data integrity Errors found during check: config not valid
Table of Contents
Note
[root@pcmk-1 ~]# pcs property set stonith-enabled=false [root@pcmk-1 ~]# crm_verify -L
yum search fence-. Be sure to install the package(s) on all cluster nodes.
pcs stonith list
pcs stonith describe agent_name
pcs cluster cib stonith_cfg
pcs -f stonith_cfg stonith create stonith_id stonith_device_type [stonith_device_options]
--ssl, should be passed as ssl=1.
pcs -f stonith_cfg property set stonith-enabled=true
man pacemaker-fenced for details.
man pacemaker-fenced for details.
man pacemaker-fenced for details.
pcs cluster cib-push stonith_cfg
stonith_admin --reboot nodename
[root@pcmk-1 ~]# pcs stonith describe fence_ipmilan
fence_ipmilan - Fence agent for IPMI
fence_ipmilan is an I/O Fencing agentwhich can be used with machines controlled by IPMI.This agent calls support software ipmitool (http://ipmitool.sf.net/). WARNING! This fence agent might report success before the node is powered off. You should use -m/method onoff if your fence device works correctly with that option.
Stonith options:
ipport: TCP/UDP port to use for connection with device
hexadecimal_kg: Hexadecimal-encoded Kg key for IPMIv2 authentication
port: IP address or hostname of fencing device (together with --port-as-ip)
inet6_only: Forces agent to use IPv6 addresses only
ipaddr: IP Address or Hostname
passwd_script: Script to retrieve password
method: Method to fence (onoff|cycle)
inet4_only: Forces agent to use IPv4 addresses only
passwd: Login password or passphrase
lanplus: Use Lanplus to improve security of connection
auth: IPMI Lan Auth type.
cipher: Ciphersuite to use (same as ipmitool -C parameter)
target: Bridge IPMI requests to the remote target address
privlvl: Privilege level on IPMI device
timeout: Timeout (sec) for IPMI operation
login: Login Name
verbose: Verbose mode
debug: Write debug information to given file
power_wait: Wait X seconds after issuing ON/OFF
login_timeout: Wait X seconds for cmd prompt after login
delay: Wait X seconds before fencing is started
power_timeout: Test X seconds for status change after ON/OFF
ipmitool_path: Path to ipmitool binary
shell_timeout: Wait X seconds for cmd prompt after issuing command
port_as_ip: Make "port/plug" to be an alias to IP address
retry_on: Count of attempts to retry power on
sudo: Use sudo (without password) when calling 3rd party sotfware.
priority: The priority of the stonith resource. Devices are tried in order of highest priority to lowest.
pcmk_host_map: A mapping of host names to ports numbers for devices that do not support host names. Eg. node1:1;node2:2,3 would tell the cluster to use port 1 for node1 and ports 2 and
3 for node2
pcmk_host_list: A list of machines controlled by this device (Optional unless pcmk_host_check=static-list).
pcmk_host_check: How to determine which machines are controlled by the device. Allowed values: dynamic-list (query the device), static-list (check the pcmk_host_list attribute), none
(assume every device can fence every machine)
pcmk_delay_max: Enable a random delay for stonith actions and specify the maximum of random delay. This prevents double fencing when using slow devices such as sbd. Use this to enable a
random delay for stonith actions. The overall delay is derived from this random delay value adding a static delay so that the sum is kept below the maximum delay.
pcmk_delay_base: Enable a base delay for stonith actions and specify base delay value. This prevents double fencing when different delays are configured on the nodes. Use this to enable
a static delay for stonith actions. The overall delay is derived from a random delay value adding this static delay so that the sum is kept below the maximum delay.
pcmk_action_limit: The maximum number of actions can be performed in parallel on this device Pengine property concurrent-fencing=true needs to be configured first. Then use this to
specify the maximum number of actions can be performed in parallel on this device. -1 is unlimited.
Default operations:
monitor: interval=60spcs cluster cib stonith_cfg
[root@pcmk-1 ~]# pcs -f stonith_cfg stonith create ipmi-fencing fence_ipmilan \
pcmk_host_list="pcmk-1 pcmk-2" ipaddr=10.0.0.1 login=testuser \
passwd=acd123 op monitor interval=60s
[root@pcmk-1 ~]# pcs -f stonith_cfg stonith
ipmi-fencing (stonith:fence_ipmilan): Stopped[root@pcmk-1 ~]# pcs -f stonith_cfg property set stonith-enabled=true [root@pcmk-1 ~]# pcs -f stonith_cfg property Cluster Properties: cluster-infrastructure: corosync cluster-name: mycluster dc-version: 1.1.18-11.el7_5.3-2b07d5c5a9 have-watchdog: false stonith-enabled: true
pcs cluster cib-push stonith_cfg --config
[root@pcmk-1 ~]# pcs cluster stop pcmk-2 [root@pcmk-1 ~]# stonith_admin --reboot pcmk-2
pcs cluster start).
Table of Contents
Warning
[root@pcmk-1 ~]# pcs resource create ClusterIP ocf:heartbeat:IPaddr2 \
ip=192.168.122.120 cidr_netmask=24 op monitor interval=30s[root@pcmk-1 ~]# pcs resource standards lsb ocf service systemd
[root@pcmk-1 ~]# pcs resource providers heartbeat openstack pacemaker
[root@pcmk-1 ~]# pcs resource agents ocf:heartbeat apache aws-vpc-move-ip awseip awsvip azure-lb clvm . . (skipping lots of resources to save space) . symlink tomcat VirtualDomain Xinetd
[root@pcmk-1 ~]# pcs status Cluster name: mycluster Stack: corosync Current DC: pcmk-2 (version 1.1.18-11.el7_5.3-2b07d5c5a9) - partition with quorum Last updated: Mon Sep 10 16:55:26 2018 Last change: Mon Sep 10 16:53:42 2018 by root via cibadmin on pcmk-1 2 nodes configured 1 resource configured Online: [ pcmk-1 pcmk-2 ] Full list of resources: ClusterIP (ocf::heartbeat:IPaddr2): Started pcmk-1 Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
[root@pcmk-1 ~]# pcs status Cluster name: mycluster Stack: corosync Current DC: pcmk-2 (version 1.1.18-11.el7_5.3-2b07d5c5a9) - partition with quorum Last updated: Mon Sep 10 16:55:26 2018 Last change: Mon Sep 10 16:53:42 2018 by root via cibadmin on pcmk-1 2 nodes configured 1 resource configured Online: [ pcmk-1 pcmk-2 ] Full list of resources: ClusterIP (ocf::heartbeat:IPaddr2): Started pcmk-1
[root@pcmk-1 ~]# pcs cluster stop pcmk-1 Stopping Cluster (pacemaker)... Stopping Cluster (corosync)...
