Edition 10
Abstract
Table of Contents
List of Figures
List of Tables
lrm_rsc_op jobList of Examples
OCF_CHECK_LEVEL.resource_setresource-stickiness during working hoursreloadreload Operationapcstonith resourceapcstonith resource)pingd clone with multiple jobsticketA is revokedrsc1 if ticketA is revoked192.0.2.0/24 networkTable of Contents
Mono-spaced Bold
To see the contents of the filemy_next_bestselling_novelin your current working directory, enter thecat my_next_bestselling_novelcommand at the shell prompt and press Enter to execute the command.
Press Enter to execute the command.Press Ctrl+Alt+F2 to switch to a virtual terminal.
mono-spaced bold. For example:
File-related classes includefilesystemfor file systems,filefor files, anddirfor directories. Each class has its own associated set of permissions.
Choose → → from the main menu bar to launch Mouse Preferences. In the Buttons tab, select the Left-handed mouse check box and click to switch the primary mouse button from the left to the right (making the mouse suitable for use in the left hand).To insert a special character into a gedit file, choose → → from the main menu bar. Next, choose → from the Character Map menu bar, type the name of the character in the Search field and click . The character you sought will be highlighted in the Character Table. Double-click this highlighted character to place it in the Text to copy field and then click the button. Now switch back to your document and choose → from the gedit menu bar.
Mono-spaced Bold ItalicProportional Bold Italic
To connect to a remote machine using ssh, typesshat a shell prompt. If the remote machine isusername@domain.nameexample.comand your username on that machine is john, typessh john@example.com.Themount -o remountcommand remounts the named file system. For example, to remount thefile-system/homefile system, the command ismount -o remount /home.To see the version of a currently installed package, use therpm -qcommand. It will return a result as follows:package.package-version-release
Publican is a DocBook publishing system.
mono-spaced roman and presented thus:
books Desktop documentation drafts mss photos stuff svn books_tests Desktop1 downloads images notes scripts svgs
mono-spaced roman but add syntax highlighting as follows:
package org.jboss.book.jca.ex1; import javax.naming.InitialContext; public class ExClient { public static void main(String args[]) throws Exception { InitialContext iniCtx = new InitialContext(); Object ref = iniCtx.lookup("EchoBean"); EchoHome home = (EchoHome) ref; Echo echo = home.create(); System.out.println("Created Echo"); System.out.println("Echo.echo('Hello') = " + echo.echo("Hello")); } }
Note
Important
Warning
Table of Contents
Note
Note
Table of Contents
Example 2.1. An empty configuration
<cib crm_feature_set="3.0.7" validate-with="pacemaker-1.2" admin_epoch="1" epoch="0" num_updates="0"> <configuration> <crm_config/> <nodes/> <resources/> <constraints/> </configuration> <status/> </cib>
cib: The entire CIB is enclosed with a cib tag. Certain fundamental settings are defined as attributes of this tag.
configuration: This section — the primary focus of this document — contains traditional configuration information such as what resources the cluster serves and the relationships among them.
crm_config: cluster-wide configuration options
nodes: the machines that host the cluster
resources: the services run by the cluster
constraints: indications of how resources should be placed
status: This section contains the history of each resource on each node. Based on this data, the cluster can construct the complete current state of the cluster. The authoritative source for this section is the local resource manager (lrmd process) on each cluster node, and the cluster will occasionally repopulate the entire section. For this reason, it is never written to disk, and administrators are advised against modifying it in any way.
nvpair child elements of an XML element.
crm_mon utility, which will display the current state of an active cluster. It can show the cluster status by node or by resource and can be used in either single-shot or dynamically-updating mode. There are also modes for displaying a list of the operations performed (grouped by node and resource) as well as information about failures.
crm_mon --help command.
Example 2.2. Sample output from crm_mon
============
Last updated: Fri Nov 23 15:26:13 2007
Current DC: sles-3 (2298606a-6a8c-499a-9d25-76242f7006ec)
3 Nodes configured.
5 Resources configured.
============
Node: sles-1 (1186dc9a-324d-425a-966e-d757e693dc86): online
192.168.100.181 (heartbeat::ocf:IPaddr): Started sles-1
192.168.100.182 (heartbeat:IPaddr): Started sles-1
192.168.100.183 (heartbeat::ocf:IPaddr): Started sles-1
rsc_sles-1 (heartbeat::ocf:IPaddr): Started sles-1
child_DoFencing:2 (stonith:external/vmware): Started sles-1
Node: sles-2 (02fb99a8-e30e-482f-b3ad-0fb3ce27d088): standby
Node: sles-3 (2298606a-6a8c-499a-9d25-76242f7006ec): online
rsc_sles-2 (heartbeat::ocf:IPaddr): Started sles-3
rsc_sles-3 (heartbeat::ocf:IPaddr): Started sles-3
child_DoFencing:0 (stonith:external/vmware): Started sles-3Example 2.3. Sample output from crm_mon -n
============
Last updated: Fri Nov 23 15:26:13 2007
Current DC: sles-3 (2298606a-6a8c-499a-9d25-76242f7006ec)
3 Nodes configured.
5 Resources configured.
============
Node: sles-1 (1186dc9a-324d-425a-966e-d757e693dc86): online
Node: sles-2 (02fb99a8-e30e-482f-b3ad-0fb3ce27d088): standby
Node: sles-3 (2298606a-6a8c-499a-9d25-76242f7006ec): online
Resource Group: group-1
192.168.100.181 (heartbeat::ocf:IPaddr): Started sles-1
192.168.100.182 (heartbeat:IPaddr): Started sles-1
192.168.100.183 (heartbeat::ocf:IPaddr): Started sles-1
rsc_sles-1 (heartbeat::ocf:IPaddr): Started sles-1
rsc_sles-2 (heartbeat::ocf:IPaddr): Started sles-3
rsc_sles-3 (heartbeat::ocf:IPaddr): Started sles-3
Clone Set: DoFencing
child_DoFencing:0 (stonith:external/vmware): Started sles-3
child_DoFencing:1 (stonith:external/vmware): Stopped
child_DoFencing:2 (stonith:external/vmware): Started sles-1cib.xml file manually. Ever. I’m not making this up.
cibadmin command. With cibadmin, you can query, add, remove, update or replace any part of the configuration. All changes take effect immediately, so there is no need to perform a reload-like operation.
cibadmin is to use it to save the current configuration to a temporary file, edit that file with your favorite text or XML editor, and then upload the revised configuration. [6]
Example 2.4. Safely using an editor to modify the cluster configuration
# cibadmin --query > tmp.xml # vi tmp.xml # cibadmin --replace --xml-file tmp.xml
pacemaker.rng, which may be deployed in a location such as /usr/share/pacemaker or /usr/lib/heartbeat depending on your operating system and how you installed the software.
Example 2.5. Safely using an editor to modify only the resources section
# cibadmin --query --scope resources > tmp.xml # vi tmp.xml # cibadmin --replace --scope resources --xml-file tmp.xml
Example 2.6. Searching for STONITH-related configuration items
# cibadmin -Q | grep stonith <nvpair id="cib-bootstrap-options-stonith-action" name="stonith-action" value="reboot"/> <nvpair id="cib-bootstrap-options-stonith-enabled" name="stonith-enabled" value="1"/> <primitive id="child_DoFencing" class="stonith" type="external/vmware"> <lrm_resource id="child_DoFencing:0" type="external/vmware" class="stonith"> <lrm_resource id="child_DoFencing:0" type="external/vmware" class="stonith"> <lrm_resource id="child_DoFencing:1" type="external/vmware" class="stonith"> <lrm_resource id="child_DoFencing:0" type="external/vmware" class="stonith"> <lrm_resource id="child_DoFencing:2" type="external/vmware" class="stonith"> <lrm_resource id="child_DoFencing:0" type="external/vmware" class="stonith"> <lrm_resource id="child_DoFencing:3" type="external/vmware" class="stonith">
primitive tag with id child_DoFencing, you would run:
# cibadmin --delete --xml-text '<primitive id="child_DoFencing"/>'
# crm_attribute --name stonith-enabled --update 1
# crm_standby --get-value --node somenode
# crm_resource --locate --resource my-test-rsc
Note
crm_shadow which creates a "shadow" copy of the configuration and arranges for all the command line tools to use it.
crm_shadow --create with the name of a configuration to create [7], and follow the simple on-screen instructions.
Warning
Example 2.7. Creating and displaying the active sandbox
# crm_shadow --create test Setting up shadow instance Type Ctrl-D to exit the crm_shadow shell shadow[test]: shadow[test] # crm_shadow --which test
--commit option, or discard them using the --delete option. Again, be sure to follow the on-screen instructions carefully!
crm_shadow options and commands, invoke it with the --help option.
Example 2.8. Use sandbox to make multiple changes all at once, discard them, and verify real configuration is untouched
shadow[test] # crm_failcount -r rsc_c001n01 -G
scope=status name=fail-count-rsc_c001n01 value=0
shadow[test] # crm_standby --node c001n02 -v on
shadow[test] # crm_standby --node c001n02 -G
scope=nodes name=standby value=on
shadow[test] # cibadmin --erase --force
shadow[test] # cibadmin --query
<cib cib_feature_revision="1" validate-with="pacemaker-1.0" admin_epoch="0" crm_feature_set="3.0" have-quorum="1" epoch="112"
dc-uuid="c001n01" num_updates="1" cib-last-written="Fri Jun 27 12:17:10 2008">
<configuration>
<crm_config/>
<nodes/>
<resources/>
<constraints/>
</configuration>
<status/>
</cib>
shadow[test] # crm_shadow --delete test --force
Now type Ctrl-D to exit the crm_shadow shell
shadow[test] # exit
# crm_shadow --which
No active shadow configuration defined
# cibadmin -Q
<cib cib_feature_revision="1" validate-with="pacemaker-1.0" admin_epoch="0" crm_feature_set="3.0" have-quorum="1" epoch="110"
dc-uuid="c001n01" num_updates="551">
<configuration>
<crm_config>
<cluster_property_set id="cib-bootstrap-options">
<nvpair id="cib-bootstrap-1" name="stonith-enabled" value="1"/>
<nvpair id="cib-bootstrap-2" name="pe-input-series-max" value="30000"/>crm_shadow --commit mytest --force), it is often advisable to simulate the effect of the changes with crm_simulate. For example:
# crm_simulate --live-check -VVVVV --save-graph tmp.graph --save-dotfile tmp.dot
tmp.graph and tmp.dot. Both files are representations of the same thing: the cluster’s response to your changes.
crm_simulate, use its --help option.
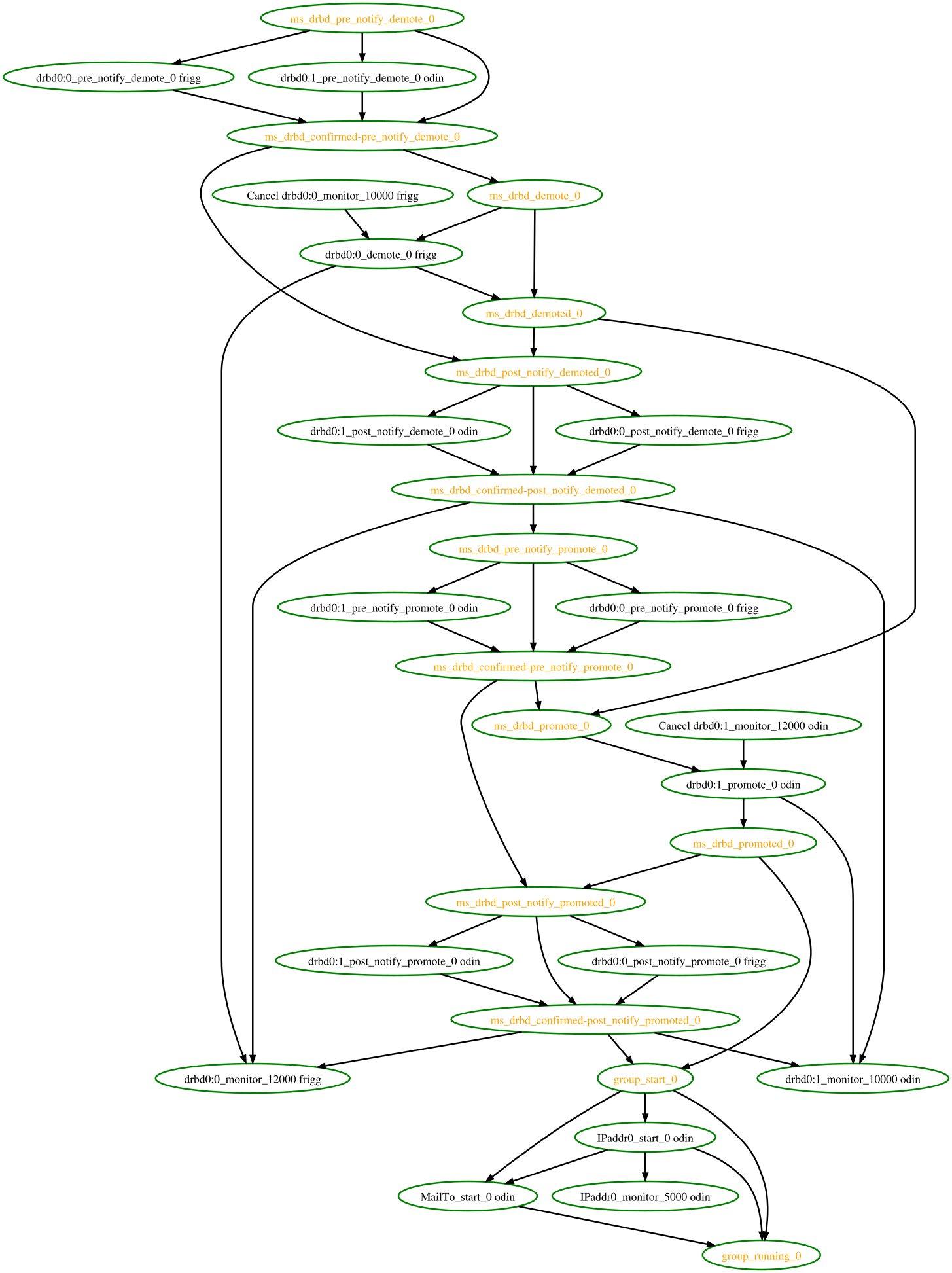
Interpreting the Graphviz output
rsc_action_interval node
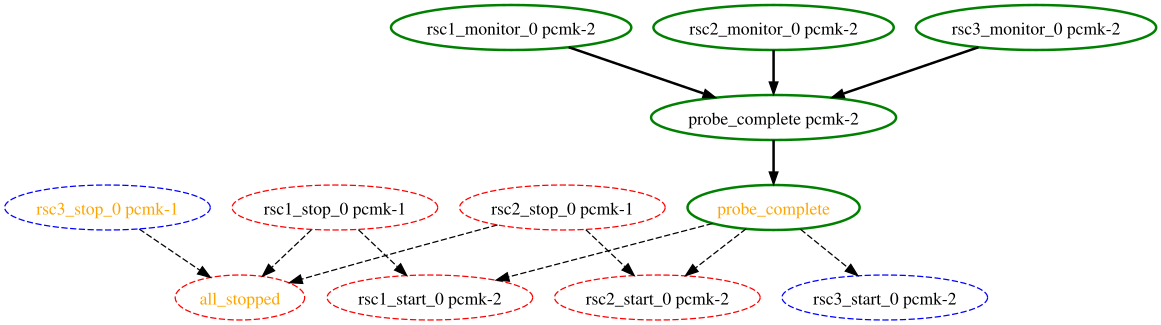
Table of Contents
cib tag) rather than with the rest of the cluster configuration in the configuration section.
Table 3.1. CIB Properties
admin_epoch, one should use:
# cibadmin --modify --xml-text '<cib admin_epoch="42"/>'
Example 3.1. Attributes set for a cib object
<cib crm_feature_set="3.0.7" validate-with="pacemaker-1.2" admin_epoch="42" epoch="116" num_updates="1" cib-last-written="Mon Jan 12 15:46:39 2015" update-origin="rhel7-1" update-client="crm_attribute" have-quorum="1" dc-uuid="1">
crm_config section, and, in advanced configurations, there may be more than one set. (This will be described later in the section on Chapter 8, Rules where we will show how to have the cluster use different sets of options during working hours than during weekends.) For now, we will describe the simple case where each option is present at most once.
man pengine and man crmd commands.
Table 3.2. Cluster Options
| Option | Default | Description |
|---|---|---|
dc-version
|
| |
cluster-infrastructure
|
| |
expected-quorum-votes
|
| |
no-quorum-policy
|
stop
|
|
batch-limit
|
0 (30 before version 1.1.11)
| |
migration-limit
|
-1
| |
symmetric-cluster
|
TRUE
| |
stop-all-resources
|
FALSE
| |
stop-orphan-resources
|
TRUE
| |
stop-orphan-actions
|
TRUE
| |
start-failure-is-fatal
|
TRUE
|
Should a failure to start a resource on a particular node prevent further start attempts on that node? If FALSE, the cluster will decide whether the same node is still eligible based on the resource’s current failure count and
migration-threshold (see Section 9.3, “Handling Resource Failure”).
|
enable-startup-probes
|
TRUE
| |
maintenance-mode
|
FALSE
| |
stonith-enabled
|
TRUE
|
Should failed nodes and nodes with resources that can’t be stopped be shot? If you value your data, set up a STONITH device and enable this.
If true, or unset, the cluster will refuse to start resources unless one or more STONITH resources have been configured. If false, unresponsive nodes are immediately assumed to be running no resources, and resource takeover to online nodes starts without any further protection (which means data loss if the unresponsive node still accesses shared storage, for example). See also the
requires meta-attribute in Section 5.4, “Resource Options”.
|
stonith-action
|
reboot
| |
stonith-timeout
|
60s
| |
stonith-max-attempts
|
10
| |
concurrent-fencing
|
FALSE
| |
cluster-delay
|
60s
|
Estimated maximum round-trip delay over the network (excluding action execution). If the TE requires an action to be executed on another node, it will consider the action failed if it does not get a response from the other node in this time (after considering the action’s own timeout). The "correct" value will depend on the speed and load of your network and cluster nodes.
|
dc-deadtime
|
20s
|
The "correct" value will depend on the speed/load of your network and the type of switches used.
|
cluster-recheck-interval
|
15min
|
The Cluster is primarily event-driven, but your configuration can have elements that take effect based on the time of day. To ensure these changes take effect, we can optionally poll the cluster’s status for changes. A value of 0 disables polling. Positive values are an interval (in seconds unless other SI units are specified, e.g. 5min).
|
cluster-ipc-limit
|
500
|
The maximum IPC message backlog before one cluster daemon will disconnect another. This is of use in large clusters, for which a good value is the number of resources in the cluster multiplied by the number of nodes. The default of 500 is also the minimum. Raise this if you see "Evicting client" messages for cluster daemon PIDs in the logs.
|
pe-error-series-max
|
-1
| |
pe-warn-series-max
|
-1
| |
pe-input-series-max
|
-1
| |
placement-strategy
|
default
|
How the cluster should allocate resources to nodes (see Chapter 12, Utilization and Placement Strategy). Allowed values are
default, utilization, balanced, and minimal. (since 1.1.0)
|
node-health-strategy
|
none
|
How the cluster should react to node health attributes (see Section 9.5, “Tracking Node Health”). Allowed values are
none, migrate-on-red, only-green, progressive, and custom.
|
node-health-base
|
0
| |
node-health-green
|
0
| |
node-health-yellow
|
0
| |
node-health-red
|
0
| |
remove-after-stop
|
FALSE
| |
startup-fencing
|
TRUE
| |
election-timeout
|
2min
| |
shutdown-escalation
|
20min
| |
crmd-integration-timeout
|
3min
| |
crmd-finalization-timeout
|
30min
| |
crmd-transition-delay
|
0s
| |
default-resource-stickiness
|
0
| |
is-managed-default
|
TRUE
| |
default-action-timeout
|
20s
|
crm_attribute tool. To get the current value of cluster-delay, you can run:
# crm_attribute --query --name cluster-delay
# crm_attribute -G -n cluster-delay
# crm_attribute -G -n cluster-delay scope=crm_config name=cluster-delay value=60s
# crm_attribute -G -n clusta-deway scope=crm_config name=clusta-deway value=(null) Error performing operation: No such device or address
# crm_attribute --name cluster-delay --update 30s
# crm_attribute --name cluster-delay --delete Deleted crm_config option: id=cib-bootstrap-options-cluster-delay name=cluster-delay
Example 3.2. Deleting an option that is listed twice
# crm_attribute --name batch-limit --delete Multiple attributes match name=batch-limit in crm_config: Value: 50 (set=cib-bootstrap-options, id=cib-bootstrap-options-batch-limit) Value: 100 (set=custom, id=custom-batch-limit) Please choose from one of the matches above and supply the 'id' with --id
Table of Contents
Example 4.1. Example Heartbeat cluster node entry
<node id="1186dc9a-324d-425a-966e-d757e693dc86" uname="pcmk-1" type="normal"/>
crm_uuid tool to read an existing UUID or define a value before the cluster starts.
uname -n. This can be problematic for services that require the uname -n to be a specific value (e.g. for a licence file).
corosync.conf under ring0_addr in the nodelist, if it does not contain an IP address; otherwise
corosync.conf under name in the nodelist; otherwise
uname -n
crm_node -n command which displays the name used by a running cluster.
crm_node --name-for-id number is also available to display the name used by the node with the corosync nodeid of number, for example: crm_node --name-for-id 2.
crm_attribute.
Example 4.3. Result of using crm_attribute to specify which kernel pcmk-1 is running
# crm_attribute --type nodes --node pcmk-1 --name kernel --update $(uname -r)
<node uname="pcmk-1" type="normal" id="101"> <instance_attributes id="nodes-101"> <nvpair id="nodes-101-kernel" name="kernel" value="3.10.0-123.13.2.el7.x86_64"/> </instance_attributes> </node>
crm_attribute again:
# crm_attribute --type nodes --node pcmk-1 --name kernel --query scope=nodes name=kernel value=3.10.0-123.13.2.el7.x86_64
--type nodes the admin tells the cluster that this attribute is persistent. There are also transient attributes which are kept in the status section which are "forgotten" whenever the node rejoins the cluster. The cluster uses this area to store a record of how many times a resource has failed on that node, but administrators can also read and write to this section by specifying --type status.
/etc/corosync/corosync.conf and /etc/corosync/authkey (if it exists) from an existing node. You may need to modify the mcastaddr option to match the new node’s IP address.
pcs cluster stop if you are using pcs for cluster management, or service corosync stop on a host using corosync 1.x with the pacemaker plugin.
# crm_node -R pcmk-1
Note
ha.cf and authkeys from an existing node.
ha.cf, run:
hb_addnode $(uname -n)
service heartbeat stop
hb_delnode pcmk-1
crm_node -R pcmk-1
Note
/var/lib/heartbeat/hostcache.
ha.cf and authkeys to the new node.
crm_uuid -w and the UUID obtained earlier.
Table of Contents
start, stop or monitor command. For this reason, it is crucial that resource agents are well-tested.
OCF_RESKEY_. So, a parameter which the user thinks of as ip will be passed to the resource agent as OCF_RESKEY_ip. The number and purpose of the parameters is left to the resource agent; however, the resource agent should use the meta-data command to advertise any that it supports.
/etc/init.d.
Warning
start/stop/status actions
Important
Important
Important
systemd, upstart, and lsb), Pacemaker supports a special service alias which intelligently figures out which one applies to a given cluster node.
systemd, upstart, and lsb.
crm_resource tool. For example:
# crm_resource --resource Email --query-xml
Note
Example 5.2. An OCF resource definition
<primitive id="Public-IP" class="ocf" type="IPaddr" provider="heartbeat"> <instance_attributes id="Public-IP-params"> <nvpair id="Public-IP-ip" name="ip" value="192.0.2.2"/> </instance_attributes> </primitive>
--meta option of the crm_resource command.
Table 5.2. Meta-attributes of a Primitive Resource
| Field | Default | Description |
|---|---|---|
priority
|
0
| |
target-role
|
Started
|
What state should the cluster attempt to keep this resource in? Allowed values:
|
is-managed
|
TRUE
| |
resource-stickiness
|
value of
resource-stickiness in the rsc_defaults section
| |
requires
|
quorum for resources with a class of stonith, otherwise unfencing if unfencing is active in the cluster, otherwise fencing if stonith-enabled is true, otherwise quorum
|
Conditions under which the resource can be started (since 1.1.8) Allowed values:
|
migration-threshold
|
INFINITY
|
How many failures may occur for this resource on a node, before this node is marked ineligible to host this resource. A value of 0 indicates that this feature is disabled (the node will never be marked ineligible); by constrast, the cluster treats INFINITY (the default) as a very large but finite number. This option has an effect only if the failed operation has on-fail=restart (the default), and additionally for failed start operations, if the cluster property start-failure-is-fatal is false.
|
failure-timeout
|
0
|
How many seconds to wait before acting as if the failure had not occurred, and potentially allowing the resource back to the node on which it failed. A value of 0 indicates that this feature is disabled. As with any time-based actions, this is not guaranteed to be checked more frequently than the value of
cluster-recheck-interval (see Section 3.2, “Cluster Options”).
|
multiple-active
|
stop_start
|
What should the cluster do if it ever finds the resource active on more than one node? Allowed values:
|
allow-migrate
|
TRUE for ocf:pacemaker:remote resources, FALSE otherwise
|
Whether the cluster should try to "live migrate" this resource when it needs to be moved (see Section 9.4.3, “Migrating Resources”)
|
container-attribute-target
|
|
Specific to bundle resources; see Section 10.4.7, “Bundle Node Attributes”
|
remote-node
|
|
The name of the Pacemaker Remote guest node this resource is associated with, if any. If specified, this both enables the resource as a guest node and defines the unique name used to identify the guest node. The guest must be configured to run the Pacemaker Remote daemon when it is started.
WARNING: This value cannot overlap with any resource or node IDs. (since 1.1.9)
|
remote-port
|
3121
|
If
remote-node is specified, the port on the guest used for its Pacemaker Remote connection. The Pacemaker Remote daemon on the guest must be configured to listen on this port. (since 1.1.9)
|
remote-addr
|
value of
remote-node
|
If
remote-node is specified, the IP address or hostname used to connect to the guest via Pacemaker Remote. The Pacemaker Remote daemon on the guest must be configured to accept connections on this address. (since 1.1.9)
|
remote-connect-timeout
|
60s
|
If
remote-node is specified, how long before a pending guest connection will time out. (since 1.1.10)
|
# crm_resource --meta --resource Email --set-parameter priority --parameter-value 100 # crm_resource -m -r Email -p multiple-active -v block
Example 5.3. An LSB resource with cluster options
<primitive id="Email" class="lsb" type="exim"> <meta_attributes id="Email-meta_attributes"> <nvpair id="Email-meta_attributes-priority" name="priority" value="100"/> <nvpair id="Email-meta_attributes-multiple-active" name="multiple-active" value="block"/> </meta_attributes> </primitive>
rsc_defaults section with crm_attribute. For example,
# crm_attribute --type rsc_defaults --name is-managed --update false
is-managed set to true).
crm_resource command. For example,
# crm_resource --resource Public-IP --set-parameter ip --parameter-value 192.0.2.2
Example 5.4. An example OCF resource with instance attributes
<primitive id="Public-IP" class="ocf" type="IPaddr" provider="heartbeat"> <instance_attributes id="params-public-ip"> <nvpair id="public-ip-addr" name="ip" value="192.0.2.2"/> </instance_attributes> </primitive>
OCF_RESKEY_ip with a value of 192.0.2.2.
meta-data command. The output contains an XML description of all the supported attributes, their purpose and default values.