Note
pcs cluster stop nodename can be run from any node in the cluster, not just the affected node.
[root@pcmk-1 ~]# pcs status Error: cluster is not currently running on this node
[root@pcmk-2 ~]# pcs status Cluster name: mycluster Stack: corosync Current DC: pcmk-2 (version 1.1.18-11.el7_5.3-2b07d5c5a9) - partition with quorum Last updated: Mon Sep 10 16:57:22 2018 Last change: Mon Sep 10 16:53:42 2018 by root via cibadmin on pcmk-1 2 nodes configured 1 resource configured Online: [ pcmk-2 ] OFFLINE: [ pcmk-1 ] Full list of resources: ClusterIP (ocf::heartbeat:IPaddr2): Started pcmk-2 Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
pcs commands, but it is not participating in the cluster).
Quorum
total_nodes < 2 * active_nodes
pcs cluster setup command will automatically configure two_node: 1 in corosync.conf, so a two-node cluster will "just work".
corosync.conf appropriately yourself.
[root@pcmk-1 ~]# pcs cluster start pcmk-1 pcmk-1: Starting Cluster... [root@pcmk-1 ~]# pcs status Cluster name: mycluster Stack: corosync Current DC: pcmk-2 (version 1.1.18-11.el7_5.3-2b07d5c5a9) - partition with quorum Last updated: Mon Sep 10 17:00:04 2018 Last change: Mon Sep 10 16:53:42 2018 by root via cibadmin on pcmk-1 2 nodes configured 1 resource configured Online: [ pcmk-1 pcmk-2 ] Full list of resources: ClusterIP (ocf::heartbeat:IPaddr2): Started pcmk-2 Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
[root@pcmk-1 ~]# pcs resource defaults resource-stickiness=100 Warning: Defaults do not apply to resources which override them with their own defined values [root@pcmk-1 ~]# pcs resource defaults resource-stickiness: 100
Table of Contents
# yum install -y httpd wget # firewall-cmd --permanent --add-service=http # firewall-cmd --reload
Important
# cat <<-END >/var/www/html/index.html <html> <body>My Test Site - $(hostname)</body> </html> END
# cat <<-END >/etc/httpd/conf.d/status.conf
<Location /server-status>
SetHandler server-status
Require local
</Location>
ENDNote
[root@pcmk-1 ~]# pcs resource create WebSite ocf:heartbeat:apache \
configfile=/etc/httpd/conf/httpd.conf \
statusurl="http://localhost/server-status" \
op monitor interval=1min[root@pcmk-1 ~]# pcs resource op defaults timeout=240s Warning: Defaults do not apply to resources which override them with their own defined values [root@pcmk-1 ~]# pcs resource op defaults timeout: 240s
Note
[root@pcmk-1 ~]# pcs status Cluster name: mycluster Stack: corosync Current DC: pcmk-2 (version 1.1.18-11.el7_5.3-2b07d5c5a9) - partition with quorum Last updated: Mon Sep 10 17:06:22 2018 Last change: Mon Sep 10 17:05:41 2018 by root via cibadmin on pcmk-1 2 nodes configured 2 resources configured Online: [ pcmk-1 pcmk-2 ] Full list of resources: ClusterIP (ocf::heartbeat:IPaddr2): Started pcmk-2 WebSite (ocf::heartbeat:apache): Started pcmk-1 Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
Note
pcs status output, you see the WebSite resource has failed to start, then you’ve likely not enabled the status URL correctly. You can check whether this is the problem by running:
wget -O - http://localhost/server-status
Note
Important
[root@pcmk-1 ~]# pcs constraint colocation add WebSite with ClusterIP INFINITY [root@pcmk-1 ~]# pcs constraint Location Constraints: Ordering Constraints: Colocation Constraints: WebSite with ClusterIP (score:INFINITY) Ticket Constraints: [root@pcmk-1 ~]# pcs status Cluster name: mycluster Stack: corosync Current DC: pcmk-2 (version 1.1.18-11.el7_5.3-2b07d5c5a9) - partition with quorum Last updated: Mon Sep 10 17:08:54 2018 Last change: Mon Sep 10 17:08:27 2018 by root via cibadmin on pcmk-1 2 nodes configured 2 resources configured Online: [ pcmk-1 pcmk-2 ] Full list of resources: ClusterIP (ocf::heartbeat:IPaddr2): Started pcmk-2 WebSite (ocf::heartbeat:apache): Started pcmk-2 Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
[root@pcmk-1 ~]# pcs constraint order ClusterIP then WebSite Adding ClusterIP WebSite (kind: Mandatory) (Options: first-action=start then-action=start) [root@pcmk-1 ~]# pcs constraint Location Constraints: Ordering Constraints: start ClusterIP then start WebSite (kind:Mandatory) Colocation Constraints: WebSite with ClusterIP (score:INFINITY) Ticket Constraints:
[root@pcmk-1 ~]# pcs constraint location WebSite prefers pcmk-1=50
[root@pcmk-1 ~]# pcs constraint
Location Constraints:
Resource: WebSite
Enabled on: pcmk-1 (score:50)
Ordering Constraints:
start ClusterIP then start WebSite (kind:Mandatory)
Colocation Constraints:
WebSite with ClusterIP (score:INFINITY)
Ticket Constraints:
[root@pcmk-1 ~]# pcs status
Cluster name: mycluster
Stack: corosync
Current DC: pcmk-2 (version 1.1.18-11.el7_5.3-2b07d5c5a9) - partition with quorum
Last updated: Mon Sep 10 17:21:41 2018
Last change: Mon Sep 10 17:21:14 2018 by root via cibadmin on pcmk-1
2 nodes configured
2 resources configured
Online: [ pcmk-1 pcmk-2 ]
Full list of resources:
ClusterIP (ocf::heartbeat:IPaddr2): Started pcmk-2
WebSite (ocf::heartbeat:apache): Started pcmk-2
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled[root@pcmk-1 ~]# crm_simulate -sL Current cluster status: Online: [ pcmk-1 pcmk-2 ] ClusterIP (ocf::heartbeat:IPaddr2): Started pcmk-2 WebSite (ocf::heartbeat:apache): Started pcmk-2 Allocation scores: native_color: ClusterIP allocation score on pcmk-1: 50 native_color: ClusterIP allocation score on pcmk-2: 200 native_color: WebSite allocation score on pcmk-1: -INFINITY native_color: WebSite allocation score on pcmk-2: 100 Transition Summary:
[root@pcmk-1 ~]# pcs resource move WebSite pcmk-1
[root@pcmk-1 ~]# pcs constraint
Location Constraints:
Resource: WebSite
Enabled on: pcmk-1 (score:50)
Enabled on: pcmk-1 (score:INFINITY) (role: Started)
Ordering Constraints:
start ClusterIP then start WebSite (kind:Mandatory)
Colocation Constraints:
WebSite with ClusterIP (score:INFINITY)
Ticket Constraints:
[root@pcmk-1 ~]# pcs status
Cluster name: mycluster
Stack: corosync
Current DC: pcmk-2 (version 1.1.18-11.el7_5.3-2b07d5c5a9) - partition with quorum
Last updated: Mon Sep 10 17:28:55 2018
Last change: Mon Sep 10 17:28:27 2018 by root via crm_resource on pcmk-1
2 nodes configured
2 resources configured
Online: [ pcmk-1 pcmk-2 ]
Full list of resources:
ClusterIP (ocf::heartbeat:IPaddr2): Started pcmk-1
WebSite (ocf::heartbeat:apache): Started pcmk-1
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled[root@pcmk-1 ~]# pcs resource clear WebSite
[root@pcmk-1 ~]# pcs constraint
Location Constraints:
Resource: WebSite
Enabled on: pcmk-1 (score:50)
Ordering Constraints:
start ClusterIP then start WebSite (kind:Mandatory)
Colocation Constraints:
WebSite with ClusterIP (score:INFINITY)
Ticket Constraints:[root@pcmk-1 ~]# pcs status Cluster name: mycluster Stack: corosync Current DC: pcmk-2 (version 1.1.18-11.el7_5.3-2b07d5c5a9) - partition with quorum Last updated: Mon Sep 10 17:31:47 2018 Last change: Mon Sep 10 17:31:04 2018 by root via crm_resource on pcmk-1 2 nodes configured 2 resources configured Online: [ pcmk-1 pcmk-2 ] Full list of resources: ClusterIP (ocf::heartbeat:IPaddr2): Started pcmk-1 WebSite (ocf::heartbeat:apache): Started pcmk-1 Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
Table of Contents
# rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org # rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-3.el7.elrepo.noarch.rpm Retrieving http://www.elrepo.org/elrepo-release-7.0-3.el7.elrepo.noarch.rpm Preparing... ################################# [100%] Updating / installing... 1:elrepo-release-7.0-3.el7.elrepo ################################# [100%]
# yum install -y kmod-drbd84 drbd84-utils
# semanage permissive -a drbd_t
[root@pcmk-1 ~]# firewall-cmd --permanent --add-rich-rule='rule family="ipv4" \
source address="192.168.122.102" port port="7789" protocol="tcp" accept'
success
[root@pcmk-1 ~]# firewall-cmd --reload
success[root@pcmk-2 ~]# firewall-cmd --permanent --add-rich-rule='rule family="ipv4" \
source address="192.168.122.101" port port="7789" protocol="tcp" accept'
success
[root@pcmk-2 ~]# firewall-cmd --reload
successNote
[root@pcmk-1 ~]# vgdisplay | grep -e Name -e Free VG Name centos_pcmk-1 Free PE / Size 255 / 1020.00 MiB [root@pcmk-1 ~]# lvcreate --name drbd-demo --size 512M centos_pcmk-1 Logical volume "drbd-demo" created. [root@pcmk-1 ~]# lvs LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert drbd-demo centos_pcmk-1 -wi-a----- 512.00m root centos_pcmk-1 -wi-ao---- 3.00g swap centos_pcmk-1 -wi-ao---- 1.00g
[root@pcmk-1 ~]# ssh pcmk-2 -- lvcreate --name drbd-demo --size 512M centos_pcmk-2 Logical volume "drbd-demo" created.
# cat <<END >/etc/drbd.d/wwwdata.res
resource wwwdata {
protocol C;
meta-disk internal;
device /dev/drbd1;
syncer {
verify-alg sha1;
}
net {
allow-two-primaries;
}
on pcmk-1 {
disk /dev/centos_pcmk-1/drbd-demo;
address 192.168.122.101:7789;
}
on pcmk-2 {
disk /dev/centos_pcmk-2/drbd-demo;
address 192.168.122.102:7789;
}
}
ENDImportant
Note
[root@pcmk-1 ~]# drbdadm create-md wwwdata --== Thank you for participating in the global usage survey ==-- The server's response is: you are the 2147th user to install this version initializing activity log initializing bitmap (16 KB) to all zero Writing meta data... New drbd meta data block successfully created. success [root@pcmk-1 ~]# modprobe drbd [root@pcmk-1 ~]# drbdadm up wwwdata --== Thank you for participating in the global usage survey ==-- The server's response is:
[root@pcmk-1 ~]# cat /proc/drbd
version: 8.4.11-1 (api:1/proto:86-101)
GIT-hash: 66145a308421e9c124ec391a7848ac20203bb03c build by mockbuild@, 2018-04-26 12:10:42
1: cs:WFConnection ro:Secondary/Unknown ds:Inconsistent/DUnknown C r----s
ns:0 nr:0 dw:0 dr:0 al:8 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:f oos:524236[root@pcmk-2 ~]# cat /proc/drbd
version: 8.4.11-1 (api:1/proto:86-101)
GIT-hash: 66145a308421e9c124ec391a7848ac20203bb03c build by mockbuild@, 2018-04-26 12:10:42
1: cs:Connected ro:Secondary/Secondary ds:Inconsistent/Inconsistent C r-----
ns:0 nr:0 dw:0 dr:0 al:8 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:f oos:524236[root@pcmk-1 ~]# drbdadm primary --force wwwdata
Note
[root@pcmk-1 ~]# cat /proc/drbd
version: 8.4.11-1 (api:1/proto:86-101)
GIT-hash: 66145a308421e9c124ec391a7848ac20203bb03c build by mockbuild@, 2018-04-26 12:10:42
1: cs:SyncSource ro:Primary/Secondary ds:UpToDate/Inconsistent C r-----
ns:43184 nr:0 dw:0 dr:45312 al:8 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:f oos:481052
[>...................] sync'ed: 8.6% (481052/524236)K
finish: 0:01:51 speed: 4,316 (4,316) K/sec[root@pcmk-1 ~]# cat /proc/drbd
version: 8.4.11-1 (api:1/proto:86-101)
GIT-hash: 66145a308421e9c124ec391a7848ac20203bb03c build by mockbuild@, 2018-04-26 12:10:42
1: cs:Connected ro:Primary/Secondary ds:UpToDate/UpToDate C r-----
ns:524236 nr:0 dw:0 dr:526364 al:8 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:f oos:0[root@pcmk-1 ~]# mkfs.xfs /dev/drbd1
meta-data=/dev/drbd1 isize=512 agcount=4, agsize=32765 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=131059, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=855, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0Note
[root@pcmk-1 ~]# mount /dev/drbd1 /mnt [root@pcmk-1 ~]# cat <<-END >/mnt/index.html <html> <body>My Test Site - DRBD</body> </html> END [root@pcmk-1 ~]# chcon -R --reference=/var/www/html /mnt [root@pcmk-1 ~]# umount /dev/drbd1
pcs has is the ability to queue up several changes into a file and commit those changes all at once. To do this, start by populating the file with the current raw XML config from the CIB.