Example 5.5. Displaying the metadata for the Dummy resource agent template
# export OCF_ROOT=/usr/lib/ocf # $OCF_ROOT/resource.d/pacemaker/Dummy meta-data
<?xml version="1.0"?> <!DOCTYPE resource-agent SYSTEM "ra-api-1.dtd"> <resource-agent name="Dummy" version="1.0"> <version>1.0</version> <longdesc> This is a Dummy Resource Agent. It does absolutely nothing except keep track of whether its running or not. Its purpose in life is for testing and to serve as a template for RA writers. NB: Please pay attention to the timeouts specified in the actions section below. They should be meaningful for the kind of resource the agent manages. They should be the minimum advised timeouts, but they shouldn't/cannot cover _all_ possible resource instances. So, try to be neither overly generous nor too stingy, but moderate. The minimum timeouts should never be below 10 seconds. </longdesc> <shortdesc>Example stateless resource agent</shortdesc> <parameters> <parameter name="state" unique="1"> <longdesc> Location to store the resource state in. </longdesc> <shortdesc>State file</shortdesc> <content type="string" default="/var/run/Dummy-default.state" /> </parameter> <parameter name="fake" unique="0"> <longdesc> Fake attribute that can be changed to cause a reload </longdesc> <shortdesc>Fake attribute that can be changed to cause a reload</shortdesc> <content type="string" default="dummy" /> </parameter> <parameter name="op_sleep" unique="1"> <longdesc> Number of seconds to sleep during operations. This can be used to test how the cluster reacts to operation timeouts. </longdesc> <shortdesc>Operation sleep duration in seconds.</shortdesc> <content type="string" default="0" /> </parameter> </parameters> <actions> <action name="start" timeout="20" /> <action name="stop" timeout="20" /> <action name="monitor" timeout="20" interval="10" depth="0"/> <action name="reload" timeout="20" /> <action name="migrate_to" timeout="20" /> <action name="migrate_from" timeout="20" /> <action name="validate-all" timeout="20" /> <action name="meta-data" timeout="5" /> </actions> </resource-agent>
monitor operation to the resource’s definition.
Example 5.6. An OCF resource with a recurring health check
<primitive id="Public-IP" class="ocf" type="IPaddr" provider="heartbeat"> <operations> <op id="public-ip-check" name="monitor" interval="60s"/> </operations> <instance_attributes id="params-public-ip"> <nvpair id="public-ip-addr" name="ip" value="192.0.2.2"/> </instance_attributes> </primitive>
Table 5.3. Properties of an Operation
| Field | Default | Description |
|---|---|---|
id
|
| |
name
|
| |
interval
|
0
|
How frequently (in seconds) to perform the operation. A value of 0 means never. A positive value defines a recurring action, which is typically used with monitor.
|
timeout
|
| |
on-fail
|
restart (except for stop operations, which default to fence when STONITH is enabled and block otherwise)
|
The action to take if this action ever fails. Allowed values:
|
enabled
|
TRUE
|
If
false, ignore this operation definition. This is typically used to pause a particular recurring monitor operation; for instance, it can complement the respective resource being unmanaged (is-managed=false), as this alone will not block any configured monitoring. Disabling the operation does not suppress all actions of the given type. Allowed values: true, false.
|
record-pending
|
FALSE
| |
role
|
|
Run the operation only on node(s) that the cluster thinks should be in the specified role. This only makes sense for recurring monitor operations. Allowed (case-sensitive) values:
Stopped, Started, and in the case of multi-state resources, Slave and Master.
|
resource-discovery location constraint property.)
target-role property can be used for further checking.
interval=10 role=Started and a second monitor operation with interval=11 role=Stopped, the cluster will run the first monitor on any nodes it thinks should be running the resource, and the second monitor on any nodes that it thinks should not be running the resource (for the truly paranoid, who want to know when an administrator manually starts a service by mistake).
is-managed=false): No monitors will be stopped.
target-role to be set to Stopped then Started to be recovered.
role=Stopped. Monitor operations with role=Stopped will be started on the node if appropriate.
role=Stopped. As with single unmanaged resources, starting a resource on a node other than where the cluster expects it to be will cause problems.
op_defaults section of the CIB’s configuration section, and can be set with crm_attribute. For example,
# crm_attribute --type op_defaults --name timeout --update 20s
timeout to 20 seconds. If an operation’s definition also includes a value for timeout, then that value would be used for that operation instead.
start, stop and a non-recurring monitor operation used at startup to check whether the resource is already active. If one of these is taking too long, then you can create an entry for them and specify a longer timeout.
Example 5.7. An OCF resource with custom timeouts for its implicit actions
<primitive id="Public-IP" class="ocf" type="IPaddr" provider="heartbeat"> <operations> <op id="public-ip-startup" name="monitor" interval="0" timeout="90s"/> <op id="public-ip-start" name="start" interval="0" timeout="180s"/> <op id="public-ip-stop" name="stop" interval="0" timeout="15min"/> </operations> <instance_attributes id="params-public-ip"> <nvpair id="public-ip-addr" name="ip" value="192.0.2.2"/> </instance_attributes> </primitive>
OCF_CHECK_LEVEL for this purpose and dictates that it is "made available to the resource agent without the normal OCF_RESKEY prefix".
instance_attributes block to the op tag. It is up to each resource agent to look for the parameter and decide how to use it.
Example 5.8. An OCF resource with two recurring health checks, performing different levels of checks specified via OCF_CHECK_LEVEL.
<primitive id="Public-IP" class="ocf" type="IPaddr" provider="heartbeat"> <operations> <op id="public-ip-health-60" name="monitor" interval="60"> <instance_attributes id="params-public-ip-depth-60"> <nvpair id="public-ip-depth-60" name="OCF_CHECK_LEVEL" value="10"/> </instance_attributes> </op> <op id="public-ip-health-300" name="monitor" interval="300"> <instance_attributes id="params-public-ip-depth-300"> <nvpair id="public-ip-depth-300" name="OCF_CHECK_LEVEL" value="20"/> </instance_attributes> </op> </operations> <instance_attributes id="params-public-ip"> <nvpair id="public-ip-level" name="ip" value="192.0.2.2"/> </instance_attributes> </primitive>
enabled="false" to the operation’s definition.
Example 5.9. Example of an OCF resource with a disabled health check
<primitive id="Public-IP" class="ocf" type="IPaddr" provider="heartbeat"> <operations> <op id="public-ip-check" name="monitor" interval="60s" enabled="false"/> </operations> <instance_attributes id="params-public-ip"> <nvpair id="public-ip-addr" name="ip" value="192.0.2.2"/> </instance_attributes> </primitive>
# cibadmin --modify --xml-text '<op id="public-ip-check" enabled="false"/>'
# cibadmin --modify --xml-text '<op id="public-ip-check" enabled="true"/>'
ocf-tester script, which can be useful in this regard.
Table of Contents
INFINITY (or equivalently, +INFINITY) internally as a score of 1,000,000. Addition and subtraction with it follow these three basic rules:
INFINITY = INFINITY
INFINITY = -INFINITY
INFINITY - INFINITY = -INFINITY
Note
Table 6.1. Properties of a rsc_location Constraint
| Field | Default | Description |
|---|---|---|
id
|
| |
rsc
|
| |
rsc-pattern
|
|
A regular expression matching the names of resources to which this constraint applies, if
rsc is not specified; if the regular expression contains submatches and the constraint is governed by a rule (see Chapter 8, Rules), the submatches can be referenced as %0 through %9 in the rule’s score-attribute or a rule expression’s attribute (since 1.1.16)
|
node
|
| |
score
|
| |
resource-discovery
|
always
|
Whether Pacemaker should perform resource discovery (that is, check whether the resource is already running) for this resource on this node. This should normally be left as the default, so that rogue instances of a service can be stopped when they are running where they are not supposed to be. However, there are two situations where disabling resource discovery is a good idea: when a service is not installed on a node, discovery might return an error (properly written OCF agents will not, so this is usually only seen with other agent types); and when Pacemaker Remote is used to scale a cluster to hundreds of nodes, limiting resource discovery to allowed nodes can significantly boost performance. (since 1.1.13)
|
Warning
never or exclusive removes Pacemaker’s ability to detect and stop unwanted instances of a service running where it’s not supposed to be. It is up to the system administrator (you!) to make sure that the service can never be active on nodes without resource-discovery (such as by leaving the relevant software uninstalled).
# crm_attribute --name symmetric-cluster --update false
Example 6.1. Opt-in location constraints for two resources
<constraints> <rsc_location id="loc-1" rsc="Webserver" node="sles-1" score="200"/> <rsc_location id="loc-2" rsc="Webserver" node="sles-3" score="0"/> <rsc_location id="loc-3" rsc="Database" node="sles-2" score="200"/> <rsc_location id="loc-4" rsc="Database" node="sles-3" score="0"/> </constraints>
# crm_attribute --name symmetric-cluster --update true
Example 6.2. Opt-out location constraints for two resources
<constraints> <rsc_location id="loc-1" rsc="Webserver" node="sles-1" score="200"/> <rsc_location id="loc-2-dont-run" rsc="Webserver" node="sles-2" score="-INFINITY"/> <rsc_location id="loc-3-dont-run" rsc="Database" node="sles-1" score="-INFINITY"/> <rsc_location id="loc-4" rsc="Database" node="sles-2" score="200"/> </constraints>
Example 6.3. Constraints where a resource prefers two nodes equally
<constraints> <rsc_location id="loc-1" rsc="Webserver" node="sles-1" score="INFINITY"/> <rsc_location id="loc-2" rsc="Webserver" node="sles-2" score="INFINITY"/> <rsc_location id="loc-3" rsc="Database" node="sles-1" score="500"/> <rsc_location id="loc-4" rsc="Database" node="sles-2" score="300"/> <rsc_location id="loc-5" rsc="Database" node="sles-2" score="200"/> </constraints>
Webserver would probably be placed on sles-1 and Database on sles-2. It would likely have placed Webserver based on the node’s uname and Database based on the desire to spread the resource load evenly across the cluster. However other factors can also be involved in more complex configurations.
Important
Table 6.2. Properties of a rsc_order Constraint
| Field | Default | Description |
|---|---|---|
id
|
| |
first
|
| |
then
|
| |
first-action
|
start
| |
then-action
|
value of
first-action
| |
kind
|
|
How to enforce the constraint. Allowed values:
|
symmetrical
|
TRUE
|
Database must start before Webserver, and IP should start before Webserver if they both need to be started:
Example 6.4. Optional and mandatory ordering constraints
<constraints> <rsc_order id="order-1" first="IP" then="Webserver" kind="Optional"/> <rsc_order id="order-2" first="Database" then="Webserver" kind="Mandatory" /> </constraints>
symmetrical default to TRUE, Webserver must be stopped before Database can be stopped, and Webserver should be stopped before IP if they both need to be stopped.
Important
Table 6.3. Properties of a rsc_colocation Constraint
| Field | Default | Description |
|---|---|---|
id
|
| |
rsc
|
| |
with-rsc
|
| |
node-attribute
|
#uname
|
The node attribute that must be the same on the node running
rsc and the node running with-rsc for the constraint to be satisfied. (For details, see Section 6.4.4, “Colocation by Node Attribute”.)
|
score
|
|
+INFINITY or -INFINITY. In such cases, if the constraint can’t be satisfied, then the rsc resource is not permitted to run. For score=INFINITY, this includes cases where the with-rsc resource is not active.
A to always run on the same machine as resource B, you would add the following constraint:
Example 6.5. Mandatory colocation constraint for two resources
<rsc_colocation id="colocate" rsc="A" with-rsc="B" score="INFINITY"/>
INFINITY was used, if B can’t run on any of the cluster nodes (for whatever reason) then A will not be allowed to run. Whether A is running or not has no effect on B.
A cannot run on the same machine as B. In this case, use score="-INFINITY".
Example 6.6. Mandatory anti-colocation constraint for two resources
<rsc_colocation id="anti-colocate" rsc="A" with-rsc="B" score="-INFINITY"/>
-INFINITY, the constraint is binding. So if the only place left to run is where B already is, then A may not run anywhere.
INFINITY, B can run even if A is stopped. However, in this case A also can run if B is stopped, because it still meets the constraint of A and B not running on the same node.
-INFINITY and less than INFINITY, the cluster will try to accommodate your wishes but may ignore them if the alternative is to stop some of the cluster resources.
Example 6.7. Advisory colocation constraint for two resources
<rsc_colocation id="colocate-maybe" rsc="A" with-rsc="B" score="500"/>
node+attribute property of a colocation constraints allows you to express the requirement, "these resources must be on similar nodes".
r1 and r2 such that r2 needs to use the same SAN as r1, but doesn’t necessarily have to be on the same exact node. In such a case, you could define a node attribute named san, with the value san1 or san2 on each node as appropriate. Then, you could colocate r2 with r1 using node-attribute set to san.
Example 6.8. A set of 3 resources
<resource_set id="resource-set-example"> <resource_ref id="A"/> <resource_ref id="B"/> <resource_ref id="C"/> </resource_set>
rsc_location, rsc_order (see Section 6.6, “Ordering Sets of Resources”), rsc_colocation (see Section 6.7, “Colocating Sets of Resources”), and rsc_ticket (see Section 15.3, “Configuring Ticket Dependencies”) constraints.
Table 6.4. Properties of a resource_set
Example 6.9. A chain of ordered resources
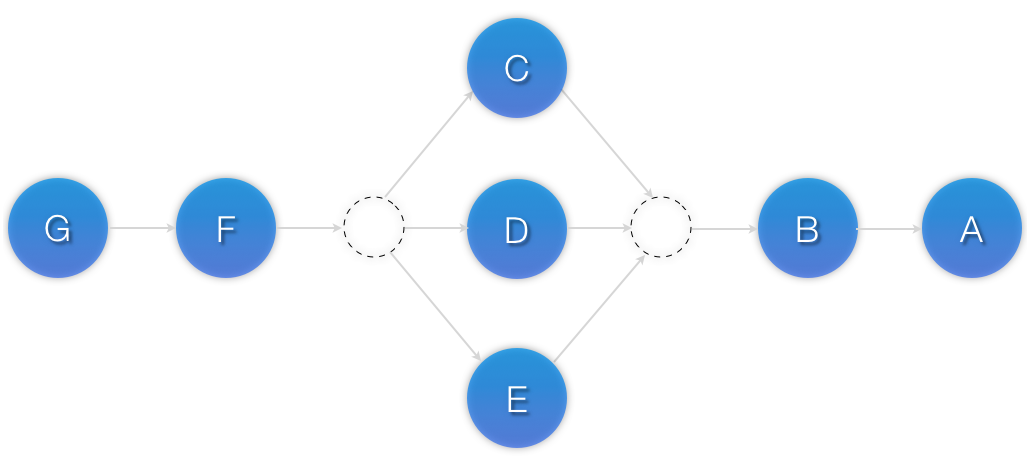
<constraints> <rsc_order id="order-1" first="A" then="B" /> <rsc_order id="order-2" first="B" then="C" /> <rsc_order id="order-3" first="C" then="D" /> </constraints>
Example 6.10. A chain of ordered resources expressed as a set
<constraints> <rsc_order id="order-1"> <resource_set id="ordered-set-example" sequential="true"> <resource_ref id="A"/> <resource_ref id="B"/> <resource_ref id="C"/> <resource_ref id="D"/> </resource_set> </rsc_order> </constraints>
Important
A B may be equivalent to A then B, or B then A.