[root@pcmk-1 ~]# pcs cluster cib drbd_cfg
-f option, make changes to the configuration saved in the drbd_cfg file. These changes will not be seen by the cluster until the drbd_cfg file is pushed into the live cluster’s CIB later.
[root@pcmk-1 ~]# pcs -f drbd_cfg resource create WebData ocf:linbit:drbd \
drbd_resource=wwwdata op monitor interval=60s
[root@pcmk-1 ~]# pcs -f drbd_cfg resource master WebDataClone WebData \
master-max=1 master-node-max=1 clone-max=2 clone-node-max=1 \
notify=true
[root@pcmk-1 ~]# pcs -f drbd_cfg resource show
ClusterIP (ocf::heartbeat:IPaddr2): Started pcmk-1
WebSite (ocf::heartbeat:apache): Started pcmk-1
Master/Slave Set: WebDataClone [WebData]
Stopped: [ pcmk-1 pcmk-2 ]Note
pcs command has been changed accordingly:
[root@pcmk-1 ~]# pcs -f drbd_cfg resource promotable WebData \
promoted-max=1 promoted-node-max=1 clone-max=2 clone-node-max=1 \
notify=truePcs automatically creates a name for the resource in the form of resource_name-clone, that is WebData-clone in this case.
pcs resource show command displays resources' status or configuration, the command has been deprecated in Fedora 29 and CentOS 8.0. Two new commands have been introduced for displaying resources' status and configuration: pcs resource status and pcs resource config, respectively.
[root@pcmk-1 ~]# pcs cluster cib-push drbd_cfg --config CIB updated
[root@pcmk-1 ~]# pcs status
Cluster name: mycluster
Stack: corosync
Current DC: pcmk-2 (version 1.1.18-11.el7_5.3-2b07d5c5a9) - partition with quorum
Last updated: Mon Sep 10 17:58:07 2018
Last change: Mon Sep 10 17:57:53 2018 by root via cibadmin on pcmk-1
2 nodes configured
4 resources configured
Online: [ pcmk-1 pcmk-2 ]
Full list of resources:
ClusterIP (ocf::heartbeat:IPaddr2): Started pcmk-1
WebSite (ocf::heartbeat:apache): Started pcmk-1
Master/Slave Set: WebDataClone [WebData]
Masters: [ pcmk-1 ]
Slaves: [ pcmk-2 ]
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabledImportant
# echo drbd >/etc/modules-load.d/drbd.conf
[root@pcmk-1 ~]# pcs cluster cib fs_cfg
[root@pcmk-1 ~]# pcs -f fs_cfg resource create WebFS Filesystem \
device="/dev/drbd1" directory="/var/www/html" fstype="xfs"
Assumed agent name 'ocf:heartbeat:Filesystem' (deduced from 'Filesystem')
[root@pcmk-1 ~]# pcs -f fs_cfg constraint colocation add \
WebFS with WebDataClone INFINITY with-rsc-role=Master
[root@pcmk-1 ~]# pcs -f fs_cfg constraint order \
promote WebDataClone then start WebFS
Adding WebDataClone WebFS (kind: Mandatory) (Options: first-action=promote then-action=start)[root@pcmk-1 ~]# pcs -f fs_cfg constraint colocation add WebSite with WebFS INFINITY [root@pcmk-1 ~]# pcs -f fs_cfg constraint order WebFS then WebSite Adding WebFS WebSite (kind: Mandatory) (Options: first-action=start then-action=start)
[root@pcmk-1 ~]# pcs -f fs_cfg constraint
Location Constraints:
Resource: WebSite
Enabled on: pcmk-1 (score:50)
Ordering Constraints:
start ClusterIP then start WebSite (kind:Mandatory)
promote WebDataClone then start WebFS (kind:Mandatory)
start WebFS then start WebSite (kind:Mandatory)
Colocation Constraints:
WebSite with ClusterIP (score:INFINITY)
WebFS with WebDataClone (score:INFINITY) (with-rsc-role:Master)
WebSite with WebFS (score:INFINITY)
Ticket Constraints:
[root@pcmk-1 ~]# pcs -f fs_cfg resource show
ClusterIP (ocf::heartbeat:IPaddr2): Started pcmk-1
WebSite (ocf::heartbeat:apache): Started pcmk-1
Master/Slave Set: WebDataClone [WebData]
Masters: [ pcmk-1 ]
Slaves: [ pcmk-2 ]
WebFS (ocf::heartbeat:Filesystem): Stopped[root@pcmk-1 ~]# pcs cluster cib-push fs_cfg --config
CIB updated
[root@pcmk-1 ~]# pcs status
Cluster name: mycluster
Stack: corosync
Current DC: pcmk-2 (version 1.1.18-11.el7_5.3-2b07d5c5a9) - partition with quorum
Last updated: Mon Sep 10 18:02:24 2018
Last change: Mon Sep 10 18:02:14 2018 by root via cibadmin on pcmk-1
2 nodes configured
5 resources configured
Online: [ pcmk-1 pcmk-2 ]
Full list of resources:
ClusterIP (ocf::heartbeat:IPaddr2): Started pcmk-1
WebSite (ocf::heartbeat:apache): Started pcmk-1
Master/Slave Set: WebDataClone [WebData]
Masters: [ pcmk-1 ]
Slaves: [ pcmk-2 ]
WebFS (ocf::heartbeat:Filesystem): Started pcmk-1
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabledpcs cluster stop pcmk-1 to stop all cluster services on pcmk-1, failing over the cluster resources, but there is another way to safely simulate node failure.
[root@pcmk-1 ~]# pcs cluster standby pcmk-1
[root@pcmk-1 ~]# pcs status
Cluster name: mycluster
Stack: corosync
Current DC: pcmk-2 (version 1.1.18-11.el7_5.3-2b07d5c5a9) - partition with quorum
Last updated: Mon Sep 10 18:04:22 2018
Last change: Mon Sep 10 18:03:43 2018 by root via cibadmin on pcmk-1
2 nodes configured
5 resources configured
Node pcmk-1: standby
Online: [ pcmk-2 ]
Full list of resources:
ClusterIP (ocf::heartbeat:IPaddr2): Started pcmk-2
WebSite (ocf::heartbeat:apache): Started pcmk-2
Master/Slave Set: WebDataClone [WebData]
Masters: [ pcmk-2 ]
Stopped: [ pcmk-1 ]
WebFS (ocf::heartbeat:Filesystem): Started pcmk-2
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled[root@pcmk-1 ~]# pcs cluster unstandby pcmk-1
[root@pcmk-1 ~]# pcs status
Cluster name: mycluster
Stack: corosync
Current DC: pcmk-2 (version 1.1.18-11.el7_5.3-2b07d5c5a9) - partition with quorum
Last updated: Mon Sep 10 18:05:22 2018
Last change: Mon Sep 10 18:05:21 2018 by root via cibadmin on pcmk-1
2 nodes configured
5 resources configured
Online: [ pcmk-1 pcmk-2 ]
Full list of resources:
ClusterIP (ocf::heartbeat:IPaddr2): Started pcmk-2
WebSite (ocf::heartbeat:apache): Started pcmk-2
Master/Slave Set: WebDataClone [WebData]
Masters: [ pcmk-2 ]
Slaves: [ pcmk-1 ]
WebFS (ocf::heartbeat:Filesystem): Started pcmk-2
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabledNote
pcs node standby and pcs node unstandby.
Table of Contents
# yum install -y gfs2-utils dlm
[root@pcmk-1 ~]# pcs cluster cib dlm_cfg
[root@pcmk-1 ~]# pcs -f dlm_cfg resource create dlm \
ocf:pacemaker:controld op monitor interval=60s
[root@pcmk-1 ~]# pcs -f dlm_cfg resource clone dlm clone-max=2 clone-node-max=1
[root@pcmk-1 ~]# pcs -f dlm_cfg resource show
ClusterIP (ocf::heartbeat:IPaddr2): Started pcmk-1
WebSite (ocf::heartbeat:apache): Started pcmk-1
Master/Slave Set: WebDataClone [WebData]
Masters: [ pcmk-1 ]
Slaves: [ pcmk-2 ]
WebFS (ocf::heartbeat:Filesystem): Started pcmk-1
Clone Set: dlm-clone [dlm]
Stopped: [ pcmk-1 pcmk-2 ][root@pcmk-1 ~]# pcs cluster cib-push dlm_cfg --config
CIB updated
[root@pcmk-1 ~]# pcs status
Cluster name: mycluster
Stack: corosync
Current DC: pcmk-1 (version 1.1.18-11.el7_5.3-2b07d5c5a9) - partition with quorum
Last updated: Tue Sep 11 10:18:30 2018
Last change: Tue Sep 11 10:16:49 2018 by hacluster via crmd on pcmk-2
2 nodes configured
8 resources configured
Online: [ pcmk-1 pcmk-2 ]
Full list of resources:
ipmi-fencing (stonith:fence_ipmilan): Started pcmk-1
ClusterIP (ocf::heartbeat:IPaddr2): Started pcmk-1
WebSite (ocf::heartbeat:apache): Started pcmk-1
Master/Slave Set: WebDataClone [WebData]
Masters: [ pcmk-1 ]
Slaves: [ pcmk-2 ]
WebFS (ocf::heartbeat:Filesystem): Started pcmk-1
Clone Set: dlm-clone [dlm]
Started: [ pcmk-1 pcmk-2 ]
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled[root@pcmk-1 ~]# pcs resource disable WebFS
[root@pcmk-1 ~]# pcs resource
ClusterIP (ocf::heartbeat:IPaddr2): Started pcmk-1
WebSite (ocf::heartbeat:apache): Stopped
Master/Slave Set: WebDataClone [WebData]
Masters: [ pcmk-1 ]
Slaves: [ pcmk-2 ]
WebFS (ocf::heartbeat:Filesystem): Stopped (disabled)
Clone Set: dlm-clone [dlm]
Started: [ pcmk-1 pcmk-2 ]Warning
Important
/dev/drbd1: Read-only file system
[root@pcmk-1 ~]# mkfs.gfs2 -p lock_dlm -j 2 -t mycluster:web /dev/drbd1 It appears to contain an existing filesystem (xfs) This will destroy any data on /dev/drbd1 Are you sure you want to proceed? [y/n] y Discarding device contents (may take a while on large devices): Done Adding journals: Done Building resource groups: Done Creating quota file: Done Writing superblock and syncing: Done Device: /dev/drbd1 Block size: 4096 Device size: 0.50 GB (131059 blocks) Filesystem size: 0.50 GB (131056 blocks) Journals: 2 Resource groups: 3 Locking protocol: "lock_dlm" Lock table: "mycluster:web" UUID: 0bcbffab-cada-4105-94d1-be8a26669ee0
mkfs.gfs2 command required a number of additional parameters:
-p lock_dlm specifies that we want to use the kernel’s DLM.
-j 2 indicates that the filesystem should reserve enough space for two journals (one for each node that will access the filesystem).
-t mycluster:web specifies the lock table name. The format for this field is clustername:fsname. For clustername, we need to use the same value we specified originally with pcs cluster setup --name (which is also the value of cluster_name in /etc/corosync/corosync.conf). If you are unsure what your cluster name is, you can look in /etc/corosync/corosync.conf or execute the command pcs cluster corosync pcmk-1 | grep cluster_name.