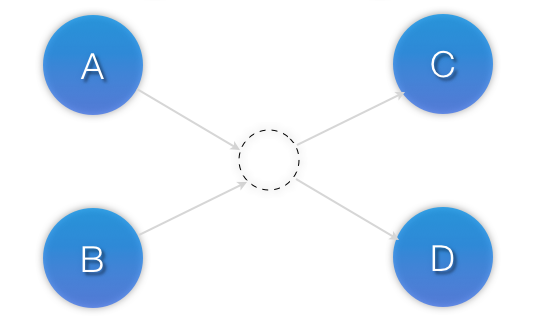
sequential property). In the example below, A and B can both start in parallel, as can C and D, however C and D can only start once both A and B are active.
Example 6.11. Ordered sets of unordered resources
<constraints> <rsc_order id="order-1"> <resource_set id="ordered-set-1" sequential="false"> <resource_ref id="A"/> <resource_ref id="B"/> </resource_set> <resource_set id="ordered-set-2" sequential="false"> <resource_ref id="C"/> <resource_ref id="D"/> </resource_set> </rsc_order> </constraints>
sequential="true") and there is no limit to the number of sets that can be specified.
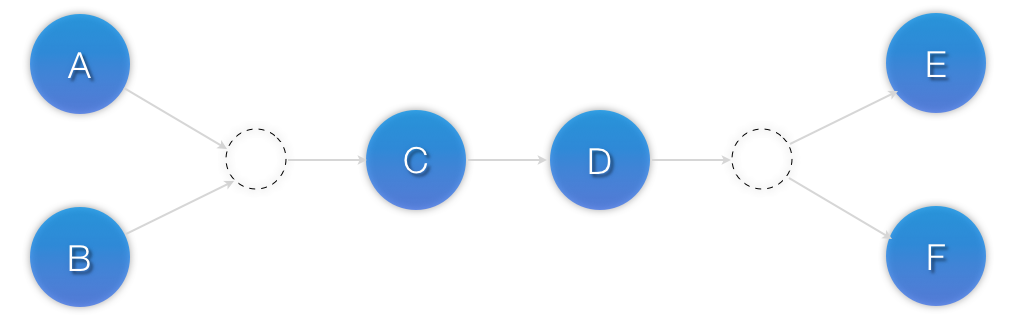
Example 6.12. Advanced use of set ordering - Three ordered sets, two of which are internally unordered
<constraints> <rsc_order id="order-1"> <resource_set id="ordered-set-1" sequential="false"> <resource_ref id="A"/> <resource_ref id="B"/> </resource_set> <resource_set id="ordered-set-2" sequential="true"> <resource_ref id="C"/> <resource_ref id="D"/> </resource_set> <resource_set id="ordered-set-3" sequential="false"> <resource_ref id="E"/> <resource_ref id="F"/> </resource_set> </rsc_order> </constraints>
Important
sequential=false makes sense only if there is another set in the constraint. Otherwise, the constraint has no effect.
(A and B) then (C) then (D) then (E and F).
(A and B), to use "OR" logic so the sets look like this: (A or B) then (C) then (D) then (E and F). This functionality can be achieved through the use of the require-all option. This option defaults to TRUE which is why the "AND" logic is used by default. Setting require-all=false means only one resource in the set needs to be started before continuing on to the next set.
Example 6.13. Resource Set "OR" logic: Three ordered sets, where the first set is internally unordered with "OR" logic
<constraints> <rsc_order id="order-1"> <resource_set id="ordered-set-1" sequential="false" require-all="false"> <resource_ref id="A"/> <resource_ref id="B"/> </resource_set> <resource_set id="ordered-set-2" sequential="true"> <resource_ref id="C"/> <resource_ref id="D"/> </resource_set> <resource_set id="ordered-set-3" sequential="false"> <resource_ref id="E"/> <resource_ref id="F"/> </resource_set> </rsc_order> </constraints>
Important
require-all=false makes sense only in conjunction with sequential=false. Think of it like this: sequential=false modifies the set to be an unordered set using "AND" logic by default, and adding require-all=false flips the unordered set’s "AND" logic to "OR" logic.
Example 6.14. Chain of colocated resources
<constraints> <rsc_colocation id="coloc-1" rsc="D" with-rsc="C" score="INFINITY"/> <rsc_colocation id="coloc-2" rsc="C" with-rsc="B" score="INFINITY"/> <rsc_colocation id="coloc-3" rsc="B" with-rsc="A" score="INFINITY"/> </constraints>
B is not able to run, then both C and by inference D must also remain stopped. Here is an example resource_set:
Example 6.15. Equivalent colocation chain expressed using resource_set
<constraints> <rsc_colocation id="coloc-1" score="INFINITY" > <resource_set id="colocated-set-example" sequential="true"> <resource_ref id="A"/> <resource_ref id="B"/> <resource_ref id="C"/> <resource_ref id="D"/> </resource_set> </rsc_colocation> </constraints>
Important
A B may be equivalent to A with B, or B with A.
sequential property).
A, B, and C will each be colocated with D. D must be active, but any of A, B, or C may be inactive without affecting any other resources.
Example 6.16. Using colocated sets to specify a common peer
<constraints> <rsc_colocation id="coloc-1" score="INFINITY" > <resource_set id="colocated-set-1" sequential="false"> <resource_ref id="A"/> <resource_ref id="B"/> <resource_ref id="C"/> </resource_set> <resource_set id="colocated-set-2" sequential="true"> <resource_ref id="D"/> </resource_set> </rsc_colocation> </constraints>
Important
sequential=false makes sense only if there is another set in the constraint. Otherwise, the constraint has no effect.
sequential="true", then in order for one member of that set to be active, all members listed before it must also be active.
role property.
Example 6.17. Colocation chain in which the members of the middle set have no interdependencies, and the last listed set (which the cluster places first) is restricted to instances in master status.
<constraints> <rsc_colocation id="coloc-1" score="INFINITY" > <resource_set id="colocated-set-1" sequential="true"> <resource_ref id="B"/> <resource_ref id="A"/> </resource_set> <resource_set id="colocated-set-2" sequential="false"> <resource_ref id="C"/> <resource_ref id="D"/> <resource_ref id="E"/> </resource_set> <resource_set id="colocated-set-3" sequential="true" role="Master"> <resource_ref id="G"/> <resource_ref id="F"/> </resource_set> </rsc_colocation> </constraints>
Note
B is colocated with A, but colocated-set-1 is colocated with colocated-set-2.
require-all option.
Table of Contents
Example 7.1. Simple alert configuration
<configuration> <alerts> <alert id="my-alert" path="/path/to/my-script.sh" /> </alerts> </configuration>
my-script.sh for each event.
Example 7.2. Alert configuration with recipient
<configuration> <alerts> <alert id="my-alert" path="/path/to/my-script.sh"> <recipient id="my-alert-recipient" value="some-address"/> </alert> </alerts> </configuration>
my-script.sh for each event, passing the recipient some-address as an environment variable.
Example 7.3. Alert configuration with meta-attributes
<configuration> <alerts> <alert id="my-alert" path="/path/to/my-script.sh"> <meta_attributes id="my-alert-attributes"> <nvpair id="my-alert-attributes-timeout" name="timeout" value="15s"/> </meta_attributes> <recipient id="my-alert-recipient1" value="someuser@example.com"> <meta_attributes id="my-alert-recipient1-attributes"> <nvpair id="my-alert-recipient1-timestamp-format" name="timestamp-format" value="%D %H:%M"/> </meta_attributes> </recipient> <recipient id="my-alert-recipient2" value="otheruser@example.com"> <meta_attributes id="my-alert-recipient2-attributes"> <nvpair id="my-alert-recipient2-timestamp-format" name="timestamp-format" value="%c"/> </meta_attributes> </recipient> </alert> </alerts> </configuration>
my-script.sh will get called twice for each event, with each call using a 15-second timeout. One call will be passed the recipient someuser@example.com and a timestamp in the format %D %H:%M, while the other call will be passed the recipient otheruser@example.com and a timestamp in the format %c.
Example 7.4. Alert configuration with instance attributes
<configuration> <alerts> <alert id="my-alert" path="/path/to/my-script.sh"> <meta_attributes id="my-alert-attributes"> <nvpair id="my-alert-attributes-timeout" name="timeout" value="15s"/> </meta_attributes> <instance_attributes id="my-alert-options"> <nvpair id="my-alert-options-debug" name="debug" value="false"/> </instance_attributes> <recipient id="my-alert-recipient1" value="someuser@example.com"/> </alert> </alerts> </configuration>
Example 7.5. Alert configuration to receive only node events and fencing events
<configuration> <alerts> <alert id="my-alert" path="/path/to/my-script.sh"> <select> <select_nodes /> <select_fencing /> </select> <recipient id="my-alert-recipient1" value="someuser@example.com"/> </alert> </alerts> </configuration>
<select> are <select_nodes>, <select_fencing>, <select_resources>, and <select_attributes>.
<select_attributes> (the only event type not enabled by default), the agent will receive alerts when a node attribute changes. If you wish the agent to be called only when certain attributes change, you can configure that as well.
Example 7.6. Alert configuration to be called when certain node attributes change
<configuration> <alerts> <alert id="my-alert" path="/path/to/my-script.sh"> <select> <select_attributes> <attribute id="alert-standby" name="standby" /> <attribute id="alert-shutdown" name="shutdown" /> </select_attributes> </select> <recipient id="my-alert-recipient1" value="someuser@example.com"/> </alert> </alerts> </configuration>
/usr/share/pacemaker/alerts by default.
Example 7.7. Sending cluster events as SNMP traps
<configuration> <alerts> <alert id="snmp_alert" path="/path/to/alert_snmp.sh"> <instance_attributes id="config_for_alert_snmp"> <nvpair id="trap_node_states" name="trap_node_states" value="all"/> </instance_attributes> <meta_attributes id="config_for_timestamp"> <nvpair id="ts_fmt" name="timestamp-format" value="%Y-%m-%d,%H:%M:%S.%01N"/> </meta_attributes> <recipient id="snmp_destination" value="192.168.1.2"/> </alert> </alerts> </configuration>
Example 7.8. Sending cluster events as e-mails
<configuration> <alerts> <alert id="smtp_alert" path="/path/to/alert_smtp.sh"> <instance_attributes id="config_for_alert_smtp"> <nvpair id="email_sender" name="email_sender" value="donotreply@example.com"/> </instance_attributes> <recipient id="smtp_destination" value="admin@example.com"/> </alert> </alerts> </configuration>
Table 7.2. Environment variables passed to alert agents
hacluster user, which has a minimal set of permissions. If an agent requires additional privileges, it is recommended to configure sudo to allow the agent to run the necessary commands as another user with the appropriate privileges.
Note
ocf:pacemaker:ClusterMon resource, which is now deprecated. To preserve this compatibility, the environment variables passed to alert agents are available prepended with CRM_notify_ as well as CRM_alert_. One break in compatibility is that ClusterMon ran external scripts as the root user, while alert agents are run as the hacluster user.
Table of Contents
resource-stickiness during working hours, to prevent resources from being moved back to their most preferred location, and another on weekends when no-one is around to notice an outage.
boolean-op field to determine if the rule ultimately evaluates to true or false. What happens next depends on the context in which the rule is being used.
Table 8.1. Properties of a Rule
| Field | Default | Description |
|---|---|---|
id
|
| |
role
|
Started
| |
score
|
| |
score-attribute
|
| |
boolean-op
|
and
|
Table 8.2. Properties of an Expression
| Field | Default | Description |
|---|---|---|
id
|
| |
attribute
|
| |
type
|
string
| |
operation
|
|
The comparison to perform (required). Allowed values:
|
value
|
| |
value-source
|
literal
|
How the
value is derived (since 1.1.17). Allowed values:
|
Table 8.3. Built-in node attributes
| Name | Value |
|---|---|
#uname
|
Node name
|
#id
|
Node ID
|
#kind
|
Node type. Possible values are
cluster, remote, and container. Kind is remote for Pacemaker Remote nodes created with the ocf:pacemaker:remote resource, and container for Pacemaker Remote guest nodes and bundle nodes (since 1.1.13)
|
#is_dc
|
"true" if this node is a Designated Controller (DC), "false" otherwise
|
#cluster-name
|
The value of the
cluster-name cluster property, if set
|
#site-name
|
The value of the
site-name cluster property, if set, otherwise identical to #cluster-name
|
#role
|
The role the relevant multistate resource has on this node. Valid only within a rule for a location constraint for a multistate resource.
|
date_expressions are used to control a resource or cluster option based on the current date/time. They may contain an optional date_spec and/or duration object depending on the context.
Table 8.4. Properties of a Date Expression
| Field | Description |
|---|---|
start
| |
end
|
A date/time conforming to the ISO8601 specification. Can be inferred by supplying a value for
start and a duration.
|
operation
|
Compares the current date/time with the start and/or end date, depending on the context. Allowed values:
|
Note
date_spec) include the time, the eq, neq, gte and lte operators have not been implemented since they would only be valid for a single second.
date_spec objects are used to create cron-like expressions relating to time. Each field can contain a single number or a single range. Instead of defaulting to zero, any field not supplied is ignored.
monthdays="1" matches the first day of every month and hours="09-17" matches the hours between 9am and 5pm (inclusive). At this time, multiple ranges (e.g. weekdays="1,2" or weekdays="1-2,5-6") are not supported; depending on demand, this might be implemented in a future release.
Table 8.5. Properties of a Date Specification
| Field | Description |
|---|---|
id
| |
hours
| |
monthdays
| |
weekdays
| |
yeardays
| |
months
| |
weeks
| |
years
| |
weekyears
| |
moon
|
end when one is not supplied to in_range operations. They contain the same fields as date_spec objects but without the limitations (e.g. you can have a duration of 19 months). As with date_specs, any field not supplied is ignored.
Example 8.1. True if now is any time in the year 2005
<rule id="rule1"> <date_expression id="date_expr1" start="2005-001" operation="in_range"> <duration years="1"/> </date_expression> </rule>
Example 8.2. Equivalent expression
<rule id="rule2"> <date_expression id="date_expr2" operation="date_spec"> <date_spec years="2005"/> </date_expression> </rule>
Example 8.3. 9am-5pm Monday-Friday
<rule id="rule3"> <date_expression id="date_expr3" operation="date_spec"> <date_spec hours="9-16" days="1-5"/> </date_expression> </rule>
16 matches up to 16:59:59, as the numeric value (hour) still matches!