[root@pcmk-1 ~]# mount /dev/drbd1 /mnt [root@pcmk-1 ~]# cat <<-END >/mnt/index.html <html> <body>My Test Site - GFS2</body> </html> END [root@pcmk-1 ~]# chcon -R --reference=/var/www/html /mnt [root@pcmk-1 ~]# umount /dev/drbd1 [root@pcmk-1 ~]# drbdadm verify wwwdata
[root@pcmk-1 ~]# pcs resource show WebFS
Resource: WebFS (class=ocf provider=heartbeat type=Filesystem)
Attributes: device=/dev/drbd1 directory=/var/www/html fstype=xfs
Meta Attrs: target-role=Stopped
Operations: monitor interval=20 timeout=40 (WebFS-monitor-interval-20)
notify interval=0s timeout=60 (WebFS-notify-interval-0s)
start interval=0s timeout=60 (WebFS-start-interval-0s)
stop interval=0s timeout=60 (WebFS-stop-interval-0s)[root@pcmk-1 ~]# pcs resource update WebFS fstype=gfs2
[root@pcmk-1 ~]# pcs resource show WebFS
Resource: WebFS (class=ocf provider=heartbeat type=Filesystem)
Attributes: device=/dev/drbd1 directory=/var/www/html fstype=gfs2
Meta Attrs: target-role=Stopped
Operations: monitor interval=20 timeout=40 (WebFS-monitor-interval-20)
notify interval=0s timeout=60 (WebFS-notify-interval-0s)
start interval=0s timeout=60 (WebFS-start-interval-0s)
stop interval=0s timeout=60 (WebFS-stop-interval-0s)[root@pcmk-1 ~]# pcs constraint colocation add WebFS with dlm-clone INFINITY [root@pcmk-1 ~]# pcs constraint order dlm-clone then WebFS Adding dlm-clone WebFS (kind: Mandatory) (Options: first-action=start then-action=start)
[root@pcmk-1 ~]# pcs cluster cib active_cfg [root@pcmk-1 ~]# pcs -f active_cfg resource clone WebFS [root@pcmk-1 ~]# pcs -f active_cfg constraint Location Constraints: Ordering Constraints: start ClusterIP then start WebSite (kind:Mandatory) promote WebDataClone then start WebFS-clone (kind:Mandatory) start WebFS-clone then start WebSite (kind:Mandatory) start dlm-clone then start WebFS-clone (kind:Mandatory) Colocation Constraints: WebSite with ClusterIP (score:INFINITY) WebFS-clone with WebDataClone (score:INFINITY) (with-rsc-role:Master) WebSite with WebFS-clone (score:INFINITY) WebFS-clone with dlm-clone (score:INFINITY) Ticket Constraints:
[root@pcmk-1 ~]# pcs -f active_cfg resource update WebDataClone master-max=2
[root@pcmk-1 ~]# pcs cluster cib-push active_cfg --config CIB updated [root@pcmk-1 ~]# pcs resource enable WebFS
[root@pcmk-1 ~]# pcs resource
Master/Slave Set: WebDataClone [WebData]
Masters: [ pcmk-1 pcmk-2 ]
Clone Set: dlm-clone [dlm]
Started: [ pcmk-1 pcmk-2 ]
ClusterIP (ocf::heartbeat:IPaddr2): Started pcmk-1
Clone Set: WebFS-clone [WebFS]
Started: [ pcmk-1 pcmk-2 ]
WebSite (ocf::heartbeat:apache): Started pcmk-1Table of Contents
[root@pcmk-1 ~]# pcs resource
Master/Slave Set: WebDataClone [WebData]
Masters: [ pcmk-1 pcmk-2 ]
Clone Set: dlm-clone [dlm]
Started: [ pcmk-1 pcmk-2 ]
ClusterIP (ocf::heartbeat:IPaddr2): Started pcmk-1
Clone Set: WebFS-clone [WebFS]
Started: [ pcmk-1 pcmk-2 ]
WebSite (ocf::heartbeat:apache): Started pcmk-1[root@pcmk-1 ~]# pcs resource op defaults timeout: 240s
[root@pcmk-1 ~]# pcs stonith impi-fencing (stonith:fence_ipmilan): Started pcmk-1
[root@pcmk-1 ~]# pcs constraint Location Constraints: Ordering Constraints: start ClusterIP then start WebSite (kind:Mandatory) promote WebDataClone then start WebFS-clone (kind:Mandatory) start WebFS-clone then start WebSite (kind:Mandatory) start dlm-clone then start WebFS-clone (kind:Mandatory) Colocation Constraints: WebSite with ClusterIP (score:INFINITY) WebFS-clone with WebDataClone (score:INFINITY) (with-rsc-role:Master) WebSite with WebFS-clone (score:INFINITY) WebFS-clone with dlm-clone (score:INFINITY) Ticket Constraints:
[root@pcmk-1 ~]# pcs status
Cluster name: mycluster
Stack: corosync
Current DC: pcmk-1 (version 1.1.18-11.el7_5.3-2b07d5c5a9) - partition with quorum
Last updated: Tue Sep 11 10:41:53 2018
Last change: Tue Sep 11 10:40:16 2018 by root via cibadmin on pcmk-1
2 nodes configured
11 resources configured
Online: [ pcmk-1 pcmk-2 ]
Full list of resources:
ipmi-fencing (stonith:fence_ipmilan): Started pcmk-1
Master/Slave Set: WebDataClone [WebData]
Masters: [ pcmk-1 pcmk-2 ]
Clone Set: dlm-clone [dlm]
Started: [ pcmk-1 pcmk-2 ]
ClusterIP (ocf::heartbeat:IPaddr2): Started pcmk-1
Clone Set: WebFS-clone [WebFS]
Started: [ pcmk-1 pcmk-2 ]
WebSite (ocf::heartbeat:apache): Started pcmk-1
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled[root@pcmk-1 ~]# pcs cluster cib --config
<configuration> <crm_config> <cluster_property_set id="cib-bootstrap-options"> <nvpair id="cib-bootstrap-options-have-watchdog" name="have-watchdog" value="false"/> <nvpair id="cib-bootstrap-options-dc-version" name="dc-version" value="1.1.18-11.el7_5.3-2b07d5c5a9"/> <nvpair id="cib-bootstrap-options-cluster-infrastructure" name="cluster-infrastructure" value="corosync"/> <nvpair id="cib-bootstrap-options-cluster-name" name="cluster-name" value="mycluster"/> <nvpair id="cib-bootstrap-options-stonith-enabled" name="stonith-enabled" value="true"/> <nvpair id="cib-bootstrap-options-last-lrm-refresh" name="last-lrm-refresh" value="1536679009"/> </cluster_property_set> </crm_config> <nodes> <node id="1" uname="pcmk-1"/> <node id="2" uname="pcmk-2"/> </nodes> <resources> <primitive class="stonith" id="impi-fencing" type="fence_ipmilan"> <instance_attributes id="impi-fencing-instance_attributes"> <nvpair id="impi-fencing-instance_attributes-pcmk_host_list" name="pcmk_host_list" value="pcmk-1 pcmk-2"/> <nvpair id="impi-fencing-instance_attributes-ipaddr" name="ipaddr" value="10.0.0.1"/> <nvpair id="impi-fencing-instance_attributes-login" name="login" value="testuser"/> <nvpair id="impi-fencing-instance_attributes-passwd" name="passwd" value="acd123"/> </instance_attributes> <operations> <op id="impi-fencing-interval-60s" interval="60s" name="monitor"/> </operations> </primitive> <master id="WebDataClone"> <primitive class="ocf" id="WebData" provider="linbit" type="drbd"> <instance_attributes id="WebData-instance_attributes"> <nvpair id="WebData-instance_attributes-drbd_resource" name="drbd_resource" value="wwwdata"/> </instance_attributes> <operations> <op id="WebData-demote-interval-0s" interval="0s" name="demote" timeout="90"/> <op id="WebData-monitor-interval-60s" interval="60s" name="monitor"/> <op id="WebData-notify-interval-0s" interval="0s" name="notify" timeout="90"/> <op id="WebData-promote-interval-0s" interval="0s" name="promote" timeout="90"/> <op id="WebData-reload-interval-0s" interval="0s" name="reload" timeout="30"/> <op id="WebData-start-interval-0s" interval="0s" name="start" timeout="240"/> <op id="WebData-stop-interval-0s" interval="0s" name="stop" timeout="100"/> </operations> </primitive> <meta_attributes id="WebDataClone-meta_attributes"> <nvpair id="WebDataClone-meta_attributes-master-node-max" name="master-node-max" value="1"/> <nvpair id="WebDataClone-meta_attributes-clone-max" name="clone-max" value="2"/> <nvpair id="WebDataClone-meta_attributes-notify" name="notify" value="true"/> <nvpair id="WebDataClone-meta_attributes-master-max" name="master-max" value="2"/> <nvpair id="WebDataClone-meta_attributes-clone-node-max" name="clone-node-max" value="1"/> </meta_attributes> </master> <clone id="dlm-clone"> <primitive class="ocf" id="dlm" provider="pacemaker" type="controld"> <operations> <op id="dlm-monitor-interval-60s" interval="60s" name="monitor"/> <op id="dlm-start-interval-0s" interval="0s" name="start" timeout="90"/> <op id="dlm-stop-interval-0s" interval="0s" name="stop" timeout="100"/> </operations> </primitive> <meta_attributes id="dlm-clone-meta_attributes"> <nvpair id="dlm-clone-meta_attributes-clone-max" name="clone-max" value="2"/> <nvpair id="dlm-clone-meta_attributes-clone-node-max" name="clone-node-max" value="1"/> </meta_attributes> </clone> <primitive class="ocf" id="ClusterIP" provider="heartbeat" type="IPaddr2"> <instance_attributes id="ClusterIP-instance_attributes"> <nvpair id="ClusterIP-instance_attributes-cidr_netmask" name="cidr_netmask" value="24"/> <nvpair id="ClusterIP-instance_attributes-ip" name="ip" value="192.168.122.120"/> <nvpair id="ClusterIP-instance_attributes-clusterip_hash" name="clusterip_hash" value="sourceip"/> </instance_attributes> <operations> <op id="ClusterIP-monitor-interval-30s" interval="30s" name="monitor"/> <op id="ClusterIP-start-interval-0s" interval="0s" name="start" timeout="20s"/> <op id="ClusterIP-stop-interval-0s" interval="0s" name="stop" timeout="20s"/> </operations> <meta_attributes id="ClusterIP-meta_attributes"> <nvpair id="ClusterIP-meta_attributes-resource-stickiness" name="resource-stickiness" value="0"/> </meta_attributes> </primitive> <clone id="WebFS-clone"> <primitive class="ocf" id="WebFS" provider="heartbeat" type="Filesystem"> <instance_attributes id="WebFS-instance_attributes"> <nvpair id="WebFS-instance_attributes-device" name="device" value="/dev/drbd1"/> <nvpair id="WebFS-instance_attributes-directory" name="directory" value="/var/www/html"/> <nvpair id="WebFS-instance_attributes-fstype" name="fstype" value="gfs2"/> </instance_attributes> <operations> <op id="WebFS-monitor-interval-20" interval="20" name="monitor" timeout="40"/> <op id="WebFS-notify-interval-0s" interval="0s" name="notify" timeout="60"/> <op id="WebFS-start-interval-0s" interval="0s" name="start" timeout="60"/> <op id="WebFS-stop-interval-0s" interval="0s" name="stop" timeout="60"/> </operations> </primitive> </clone> <primitive class="ocf" id="WebSite" provider="heartbeat" type="apache"> <instance_attributes id="WebSite-instance_attributes"> <nvpair id="WebSite-instance_attributes-configfile" name="configfile" value="/etc/httpd/conf/httpd.conf"/> <nvpair id="WebSite-instance_attributes-statusurl" name="statusurl" value="http://localhost/server-status"/> </instance_attributes> <operations> <op id="WebSite-monitor-interval-1min" interval="1min" name="monitor"/> <op id="WebSite-start-interval-0s" interval="0s" name="start" timeout="40s"/> <op id="WebSite-stop-interval-0s" interval="0s" name="stop" timeout="60s"/> </operations> </primitive> </resources> <constraints> <rsc_colocation id="colocation-WebSite-ClusterIP-INFINITY" rsc="WebSite" score="INFINITY" with-rsc="ClusterIP"/> <rsc_order first="ClusterIP" first-action="start" id="order-ClusterIP-WebSite-mandatory" then="WebSite" then-action="start"/> <rsc_colocation id="colocation-WebFS-WebDataClone-INFINITY" rsc="WebFS-clone" score="INFINITY" with-rsc="WebDataClone" with-rsc-role="Master"/> <rsc_order first="WebDataClone" first-action="promote" id="order-WebDataClone-WebFS-mandatory" then="WebFS-clone" then-action="start"/> <rsc_colocation