Example 8.4. 9am-6pm Monday through Friday or anytime Saturday
<rule id="rule4" boolean-op="or"> <date_expression id="date_expr4-1" operation="date_spec"> <date_spec hours="9-16" days="1-5"/> </date_expression> <date_expression id="date_expr4-2" operation="date_spec"> <date_spec days="6"/> </date_expression> </rule>
Example 8.5. 9am-5pm or 9pm-12am Monday through Friday
<rule id="rule5" boolean-op="and"> <rule id="rule5-nested1" boolean-op="or"> <date_expression id="date_expr5-1" operation="date_spec"> <date_spec hours="9-16"/> </date_expression> <date_expression id="date_expr5-2" operation="date_spec"> <date_spec hours="21-23"/> </date_expression> </rule> <date_expression id="date_expr5-3" operation="date_spec"> <date_spec days="1-5"/> </date_expression> </rule>
Example 8.6. Mondays in March 2005
<rule id="rule6" boolean-op="and"> <date_expression id="date_expr6-1" operation="date_spec"> <date_spec weekdays="1"/> </date_expression> <date_expression id="date_expr6-2" operation="in_range" start="2005-03-01" end="2005-04-01"/> </rule>
Note
end="2005-03-31T23:59:59" to avoid confusion.
Example 8.7. A full moon on Friday the 13th
<rule id="rule7" boolean-op="and"> <date_expression id="date_expr7" operation="date_spec"> <date_spec weekdays="5" monthdays="13" moon="4"/> </date_expression> </rule>
false, the cluster treats the constraint as if it were not there. When the rule evaluates to true, the node’s preference for running the resource is updated with the score associated with the rule.
Example 8.8. Prevent myApacheRsc from running on c001n03
<rsc_location id="dont-run-apache-on-c001n03" rsc="myApacheRsc" score="-INFINITY" node="c001n03"/>
Example 8.9. Prevent myApacheRsc from running on c001n03 - expanded version
<rsc_location id="dont-run-apache-on-c001n03" rsc="myApacheRsc"> <rule id="dont-run-apache-rule" score="-INFINITY"> <expression id="dont-run-apache-expr" attribute="#uname" operation="eq" value="c00n03"/> </rule> </rsc_location>
Example 8.10. A sample nodes section for use with score-attribute
<nodes> <node id="uuid1" uname="c001n01" type="normal"> <instance_attributes id="uuid1-custom_attrs"> <nvpair id="uuid1-cpu_mips" name="cpu_mips" value="1234"/> </instance_attributes> </node> <node id="uuid2" uname="c001n02" type="normal"> <instance_attributes id="uuid2-custom_attrs"> <nvpair id="uuid2-cpu_mips" name="cpu_mips" value="5678"/> </instance_attributes> </node> </nodes>
<rule id="need-more-power-rule" score="-INFINITY"> <expression id="need-more-power-expr" attribute="cpu_mips" operation="lt" value="3000"/> </rule>
score-attribute instead of score, each node matched by the rule has its score adjusted differently, according to its value for the named node attribute. Thus, in the previous example, if a rule used score-attribute="cpu_mips", c001n01 would have its preference to run the resource increased by 1234 whereas c001n02 would have its preference increased by 5678.
instance_attributes objects for the resource and adding a rule to each, we can easily handle these special cases.
mySpecialRsc will use eth1 and port 9999 when run on node1, eth2 and port 8888 on node2 and default to eth0 and port 9999 for all other nodes.
Example 8.11. Defining different resource options based on the node name
<primitive id="mySpecialRsc" class="ocf" type="Special" provider="me"> <instance_attributes id="special-node1" score="3"> <rule id="node1-special-case" score="INFINITY" > <expression id="node1-special-case-expr" attribute="#uname" operation="eq" value="node1"/> </rule> <nvpair id="node1-interface" name="interface" value="eth1"/> </instance_attributes> <instance_attributes id="special-node2" score="2" > <rule id="node2-special-case" score="INFINITY"> <expression id="node2-special-case-expr" attribute="#uname" operation="eq" value="node2"/> </rule> <nvpair id="node2-interface" name="interface" value="eth2"/> <nvpair id="node2-port" name="port" value="8888"/> </instance_attributes> <instance_attributes id="defaults" score="1" > <nvpair id="default-interface" name="interface" value="eth0"/> <nvpair id="default-port" name="port" value="9999"/> </instance_attributes> </primitive>
instance_attributes objects are evaluated is determined by their score (highest to lowest). If not supplied, score defaults to zero, and objects with an equal score are processed in listed order. If the instance_attributes object has no rule or a rule that evaluates to true, then for any parameter the resource does not yet have a value for, the resource will use the parameter values defined by the instance_attributes.
special-node1 has the highest score (3) and so is evaluated first; its rule evaluates to true, so interface is set to eth1.
special-node2 is evaluated next with score 2, but its rule evaluates to false, so it is ignored.
defaults is evaluated last with score 1, and has no rule, so its values are examined; interface is already defined, so the value here is not used, but port is not yet defined, so port is set to 9999.
resource-stickiness value during and outside work hours. This allows resources to automatically move back to their most preferred hosts, but at a time that (in theory) does not interfere with business activities.
Example 8.12. Change resource-stickiness during working hours
<rsc_defaults> <meta_attributes id="core-hours" score="2"> <rule id="core-hour-rule" score="0"> <date_expression id="nine-to-five-Mon-to-Fri" operation="date_spec"> <date_spec id="nine-to-five-Mon-to-Fri-spec" hours="9-16" weekdays="1-5"/> </date_expression> </rule> <nvpair id="core-stickiness" name="resource-stickiness" value="INFINITY"/> </meta_attributes> <meta_attributes id="after-hours" score="1" > <nvpair id="after-stickiness" name="resource-stickiness" value="0"/> </meta_attributes> </rsc_defaults>
cluster-recheck-interval cluster option (which defaults to 15 minutes) is essential. This tells the cluster to periodically recalculate the ideal state of the cluster.
cluster-recheck-interval="5m", then sometime between 09:00 and 09:05 the cluster would notice that it needs to start resource X, and between 17:00 and 17:05 it would realize that X needed to be stopped. The timing of the actual start and stop actions depends on what other actions the cluster may need to perform first.
Table of Contents
Table 9.1. Environment Variables Used to Connect to Remote Instances of the CIB
| Environment Variable | Default | Description |
|---|---|---|
CIB_user
|
$USER
| |
CIB_passwd
|
| |
CIB_server
|
localhost
| |
CIB_port
|
| |
CIB_encrypted
|
TRUE
|
# export CIB_port=1234; export CIB_server=c001n01; export CIB_user=someuser; # cibadmin -Q
remote-tls-port (encrypted) or remote-clear-port (unencrypted) CIB properties (i.e., those kept in the cib tag, like num_updates and epoch).
interval-origin. The cluster uses this point to calculate the correct start-delay such that the operation will occur at origin + (interval * N).
interval and interval-origin can be any date/time conforming to the ISO8601 standard. By way of example, to specify an operation that would run on the first Monday of 2009 and every Monday after that, you would add:
Example 9.1. Specifying a Base for Recurring Action Intervals
<op id="my-weekly-action" name="custom-action" interval="P7D" interval-origin="2009-W01-1"/>
crm_failcount command. For example, to see how many times the 10-second monitor for myrsc has failed on node1, run:
# crm_failcount --query -r myrsc -N node1 -n monitor -I 10s
crm_failcount will use the local node. If you omit the operation and interval, crm_failcount will display the sum of the fail counts for all operations on the resource.
crm_resource --cleanup or crm_failcount --delete to clear fail counts. For example, to clear the above monitor failures, run:
# crm_resource --cleanup -r myrsc -N node1 -n monitor -I 10s
crm_resource --cleanup will clear failures for all resources. If you omit the node, it will clear failures on all nodes. If you omit the operation and interval, it will clear the failures for all operations on the resource.
Note
crm_mon tool shows the current cluster status, including any failed operations. To see the current fail counts for any failed resources, call crm_mon with the --failcounts option. This shows the fail counts per resource (that is, the sum of any operation fail counts for the resource).
migration-threshold resource meta-attribute. [16]
migration-threshold=N for a resource, it will be banned from the original node after N failures.
Note
migration-threshold is per resource, even though fail counts are tracked per operation. The operation fail counts are added together to compare against the migration-threshold.
crm_resource --cleanup or crm_failcount --delete (hopefully after first fixing the failure’s cause). It is possible to have fail counts expire automatically by setting the failure-timeout resource meta-attribute.
Important
migration-threshold=2 and failure-timeout=60s would cause the resource to move to a new node after 2 failures, and allow it to move back (depending on stickiness and constraint scores) after one minute.
Note
failure-timeout is measured since the most recent failure. That is, older failures do not individually time out and lower the fail count. Instead, all failures are timed out simultaneously (and the fail count is reset to 0) if there is no new failure for the timeout period.
start-failure-is-fatal is set to true (which is the default), start failures cause the fail count to be set to INFINITY and thus always cause the resource to move immediately.
Important
failure-timeout.
crm_standby. To check the standby status of the current machine, run:
# crm_standby -G
on indicates that the node is not able to host any resources, while a value of off says that it can.
--node option:
# crm_standby -G --node sles-2
-v instead of -G:
# crm_standby -v on
--node.
crm_resource command, which creates and modifies the extra constraints for you. If Email were running on sles-1 and you wanted it moved to a specific location, the command would look something like:
# crm_resource -M -r Email -H sles-2
<rsc_location rsc="Email" node="sles-2" score="INFINITY"/>
crm_resource -M are not cumulative. So, if you ran these commands
# crm_resource -M -r Email -H sles-2 # crm_resource -M -r Email -H sles-3
# crm_resource -U -r Email
resource-stickiness, it might stay where it is. To be absolutely certain that it moves back to sles-1, move it there before issuing the call to crm_resource -U:
# crm_resource -M -r Email -H sles-1 # crm_resource -U -r Email
# crm_resource -B -r Email
<rsc_location rsc="Email" node="sles-1" score="-INFINITY"/>
-INFINITY constraint will prevent the resource from running on that node until crm_resource -U is used. This includes the situation where every other cluster node is no longer available!
resource-stickiness is set to INFINITY, it is possible that you will end up with the problem described in Section 6.2.4, “What if Two Nodes Have the Same Score”. The tool can detect some of these cases and deals with them by creating both positive and negative constraints. E.g.
Email prefers sles-1 with a score of -INFINITY
Email prefers sles-2 with a score of INFINITY
pingd by default. [17]
Note
ha.cf, but this is no longer required.
Example 9.2. An example ping cluster resource that checks node connectivity once every minute
<clone id="Connected"> <primitive id="ping" provider="pacemaker" class="ocf" type="ping"> <instance_attributes id="ping-attrs"> <nvpair id="pingd-dampen" name="dampen" value="5s"/> <nvpair id="pingd-multiplier" name="multiplier" value="1000"/> <nvpair id="pingd-hosts" name="host_list" value="my.gateway.com www.bigcorp.com"/> </instance_attributes> <operations> <op id="ping-monitor-60s" interval="60s" name="monitor"/> </operations> </primitive> </clone>
Important
ocf:pacemaker:ping is recording.
Important
Example 9.3. Don’t run a resource on unconnected nodes
<rsc_location id="WebServer-no-connectivity" rsc="Webserver"> <rule id="ping-exclude-rule" score="-INFINITY" > <expression id="ping-exclude" attribute="pingd" operation="not_defined"/> </rule> </rsc_location>
Example 9.4. Run only on nodes connected to three or more ping targets.
<primitive id="ping" provider="pacemaker" class="ocf" type="ping"> ... <!-- omitting some configuration to highlight important parts --> <nvpair id="pingd-multiplier" name="multiplier" value="1000"/> ... </primitive> ... <rsc_location id="WebServer-connectivity" rsc="Webserver"> <rule id="ping-prefer-rule" score="-INFINITY" > <expression id="ping-prefer" attribute="pingd" operation="lt" value="3000"/> </rule> </rsc_location>
multiplier to a value higher than that of resource-stickiness (and don’t set either of them to INFINITY).
Example 9.5. Prefer the node with the most connected ping nodes
<rsc_location id="WebServer-connectivity" rsc="Webserver"> <rule id="ping-prefer-rule" score-attribute="pingd" > <expression id="ping-prefer" attribute="pingd" operation="defined"/> </rule> </rsc_location>
Example 9.6. How the cluster translates the above location constraint
<rsc_location id="ping-1" rsc="Webserver" node="sles-1" score="5000"/> <rsc_location id="ping-2" rsc="Webserver" node="sles-2" score="2000"/>
multiplier is set to 1000).
Example 9.7. A more complex example of choosing a location based on connectivity
<rsc_location id="WebServer-connectivity" rsc="Webserver"> <rule id="ping-exclude-rule" score="-INFINITY" > <expression id="ping-exclude" attribute="pingd" operation="lt" value="3000"/> </rule> <rule id="ping-prefer-rule" score-attribute="pingd" > <expression id="ping-prefer" attribute="pingd" operation="defined"/> </rule> </rsc_location>
migrate_to (performed on the current location) and migrate_from (performed on the destination).
migrate_to action and, if anything, the activation would occur during migrate_from.
migrate_to action is practically empty and migrate_from does most of the work, extracting the relevant resource state from the old location and activating it.
Migration Checklist
migrate_to and migrate_from actions, and advertise them in its metadata.
allow-migrate meta-attribute set to true (which is not the default).
#health as an indicator of node health. Node health attributes may have one of the following values:
node-health-strategy cluster option controls how Pacemaker responds to changes in node health attributes, and how it translates red, yellow, and green to scores.