id="colocation-WebSite-WebFS-INFINITY" rsc="WebSite" score="INFINITY" with-rsc="WebFS-clone"/> <rsc_order first="WebFS-clone" first-action="start" id="order-WebFS-WebSite-mandatory" then="WebSite" then-action="start"/> <rsc_colocation id="colocation-WebFS-dlm-clone-INFINITY" rsc="WebFS-clone" score="INFINITY" with-rsc="dlm-clone"/> <rsc_order first="dlm-clone" first-action="start" id="order-dlm-clone-WebFS-mandatory" then="WebFS-clone" then-action="start"/> </constraints> <rsc_defaults> <meta_attributes id="rsc_defaults-options"> <nvpair id="rsc_defaults-options-resource-stickiness" name="resource-stickiness" value="100"/> </meta_attributes> </rsc_defaults> <op_defaults> <meta_attributes id="op_defaults-options"> <nvpair id="op_defaults-options-timeout" name="timeout" value="240s"/> </meta_attributes> </op_defaults> </configuration>
[root@pcmk-1 ~]# pcs status nodes Pacemaker Nodes: Online: pcmk-1 pcmk-2 Standby: Maintenance: Offline: Pacemaker Remote Nodes: Online: Standby: Maintenance: Offline:
[root@pcmk-1 ~]# pcs property Cluster Properties: cluster-infrastructure: corosync cluster-name: mycluster dc-version: 1.1.18-11.el7_5.3-2b07d5c5a9 have-watchdog: false last-lrm-refresh: 1536679009 stonith-enabled: true
[root@pcmk-1 ~]# pcs resource defaults resource-stickiness: 100
[root@pcmk-1 ~]# pcs stonith show ipmi-fencing (stonith:fence_ipmilan): Started pcmk-1 [root@pcmk-1 ~]# pcs stonith show ipmi-fencing Resource: ipmi-fencing (class=stonith type=fence_ipmilan) Attributes: ipaddr="10.0.0.1" login="testuser" passwd="acd123" pcmk_host_list="pcmk-1 pcmk-2" Operations: monitor interval=60s (fence-monitor-interval-60s)
[root@pcmk-1 ~]# pcs resource show ClusterIP
Resource: ClusterIP (class=ocf provider=heartbeat type=IPaddr2)
Attributes: cidr_netmask=24 ip=192.168.122.120 clusterip_hash=sourceip
Meta Attrs: resource-stickiness=0
Operations: monitor interval=30s (ClusterIP-monitor-interval-30s)
start interval=0s timeout=20s (ClusterIP-start-interval-0s)
stop interval=0s timeout=20s (ClusterIP-stop-interval-0s)[root@pcmk-1 ~]# pcs resource show WebDataClone
Master: WebDataClone
Meta Attrs: master-node-max=1 clone-max=2 notify=true master-max=2 clone-node-max=1
Resource: WebData (class=ocf provider=linbit type=drbd)
Attributes: drbd_resource=wwwdata
Operations: demote interval=0s timeout=90 (WebData-demote-interval-0s)
monitor interval=60s (WebData-monitor-interval-60s)
notify interval=0s timeout=90 (WebData-notify-interval-0s)
promote interval=0s timeout=90 (WebData-promote-interval-0s)
reload interval=0s timeout=30 (WebData-reload-interval-0s)
start interval=0s timeout=240 (WebData-start-interval-0s)
stop interval=0s timeout=100 (WebData-stop-interval-0s)
[root@pcmk-1 ~]# pcs constraint ref WebDataClone
Resource: WebDataClone
colocation-WebFS-WebDataClone-INFINITY
order-WebDataClone-WebFS-mandatory[root@pcmk-1 ~]# pcs resource show WebFS-clone
Clone: WebFS-clone
Resource: WebFS (class=ocf provider=heartbeat type=Filesystem)
Attributes: device=/dev/drbd1 directory=/var/www/html fstype=gfs2
Operations: monitor interval=20 timeout=40 (WebFS-monitor-interval-20)
notify interval=0s timeout=60 (WebFS-notify-interval-0s)
start interval=0s timeout=60 (WebFS-start-interval-0s)
stop interval=0s timeout=60 (WebFS-stop-interval-0s)
[root@pcmk-1 ~]# pcs constraint ref WebFS-clone
Resource: WebFS-clone
colocation-WebFS-WebDataClone-INFINITY
colocation-WebSite-WebFS-INFINITY
colocation-WebFS-dlm-clone-INFINITY
order-WebDataClone-WebFS-mandatory
order-WebFS-WebSite-mandatory
order-dlm-clone-WebFS-mandatory[root@pcmk-1 ~]# pcs resource show WebSite
Resource: WebSite (class=ocf provider=heartbeat type=apache)
Attributes: configfile=/etc/httpd/conf/httpd.conf statusurl=http://localhost/server-status
Operations: monitor interval=1min (WebSite-monitor-interval-1min)
start interval=0s timeout=40s (WebSite-start-interval-0s)
stop interval=0s timeout=60s (WebSite-stop-interval-0s)
[root@pcmk-1 ~]# pcs constraint ref WebSite
Resource: WebSite
colocation-WebSite-ClusterIP-INFINITY
colocation-WebSite-WebFS-INFINITY
order-ClusterIP-WebSite-mandatory
order-WebFS-WebSite-mandatorycorosync.conf for two-node cluster created by pcs.totem {
version: 2
cluster_name: mycluster
secauth: off
transport: udpu
}
nodelist {
node {
ring0_addr: pcmk-1
nodeid: 1
}
node {
ring0_addr: pcmk-2
nodeid: 2
}
}
quorum {
provider: corosync_votequorum
two_node: 1
}
logging {
to_logfile: yes
logfile: /var/log/cluster/corosync.log
to_syslog: yes
}
crmsh command-line shell rather than pcs) at: https://www.suse.com/documentation/sle_ha/book_sleha/data/book_sleha.html
| Revision History | |||
|---|---|---|---|
| Revision 1-0 | Mon May 17 2010 | ||
| |||
| Revision 2-0 | Wed Sep 22 2010 | ||
| |||
| Revision 3-0 | Wed Feb 9 2011 | ||
| |||
| Revision 4-0 | Wed Oct 5 2011 | ||
| |||
| Revision 5-0 | Fri Feb 10 2012 | ||
| |||
| Revision 6-0 | Tues July 3 2012 | ||
| |||
| Revision 7-0 | Fri Sept 14 2012 | ||
| |||
| Revision 8-0 | Mon Jan 05 2015 | ||
| |||
| Revision 8-1 | Thu Jan 08 2015 | ||
| |||
| Revision 9-0 | Fri Aug 14 2015 | ||
| |||
| Revision 10-0 | Fri Jan 12 2018 | ||
| |||
| Revision 10-1 | Wed Sep 5 2018 | ||
| |||
| Revision 10-2 | Fri Dec 7 2018 | , , | |
| |||
| Revision 11-0 | Thu Jul 18 2019 | ||
| |||
| Revision 11-1 | Thu Nov 21 2019 | ||
| |||