Table 9.5. Node Health Strategies
| Value | Effect |
|---|---|
none
| |
migrate-on-red
| |
only-green
| |
progressive
|
Assign the value of the
node-health-red cluster option to red, the value of node-health-yellow to yellow, and the value of node-health-green to green. Each node is additionally assigned a score of node-health-base (this allows resources to start even if some attributes are yellow). This strategy gives the administrator finer control over how important each value is.
|
custom
|
Track node health attributes using the same values as
progressive for red, yellow, and green, but do not take them into account. The administrator is expected to implement a policy by defining rules (see Chapter 8, Rules) referencing node health attributes.
|
ocf:pacemaker:HealthCPU and ocf:pacemaker:HealthSMART resource agents set node health attributes based on CPU and disk parameters. The ipmiservicelogd daemon sets node health attributes based on IPMI values (the ocf:pacemaker:SystemHealth resource agent can be used to manage the daemon as a cluster resource).
reload operation and perform any required actions. The actions here depend completely on your application!
Example 9.8. The DRBD agent’s logic for supporting reload
case $1 in start) drbd_start ;; stop) drbd_stop ;; reload) drbd_reload ;; monitor) drbd_monitor ;; *) drbd_usage exit $OCF_ERR_UNIMPLEMENTED ;; esac exit $?
reload operation in the actions section of its metadata
Example 9.9. The DRBD Agent Advertising Support for the reload Operation
<?xml version="1.0"?> <!DOCTYPE resource-agent SYSTEM "ra-api-1.dtd"> <resource-agent name="drbd"> <version>1.1</version> <longdesc> Master/Slave OCF Resource Agent for DRBD </longdesc> ... <actions> <action name="start" timeout="240" /> <action name="reload" timeout="240" /> <action name="promote" timeout="90" /> <action name="demote" timeout="90" /> <action name="notify" timeout="90" /> <action name="stop" timeout="100" /> <action name="meta-data" timeout="5" /> <action name="validate-all" timeout="30" /> </actions> </resource-agent>
reload.
unique set to 0 is eligible to be used in this way.
Example 9.10. Parameter that can be changed using reload
<parameter name="drbdconf" unique="0"> <longdesc>Full path to the drbd.conf file.</longdesc> <shortdesc>Path to drbd.conf</shortdesc> <content type="string" default="${OCF_RESKEY_drbdconf_default}"/> </parameter>
Note
unique=0.
Note
Table of Contents
Example 10.1. A group of two primitive resources
<group id="shortcut"> <primitive id="Public-IP" class="ocf" type="IPaddr" provider="heartbeat"> <instance_attributes id="params-public-ip"> <nvpair id="public-ip-addr" name="ip" value="192.0.2.2"/> </instance_attributes> </primitive> <primitive id="Email" class="lsb" type="exim"/> </group>
Public-IP first, then Email)
Email first, then Public-IP)
Public-IP can’t run anywhere, neither can Email;
Email can’t run anywhere, this does not affect Public-IP in any way
Example 10.2. How the cluster sees a group resource
<configuration> <resources> <primitive id="Public-IP" class="ocf" type="IPaddr" provider="heartbeat"> <instance_attributes id="params-public-ip"> <nvpair id="public-ip-addr" name="ip" value="192.0.2.2"/> </instance_attributes> </primitive> <primitive id="Email" class="lsb" type="exim"/> </resources> <constraints> <rsc_colocation id="xxx" rsc="Email" with-rsc="Public-IP" score="INFINITY"/> <rsc_order id="yyy" first="Public-IP" then="Email"/> </constraints> </configuration>
priority, target-role, and is-managed properties from primitive resources. See Section 5.4, “Resource Options” for information about those properties.
id instead of the group’s.
Example 10.3. Some constraints involving groups
<constraints> <rsc_location id="group-prefers-node1" rsc="shortcut" node="node1" score="500"/> <rsc_colocation id="webserver-with-group" rsc="Webserver" with-rsc="shortcut"/> <rsc_order id="start-group-then-webserver" first="Webserver" then="shortcut"/> </constraints>
resource-stickiness is 100, and a group has seven members, five of which are active, then the group as a whole will prefer its current location with a score of 500.
Example 10.4. A clone of an LSB resource
<clone id="apache-clone"> <meta_attributes id="apache-clone-meta"> <nvpair id="apache-unique" name="globally-unique" value="false"/> </meta_attributes> <primitive id="apache" class="lsb" type="apache"/> </clone>
priority, target-role, is-managed
Table 10.3. Clone-specific configuration options
| Field | Default | Description |
|---|---|---|
clone-max
|
number of nodes in cluster
| |
clone-node-max
|
1
| |
clone-min
|
1
| |
notify
|
true
| |
globally-unique
|
false
| |
ordered
|
false
| |
interleave
|
false
|
Warning
id is used.
Example 10.5. Some constraints involving clones
<constraints> <rsc_location id="clone-prefers-node1" rsc="apache-clone" node="node1" score="500"/> <rsc_colocation id="stats-with-clone" rsc="apache-stats" with="apache-clone"/> <rsc_order id="start-clone-then-stats" first="apache-clone" then="apache-stats"/> </constraints>
apache-stats will wait until all copies of apache-clone that need to be started have done so before being started itself. Only if no copies can be started will apache-stats be prevented from being active. Additionally, the clone will wait for apache-stats to be stopped before stopping itself.
A is colocated with another clone B, the set of allowed locations for A is limited to nodes on which B is (or will be) active. Placement is then performed normally.
resource-stickiness is provided, the clone will use a value of 1. Being a small value, it causes minimal disturbance to the score calculations of other resources but is enough to prevent Pacemaker from needlessly moving copies around the cluster.
Note
resource-stickiness of 0 for the clone temporarily and let the cluster adjust, then set it back to 1 if you want the default behavior to apply again.
${OCF_SUCCESS} if the node has that exact instance active. All other probes for instances of the clone should result in ${OCF_NOT_RUNNING} (or one of the other OCF error codes if they are failed).
apache:2.
OCF_RESKEY_CRM_meta_clone_max environment variable and which copy it is by examining OCF_RESKEY_CRM_meta_clone.
OCF_RESKEY_CRM_meta_clone) about which numerical instances are active. In particular, the list of active copies will not always be an unbroken sequence, nor always start at 0.
notify action to be implemented. If supported, the notify action will be passed a number of extra variables which, when combined with additional context, can be used to calculate the current state of the cluster and what is about to happen to it.
Table 10.4. Environment variables supplied with Clone notify actions
| Variable | Description |
|---|---|
|
OCF_RESKEY_CRM_meta_notify_type
| |
|
OCF_RESKEY_CRM_meta_notify_operation
| |
|
OCF_RESKEY_CRM_meta_notify_start_resource
| |
|
OCF_RESKEY_CRM_meta_notify_stop_resource
| |
|
OCF_RESKEY_CRM_meta_notify_active_resource
| |
|
OCF_RESKEY_CRM_meta_notify_inactive_resource
| |
|
OCF_RESKEY_CRM_meta_notify_start_uname
| |
|
OCF_RESKEY_CRM_meta_notify_stop_uname
| |
|
OCF_RESKEY_CRM_meta_notify_active_uname
|
OCF_RESKEY_CRM_meta_notify_start_resource and OCF_RESKEY_CRM_meta_notify_start_uname and should be treated as an array of whitespace-separated elements.
OCF_RESKEY_CRM_meta_notify_inactive_resource is an exception as the matching uname variable does not exist since inactive resources are not running on any node.
clone:0 will be started on sles-1, clone:2 will be started on sles-3, and clone:3 will be started on sles-2, the cluster would set
Example 10.6. Notification variables
OCF_RESKEY_CRM_meta_notify_start_resource="clone:0 clone:2 clone:3" OCF_RESKEY_CRM_meta_notify_start_uname="sles-1 sles-3 sles-2"
Pre-notification (stop):
$OCF_RESKEY_CRM_meta_notify_active_resource
$OCF_RESKEY_CRM_meta_notify_inactive_resource
$OCF_RESKEY_CRM_meta_notify_start_resource
$OCF_RESKEY_CRM_meta_notify_stop_resource
Post-notification (stop) / Pre-notification (start):
$OCF_RESKEY_CRM_meta_notify_active_resource
$OCF_RESKEY_CRM_meta_notify_stop_resource
$OCF_RESKEY_CRM_meta_notify_inactive_resource
$OCF_RESKEY_CRM_meta_notify_stop_resource
$OCF_RESKEY_CRM_meta_notify_start_resource
$OCF_RESKEY_CRM_meta_notify_stop_resource
Post-notification (start):
$OCF_RESKEY_CRM_meta_notify_active_resource
$OCF_RESKEY_CRM_meta_notify_stop_resource
$OCF_RESKEY_CRM_meta_notify_start_resource
$OCF_RESKEY_CRM_meta_notify_inactive_resource
$OCF_RESKEY_CRM_meta_notify_stop_resource
$OCF_RESKEY_CRM_meta_notify_start_resource
$OCF_RESKEY_CRM_meta_notify_start_resource
$OCF_RESKEY_CRM_meta_notify_stop_resource
clone-max, clone-node-max, notify, globally-unique, ordered, interleave
Warning
role="master" will cover the master role.
Example 10.7. Monitoring both states of a multi-state resource
<master id="myMasterRsc"> <primitive id="myRsc" class="ocf" type="myApp" provider="myCorp"> <operations> <op id="public-ip-slave-check" name="monitor" interval="60"/> <op id="public-ip-master-check" name="monitor" interval="61" role="Master"/> </operations> </primitive> </master>
Important
id is used.
first-action and/or then-action fields for ordering constraints may be set to promote or demote to constrain the master role, and colocation constraints may contain rsc-role and/or with-rsc-role fields.
Table 10.7. Additional colocation constraint options for multi-state resources
| Field | Default | Description |
|---|---|---|
rsc-role
|
Started
| |
with-rsc-role
|
Started
|
Example 10.8. Constraints involving multi-state resources
<constraints> <rsc_location id="db-prefers-node1" rsc="database" node="node1" score="500"/> <rsc_colocation id="backup-with-db-slave" rsc="backup" with-rsc="database" with-rsc-role="Slave"/> <rsc_colocation id="myapp-with-db-master" rsc="myApp" with-rsc="database" with-rsc-role="Master"/> <rsc_order id="start-db-before-backup" first="database" then="backup"/> <rsc_order id="promote-db-then-app" first="database" first-action="promote" then="myApp" then-action="start"/> </constraints>
myApp will wait until one of the database copies has been started and promoted to master before being started itself on the same node. Only if no copies can be promoted will myApp be prevented from being active. Additionally, the cluster will wait for myApp to be stopped before demoting the database.
master or slave). In the example above, the cluster will choose a location based on where database is running as a master, and if there are multiple master instances it will also factor in myApp's own location preferences when deciding which location to choose.
rsc clone is (after role filtering) limited to nodes on which the with-rsc multi-state resource is (or will be) in the specified role. Placement is then performed as normal.
B's master must be located on the same node as A's master. Additionally resources C and D must be located on the same node as A's and B's masters.
Example 10.9. Colocate C and D with A’s and B’s master instances
<constraints> <rsc_colocation id="coloc-1" score="INFINITY" > <resource_set id="colocated-set-example-1" sequential="true" role="Master"> <resource_ref id="A"/> <resource_ref id="B"/> </resource_set> <resource_set id="colocated-set-example-2" sequential="true"> <resource_ref id="C"/> <resource_ref id="D"/> </resource_set> </rsc_colocation> </constraints>
Example 10.10. Start C and D after first promoting A and B
<constraints> <rsc_order id="order-1" score="INFINITY" > <resource_set id="ordered-set-1" sequential="true" action="promote"> <resource_ref id="A"/> <resource_ref id="B"/> </resource_set> <resource_set id="ordered-set-2" sequential="true" action="start"> <resource_ref id="C"/> <resource_ref id="D"/> </resource_set> </rsc_order> </constraints>
B cannot be promoted to a master role until A has been promoted. Additionally, resources C and D must wait until A and B have been promoted before they can start.
crm_master utility. This tool automatically detects both the resource and host and should be used to set a preference for being promoted. Based on this, master-max, and master-node-max, the instance(s) with the highest preference will be promoted.
Example 10.11. Explicitly preferring node1 to be promoted to master
<rsc_location id="master-location" rsc="myMasterRsc"> <rule id="master-rule" score="100" role="Master"> <expression id="master-exp" attribute="#uname" operation="eq" value="node1"/> </rule> </rsc_location>
demote and promote, which are responsible for changing the state of the resource. Like start and stop, they should return ${OCF_SUCCESS} if they completed successfully or a relevant error code if they did not.
slave. From there the cluster will decide which instances to promote to master.
notify action to be implemented. If supported, the notify action will be passed a number of extra variables which, when combined with additional context, can be used to calculate the current state of the cluster and what is about to happen to it.
Table 10.11. Environment variables supplied with multi-state notify actions [a]
| Variable | Description |
|---|---|
|
OCF_RESKEY_CRM_meta_notify_type
| |
|
OCF_RESKEY_CRM_meta_notify_operation
| |
|
OCF_RESKEY_CRM_meta_notify_active_resource
| |
|
OCF_RESKEY_CRM_meta_notify_inactive_resource
| |
|
OCF_RESKEY_CRM_meta_notify_master_resource
| |
|
OCF_RESKEY_CRM_meta_notify_slave_resource
| |
|
OCF_RESKEY_CRM_meta_notify_start_resource
| |
|
OCF_RESKEY_CRM_meta_notify_stop_resource
| |
|
OCF_RESKEY_CRM_meta_notify_promote_resource
| |
|
OCF_RESKEY_CRM_meta_notify_demote_resource
| |
|
OCF_RESKEY_CRM_meta_notify_start_uname
| |
|
OCF_RESKEY_CRM_meta_notify_stop_uname
| |
|
OCF_RESKEY_CRM_meta_notify_promote_uname
| |
|
OCF_RESKEY_CRM_meta_notify_demote_uname
| |
|
OCF_RESKEY_CRM_meta_notify_active_uname
| |
|
OCF_RESKEY_CRM_meta_notify_master_uname
| |
|
OCF_RESKEY_CRM_meta_notify_slave_uname
|
Pre-notification (demote):
Active resources: $OCF_RESKEY_CRM_meta_notify_active_resource
Master resources: $OCF_RESKEY_CRM_meta_notify_master_resource
Slave resources: $OCF_RESKEY_CRM_meta_notify_slave_resource
$OCF_RESKEY_CRM_meta_notify_inactive_resource
$OCF_RESKEY_CRM_meta_notify_start_resource
$OCF_RESKEY_CRM_meta_notify_promote_resource
$OCF_RESKEY_CRM_meta_notify_demote_resource
$OCF_RESKEY_CRM_meta_notify_stop_resource
Post-notification (demote) / Pre-notification (stop):
Active resources: $OCF_RESKEY_CRM_meta_notify_active_resource
Master resources:
$OCF_RESKEY_CRM_meta_notify_master_resource
$OCF_RESKEY_CRM_meta_notify_demote_resource
Slave resources: $OCF_RESKEY_CRM_meta_notify_slave_resource
$OCF_RESKEY_CRM_meta_notify_inactive_resource
$OCF_RESKEY_CRM_meta_notify_start_resource
$OCF_RESKEY_CRM_meta_notify_promote_resource
$OCF_RESKEY_CRM_meta_notify_demote_resource
$OCF_RESKEY_CRM_meta_notify_stop_resource
$OCF_RESKEY_CRM_meta_notify_demote_resource
Post-notification (stop) / Pre-notification (start)
Active resources:
$OCF_RESKEY_CRM_meta_notify_active_resource
$OCF_RESKEY_CRM_meta_notify_stop_resource
Master resources:
$OCF_RESKEY_CRM_meta_notify_master_resource
$OCF_RESKEY_CRM_meta_notify_demote_resource
Slave resources:
$OCF_RESKEY_CRM_meta_notify_slave_resource
$OCF_RESKEY_CRM_meta_notify_stop_resource
$OCF_RESKEY_CRM_meta_notify_inactive_resource
$OCF_RESKEY_CRM_meta_notify_stop_resource
$OCF_RESKEY_CRM_meta_notify_start_resource
$OCF_RESKEY_CRM_meta_notify_promote_resource
$OCF_RESKEY_CRM_meta_notify_demote_resource
$OCF_RESKEY_CRM_meta_notify_stop_resource
$OCF_RESKEY_CRM_meta_notify_demote_resource
$OCF_RESKEY_CRM_meta_notify_stop_resource
Post-notification (start) / Pre-notification (promote)
Active resources:
$OCF_RESKEY_CRM_meta_notify_active_resource
$OCF_RESKEY_CRM_meta_notify_stop_resource
$OCF_RESKEY_CRM_meta_notify_start_resource
Master resources:
$OCF_RESKEY_CRM_meta_notify_master_resource
$OCF_RESKEY_CRM_meta_notify_demote_resource
Slave resources:
$OCF_RESKEY_CRM_meta_notify_slave_resource
$OCF_RESKEY_CRM_meta_notify_stop_resource
$OCF_RESKEY_CRM_meta_notify_start_resource
$OCF_RESKEY_CRM_meta_notify_inactive_resource
$OCF_RESKEY_CRM_meta_notify_stop_resource
$OCF_RESKEY_CRM_meta_notify_start_resource
$OCF_RESKEY_CRM_meta_notify_start_resource
$OCF_RESKEY_CRM_meta_notify_promote_resource
$OCF_RESKEY_CRM_meta_notify_demote_resource
$OCF_RESKEY_CRM_meta_notify_stop_resource
$OCF_RESKEY_CRM_meta_notify_start_resource
$OCF_RESKEY_CRM_meta_notify_demote_resource
$OCF_RESKEY_CRM_meta_notify_stop_resource
Post-notification (promote)
Active resources:
$OCF_RESKEY_CRM_meta_notify_active_resource
$OCF_RESKEY_CRM_meta_notify_stop_resource
$OCF_RESKEY_CRM_meta_notify_start_resource
Master resources:
$OCF_RESKEY_CRM_meta_notify_master_resource
$OCF_RESKEY_CRM_meta_notify_demote_resource
$OCF_RESKEY_CRM_meta_notify_promote_resource
Slave resources:
$OCF_RESKEY_CRM_meta_notify_slave_resource
$OCF_RESKEY_CRM_meta_notify_stop_resource
$OCF_RESKEY_CRM_meta_notify_start_resource
$OCF_RESKEY_CRM_meta_notify_promote_resource
$OCF_RESKEY_CRM_meta_notify_inactive_resource
$OCF_RESKEY_CRM_meta_notify_stop_resource
$OCF_RESKEY_CRM_meta_notify_start_resource
$OCF_RESKEY_CRM_meta_notify_start_resource
$OCF_RESKEY_CRM_meta_notify_promote_resource
$OCF_RESKEY_CRM_meta_notify_demote_resource
$OCF_RESKEY_CRM_meta_notify_stop_resource
$OCF_RESKEY_CRM_meta_notify_start_resource
$OCF_RESKEY_CRM_meta_notify_promote_resource
$OCF_RESKEY_CRM_meta_notify_demote_resource
$OCF_RESKEY_CRM_meta_notify_stop_resource
Example 10.12. A bundle for a containerized web server
<bundle id="httpd-bundle"> <docker image="pcmk:http" replicas="3"/> <network ip-range-start="192.168.122.131" host-netmask="24" host-interface="eth0"> <port-mapping id="httpd-port" port="80"/> </network> <storage> <storage-mapping id="httpd-syslog" source-dir="/dev/log" target-dir="/dev/log" options="rw"/> <storage-mapping id="httpd-root" source-dir="/srv/html" target-dir="/var/www/html" options="rw"/> <storage-mapping id="httpd-logs" source-dir-root="/var/log/pacemaker/bundles" target-dir="/etc/httpd/logs" options="rw"/> </storage> <primitive class="ocf" id="httpd" provider="heartbeat" type="apache"/> </bundle>
ocf:heartbeat:docker resource to manage a bundle’s Docker container. The user must ensure that resource agent is installed on every node allowed to run the bundle.
Table 10.13. Properties of a Bundle’s Docker Element
| Field | Default | Description |
|---|---|---|
image
|
| |
replicas
|
Value of
masters if that is positive, else 1
| |
replicas-per-host
|
1
| |
masters
|
0
| |
network
|
| |
run-command
|
/usr/sbin/pacemaker_remoted if bundle contains a primitive, otherwise none
| |
options
|
|
ocf:heartbeat:rkt resource to manage a bundle’s rkt container. The user must ensure that resource agent is installed on every node allowed to run the bundle.
Table 10.14. Properties of a Bundle’s rkt Element
| Field | Default | Description |
|---|---|---|
image
|
| |
replicas
|
Value of
masters if that is positive, else 1
| |
replicas-per-host
|
1
| |
masters
|
0
| |
network
|
| |
run-command
|
/usr/sbin/pacemaker_remoted if bundle contains a primitive, otherwise none
| |
options
|
|
Table 10.15. Properties of a Bundle’s Network Element
Note
ip-range-start is used, Pacemaker will automatically ensure that /etc/hosts inside the containers has entries for each replica and its assigned IP. Replicas are named by the bundle id plus a dash and an integer counter starting with zero. For example, if a bundle named httpd-bundle has replicas=2, its containers will be named httpd-bundle-0 and httpd-bundle-1.
Table 10.16. Properties of a Bundle’s Port-Mapping Element
Note
primitive, Pacemaker will automatically map the control-port, so it is not necessary to specify that port in a port-mapping.
<storage> element. A <storage> element has no properties of its own, but may contain one or more <storage-mapping> elements.
Table 10.17. Properties of a Bundle’s Storage-Mapping Element
| Field | Default | Description |
|---|---|---|
id
|
| |
source-dir
|
| |
source-dir-root
|
|
The start of a path on the host’s filesystem that will be mapped into the container, using a different subdirectory on the host for each container instance. The subdirectory will be named the same as the bundle host name, as described in the note for
ip-range-start. Exactly one of source-dir and source-dir-root must be specified in a storage-mapping.
|
target-dir
|
| |
options
|
|
Note
Note
primitive, Pacemaker will automatically map the equivalent of source-dir=/etc/pacemaker/authkey target-dir=/etc/pacemaker/authkey and source-dir-root=/var/log/pacemaker/bundles target-dir=/var/log into the container, so it is not necessary to specify those paths in a storage-mapping.
Important
PCMK_authkey_location environment variable must not be set to anything other than the default of /etc/pacemaker/authkey on any node in the cluster.
<primitive> resource (see Section 5.1, “What is a Cluster Resource?”). The primitive may have operations, instance attributes and meta-attributes defined, as usual.
ip-range-start or control-port must be configured in the bundle. Pacemaker will create an implicit ocf:pacemaker:remote resource for the connection, launch Pacemaker Remote within the container, and monitor and manage the primitive resource via Pacemaker Remote.
masters greater than zero (see Section 10.3, “Multi-state - Resources That Have Multiple Modes”).
Important
primitive must have an accessible networking environment, so that Pacemaker on the cluster nodes can contact Pacemaker Remote inside the container. For example, the Docker option --net=none should not be used with a primitive. The default (using a distinct network space inside the container) works in combination with ip-range-start. If the Docker option --net=host is used (making the container share the host’s network space), a unique control-port should be specified for each bundle. Any firewall must allow access to the control-port.
primitive, the primitive’s resource agent may want to set node attributes such as master scores. However, with containers, it is not apparent which node should get the attribute.
container-attribute-target resource meta-attribute allows the user to specify which approach to use. If it is set to host, then user-defined node attributes will be checked on the underlying host. If it is anything else, the local node (in this case the bundle node) is used as usual.
#uname.
container-attribute-target is host, the cluster will pass additional environment variables to the primitive’s resource agent that allow it to set node attributes appropriately: container_attribute_target (identical to the meta-attribute value) and physical_host (the name of the underlying host).
Note
priority, target-role, and is-managed. See Section 5.4, “Resource Options” for more information.
control-port.
Table of Contents
Example 11.1. Resource template for a migratable Xen virtual machine
<template id="vm-template" class="ocf" provider="heartbeat" type="Xen"> <meta_attributes id="vm-template-meta_attributes"> <nvpair id="vm-template-meta_attributes-allow-migrate" name="allow-migrate" value="true"/> </meta_attributes> <utilization id="vm-template-utilization"> <nvpair id="vm-template-utilization-memory" name="memory" value="512"/> </utilization> <operations> <op id="vm-template-monitor-15s" interval="15s" name="monitor" timeout="60s"/> <op id="vm-template-start-0" interval="0" name="start" timeout="60s"/> </operations> </template>
template property.
Example 11.2. Xen primitive resource using a resource template
<primitive id="vm1" template="vm-template"> <instance_attributes id="vm1-instance_attributes"> <nvpair id="vm1-instance_attributes-name" name="name" value="vm1"/> <nvpair id="vm1-instance_attributes-xmfile" name="xmfile" value="/etc/xen/shared-vm/vm1"/> </instance_attributes> </primitive>
vm1 will inherit everything from vm-template. For example, the equivalent of the above two examples would be:
Example 11.3. Equivalent Xen primitive resource not using a resource template
<primitive id="vm1" class="ocf" provider="heartbeat" type="Xen"> <meta_attributes id="vm-template-meta_attributes"> <nvpair id="vm-template-meta_attributes-allow-migrate" name="allow-migrate" value="true"/> </meta_attributes> <utilization id="vm-template-utilization"> <nvpair id="vm-template-utilization-memory" name="memory" value="512"/> </utilization> <operations> <op id="vm-template-monitor-15s" interval="15s" name="monitor" timeout="60s"/> <op id="vm-template-start-0" interval="0" name="start" timeout="60s"/> </operations> <instance_attributes id="vm1-instance_attributes"> <nvpair id="vm1-instance_attributes-name" name="name" value="vm1"/> <nvpair id="vm1-instance_attributes-xmfile" name="xmfile" value="/etc/xen/shared-vm/vm1"/> </instance_attributes> </primitive>
Example 11.4. Xen resource overriding template values
<primitive id="vm2" template="vm-template"> <meta_attributes id="vm2-meta_attributes"> <nvpair id="vm2-meta_attributes-allow-migrate" name="allow-migrate" value="false"/> </meta_attributes> <utilization id="vm2-utilization"> <nvpair id="vm2-utilization-memory" name="memory" value="1024"/> </utilization> <instance_attributes id="vm2-instance_attributes"> <nvpair id="vm2-instance_attributes-name" name="name" value="vm2"/> <nvpair id="vm2-instance_attributes-xmfile" name="xmfile" value="/etc/xen/shared-vm/vm2"/> </instance_attributes> <operations> <op id="vm2-monitor-30s" interval="30s" name="monitor" timeout="120s"/> <op id="vm2-stop-0" interval="0" name="stop" timeout="60s"/> </operations> </primitive>
vm2 has special attribute values. Its monitor operation has a longer timeout and interval, and the primitive has an additional stop operation.
# crm_resource --query-xml --resource vm2
# crm_resource --query-xml-raw --resource vm2
order constraints (see Section 6.3, “Specifying the Order in which Resources Should Start/Stop”)
colocation constraints (see Section 6.4, “Placing Resources Relative to other Resources”)
rsc_ticket constraints (for multi-site clusters as described in Section 15.3, “Configuring Ticket Dependencies”)
<rsc_colocation id="vm-template-colo-base-rsc" rsc="vm-template" rsc-role="Started" with-rsc="base-rsc" score="INFINITY"/>
base-rsc and is the equivalent of the following constraint configuration:
<rsc_colocation id="vm-colo-base-rsc" score="INFINITY"> <resource_set id="vm-colo-base-rsc-0" sequential="false" role="Started"> <resource_ref id="vm1"/> <resource_ref id="vm2"/> </resource_set> <resource_set id="vm-colo-base-rsc-1"> <resource_ref id="base-rsc"/> </resource_set> </rsc_colocation>
Note
rsc or with-rsc; the other reference must be a regular resource.
<rsc_order id="order1" score="INFINITY"> <resource_set id="order1-0"> <resource_ref id="base-rsc"/> <resource_ref id="vm-template"/> <resource_ref id="top-rsc"/> </resource_set> </rsc_order>
<rsc_order id="order1" score="INFINITY"> <resource_set id="order1-0"> <resource_ref id="base-rsc"/> <resource_ref id="vm1"/> <resource_ref id="vm2"/> <resource_ref id="top-rsc"/> </resource_set> </rsc_order>
<rsc_order id="order2" score="INFINITY"> <resource_set id="order2-0"> <resource_ref id="base-rsc"/> </resource_set> <resource_set id="order2-1" sequential="false"> <resource_ref id="vm-template"/> </resource_set> <resource_set id="order2-2"> <resource_ref id="top-rsc"/> </resource_set> </rsc_order>
<rsc_order id="order2" score="INFINITY"> <resource_set id="order2-0"> <resource_ref id="base-rsc"/> </resource_set> <resource_set id="order2-1" sequential="false"> <resource_ref id="vm1"/> <resource_ref id="vm2"/> </resource_set> <resource_set id="order2-2"> <resource_ref id="top-rsc"/> </resource_set> </rsc_order>
id-ref instead of an id.
<rsc_location id="WebServer-connectivity" rsc="Webserver"> <rule id="ping-prefer-rule" score-attribute="pingd" > <expression id="ping-prefer" attribute="pingd" operation="defined"/> </rule> </rsc_location>
Example 11.5. Referencing rules from other constraints
<rsc_location id="WebDB-connectivity" rsc="WebDB"> <rule id-ref="ping-prefer-rule"/> </rsc_location>
Important
rule exists somewhere. Attempting to add a reference to a non-existing rule will cause a validation failure, as will attempting to remove a rule that is referenced elsewhere.
meta_attributes and instance_attributes as illustrated in the example below:
Example 11.6. Referencing attributes, options, and operations from other resources
<primitive id="mySpecialRsc" class="ocf" type="Special" provider="me"> <instance_attributes id="mySpecialRsc-attrs" score="1" > <nvpair id="default-interface" name="interface" value="eth0"/> <nvpair id="default-port" name="port" value="9999"/> </instance_attributes> <meta_attributes id="mySpecialRsc-options"> <nvpair id="failure-timeout" name="failure-timeout" value="5m"/> <nvpair id="migration-threshold" name="migration-threshold" value="1"/> <nvpair id="stickiness" name="resource-stickiness" value="0"/> </meta_attributes> <operations id="health-checks"> <op id="health-check" name="monitor" interval="60s"/> <op id="health-check" name="monitor" interval="30min"/> </operations> </primitive> <primitive id="myOtherlRsc" class="ocf" type="Other" provider="me"> <instance_attributes id-ref="mySpecialRsc-attrs"/> <meta_attributes id-ref="mySpecialRsc-options"/> <operations id-ref="health-checks"/> </primitive>
Example 11.7. Tag referencing three resources
<tags> <tag id="all-vms"> <obj_ref id="vm1"/> <obj_ref id="vm2"/> <obj_ref id="vm3"/> </tag> </tags>
Example 11.8. Constraint using a tag
<rsc_order id="order1" first="storage" then="all-vms" kind="Mandatory" />
all-vms tag is defined as in the previous example, the constraint will behave the same as:
Example 11.9. Equivalent constraints without tags
<rsc_order id="order1-1" first="storage" then="vm1" kind="Mandatory" /> <rsc_order id="order1-2" first="storage" then="vm2" kind="Mandatory" /> <rsc_order id="order1-3" first="storage" then="vm2" kind="Mandatory" />
sequential property.
Table of Contents
node and resource objects. You can name utilization attributes according to your preferences and define as many name/value pairs as your configuration needs. However, the attributes' values must be integers.
Example 12.1. Specifying CPU and RAM capacities of two nodes
<node id="node1" type="normal" uname="node1"> <utilization id="node1-utilization"> <nvpair id="node1-utilization-cpu" name="cpu" value="2"/> <nvpair id="node1-utilization-memory" name="memory" value="2048"/> </utilization> </node> <node id="node2" type="normal" uname="node2"> <utilization id="node2-utilization"> <nvpair id="node2-utilization-cpu" name="cpu" value="4"/> <nvpair id="node2-utilization-memory" name="memory" value="4096"/> </utilization> </node>
Example 12.2. Specifying CPU and RAM consumed by several resources
<primitive id="rsc-small" class="ocf" provider="pacemaker" type="Dummy"> <utilization id="rsc-small-utilization"> <nvpair id="rsc-small-utilization-cpu" name="cpu" value="1"/> <nvpair id="rsc-small-utilization-memory" name="memory" value="1024"/> </utilization> </primitive> <primitive id="rsc-medium" class="ocf" provider="pacemaker" type="Dummy"> <utilization id="rsc-medium-utilization"> <nvpair id="rsc-medium-utilization-cpu" name="cpu" value="2"/> <nvpair id="rsc-medium-utilization-memory" name="memory" value="2048"/> </utilization> </primitive> <primitive id="rsc-large" class="ocf" provider="pacemaker" type="Dummy"> <utilization id="rsc-large-utilization"> <nvpair id="rsc-large-utilization-cpu" name="cpu" value="3"/> <nvpair id="rsc-large-utilization-memory" name="memory" value="3072"/> </utilization> </primitive>
placement-strategy in the global cluster options, otherwise the capacity configurations have no effect.
placement-strategy:
defaultutilizationbalancedminimalplacement-strategy with crm_attribute:
# crm_attribute --name placement-strategy --update balanced
placement-strategy is default or utilization, the node that has the least number of allocated resources gets consumed first.
placement-strategy is balanced, the node that has the most free capacity gets consumed first.
placement-strategy is minimal, the first eligible node listed in the CIB gets consumed first.
nodeA has more free cpus, and nodeB has more free memory, then their free capacities are equal.
nodeA has more free cpus, while nodeB has more free memory and storage, then nodeB has more free capacity.
priority (see Section 5.4, “Resource Options”) gets allocated first.
rsc-small would be allocated to node1
rsc-medium would be allocated to node2
rsc-large would remain inactive
Table of Contents
Note
target-role can be used to enable or disable the resource
Important
man stonithd to see special instance attributes that may be set for any fencing resource, regardless of fence agent.
Table 13.1. Additional Properties of Fencing Resources
| Field | Type | Default | Description |
|---|---|---|---|
stonith-timeout
|
NA
|
NA
| |
provides
|
string
|
|
Any special capability provided by the fence device. Currently, only one such capability is meaningful:
unfencing (see Section 13.4, “Unfencing”).
|
pcmk_host_map
|
string
|
| |
pcmk_host_list
|
string
|
| |
pcmk_host_check
|
string
|
dynamic-list
|
How to determine which machines are controlled by the device. Allowed values:
|
pcmk_delay_max
|
time
|
0s
|
Enable a random delay of up to the time specified before executing stonith actions. This is sometimes used in two-node clusters to ensure that the nodes don’t fence each other at the same time. The overall delay introduced by pacemaker is derived from this random delay value adding a static delay so that the sum is kept below the maximum delay.
|
pcmk_delay_base
|
time
|
0s
|
Enable a static delay before executing stonith actions. This can be used e.g. in two-node clusters to ensure that the nodes don’t fence each other, by having separate fencing resources with different values. The node that is fenced with the shorter delay will lose a fencing race. The overall delay introduced by pacemaker is derived from this value plus a random delay such that the sum is kept below the maximum delay.
|
pcmk_action_limit
|
integer
|
1
|
The maximum number of actions that can be performed in parallel on this device, if the cluster option
concurrent-fencing is true. -1 is unlimited. (since 1.1.15)
|
pcmk_host_argument
|
string
|
port
|
Advanced use only. Which parameter should be supplied to the resource agent to identify the node to be fenced. Some devices do not support the standard
port parameter or may provide additional ones. Use this to specify an alternate, device-specific parameter. A value of none tells the cluster not to supply any additional parameters.
|
pcmk_reboot_action
|
string
|
reboot
| |
pcmk_reboot_timeout
|
time
|
60s
| |
pcmk_reboot_retries
|
integer
|
2
|
Advanced use only. The maximum number of times to retry the
reboot command within the timeout period. Some devices do not support multiple connections, and operations may fail if the device is busy with another task, so Pacemaker will automatically retry the operation, if there is time remaining. Use this option to alter the number of times Pacemaker retries before giving up.
|
pcmk_off_action
|
string
|
off
| |
pcmk_off_timeout
|
time
|
60s
| |
pcmk_off_retries
|
integer
|
2
|
Advanced use only. The maximum number of times to retry the
off command within the timeout period. Some devices do not support multiple connections, and operations may fail if the device is busy with another task, so Pacemaker will automatically retry the operation, if there is time remaining. Use this option to alter the number of times Pacemaker retries before giving up.
|
pcmk_list_action
|
string
|
list
| |
pcmk_list_timeout
|
time
|
60s
| |
pcmk_list_retries
|
integer
|
2
|
Advanced use only. The maximum number of times to retry the
list command within the timeout period. Some devices do not support multiple connections, and operations may fail if the device is busy with another task, so Pacemaker will automatically retry the operation, if there is time remaining. Use this option to alter the number of times Pacemaker retries before giving up.
|
pcmk_monitor_action
|
string
|
monitor
| |
pcmk_monitor_timeout
|
time
|
60s
| |
pcmk_monitor_retries
|
integer
|
2
|
Advanced use only. The maximum number of times to retry the
monitor command within the timeout period. Some devices do not support multiple connections, and operations may fail if the device is busy with another task, so Pacemaker will automatically retry the operation, if there is time remaining. Use this option to alter the number of times Pacemaker retries before giving up.
|
pcmk_status_action
|
string
|
status
| |
pcmk_status_timeout
|
time
|
60s
| |
pcmk_status_retries
|
integer
|
2
|
Advanced use only. The maximum number of times to retry the
status command within the timeout period. Some devices do not support multiple connections, and operations may fail if the device is busy with another task, so Pacemaker will automatically retry the operation, if there is time remaining. Use this option to alter the number of times Pacemaker retries before giving up.
|
on command.
requires set to unfencing, then that resource will not be probed or started on a node until that node has been unfenced.
Note
# stonith_admin --list-installed
# stonith_admin --metadata --agent $AGENT_NAME
stonith.xml containing a primitive resource with a class of stonith, a type equal to the agent name obtained earlier, and a parameter for each of the values returned in the previous step.
pcmk_host_map parameter. See man stonithd for details.
list command, you may also need to set the special pcmk_host_list and/or pcmk_host_check parameters. See man stonithd for details.
port parameter, you may also need to set the special pcmk_host_argument parameter. See man stonithd for details.
# cibadmin -C -o resources --xml-file stonith.xml
stonith-enabled to true:
# crm_attribute -t crm_config -n stonith-enabled -v true
# stonith_admin --reboot nodename
fence_ipmilan driver, and obtain the following list of parameters:
Example 13.1. Obtaining a list of STONITH Parameters
# stonith_admin --metadata -a fence_ipmilan
<resource-agent name="fence_ipmilan" shortdesc="Fence agent for IPMI over LAN"> <symlink name="fence_ilo3" shortdesc="Fence agent for HP iLO3"/> <symlink name="fence_ilo4" shortdesc="Fence agent for HP iLO4"/> <symlink name="fence_idrac" shortdesc="Fence agent for Dell iDRAC"/> <symlink name="fence_imm" shortdesc="Fence agent for IBM Integrated Management Module"/> <longdesc> </longdesc> <vendor-url> </vendor-url> <parameters> <parameter name="auth" unique="0" required="0"> <getopt mixed="-A"/> <content type="string"/> <shortdesc> </shortdesc> </parameter> <parameter name="ipaddr" unique="0" required="1"> <getopt mixed="-a"/> <content type="string"/> <shortdesc> </shortdesc> </parameter> <parameter name="passwd" unique="0" required="0"> <getopt mixed="-p"/> <content type="string"/> <shortdesc> </shortdesc> </parameter> <parameter name="passwd_script" unique="0" required="0"> <getopt mixed="-S"/> <content type="string"/> <shortdesc> </shortdesc> </parameter> <parameter name="lanplus" unique="0" required="0"> <getopt mixed="-P"/> <content type="boolean"/> <shortdesc> </shortdesc> </parameter> <parameter name="login" unique="0" required="0"> <getopt mixed="-l"/> <content type="string"/> <shortdesc> </shortdesc> </parameter> <parameter name="action" unique="0" required="0"> <getopt mixed="-o"/> <content type="string" default="reboot"/> <shortdesc> </shortdesc> </parameter> <parameter name="timeout" unique="0" required="0"> <getopt mixed="-t"/> <content type="string"/> <shortdesc> </shortdesc> </parameter> <parameter name="cipher" unique="0" required="0"> <getopt mixed="-C"/> <content type="string"/> <shortdesc> </shortdesc> </parameter> <parameter name="method" unique="0" required="0"> <getopt mixed="-M"/> <content type="string" default="onoff"/> <shortdesc> </shortdesc> </parameter> <parameter name="power_wait" unique="0" required="0"> <getopt mixed="-T"/> <content type="string" default="2"/> <shortdesc> </shortdesc> </parameter> <parameter name="delay" unique="0" required="0"> <getopt mixed="-f"/> <content type="string"/> <shortdesc> </shortdesc> </parameter> <parameter name="privlvl" unique="0" required="0"> <getopt mixed="-L"/> <content type="string"/> <shortdesc> </shortdesc> </parameter> <parameter name="verbose" unique="0" required="0"> <getopt mixed="-v"/> <content type="boolean"/> <shortdesc> </shortdesc> </parameter> </parameters> <actions> <action name="on"/> <action name="off"/> <action name="reboot"/> <action name="status"/> <action name="diag"/> <action name="list"/> <action name="monitor"/> <action name="metadata"/> <action name="stop" timeout="20s"/> <action name="start" timeout="20s"/> </actions> </resource-agent>
Example 13.2. An IPMI-based STONITH Resource
<primitive id="Fencing" class="stonith" type="fence_ipmilan" > <instance_attributes id="Fencing-params" > <nvpair id="Fencing-passwd" name="passwd" value="testuser" /> <nvpair id="Fencing-login" name="login" value="abc123" /> <nvpair id="Fencing-ipaddr" name="ipaddr" value="192.0.2.1" /> <nvpair id="Fencing-pcmk_host_list" name="pcmk_host_list" value="pcmk-1 pcmk-2" /> </instance_attributes> <operations > <op id="Fencing-monitor-10m" interval="10m" name="monitor" timeout="300s" /> </operations> </primitive>
# crm_attribute -t crm_config -n stonith-enabled -v true
fencing-level entries in the fencing-topology section of the configuration.
index. Allowed values are 1 through 9.
crmd.
Table 13.2. Properties of Fencing Levels
| Field | Description |
|---|---|
id
| |
target
| |
target-pattern
| |
target-attribute
| |
target-value
| |
index
| |
devices
|
Example 13.3. Fencing topology with different devices for different nodes
<cib crm_feature_set="3.0.6" validate-with="pacemaker-1.2" admin_epoch="1" epoch="0" num_updates="0"> <configuration> ... <fencing-topology> <!-- For pcmk-1, try poison-pill and fail back to power --> <fencing-level id="f-p1.1" target="pcmk-1" index="1" devices="poison-pill"/> <fencing-level id="f-p1.2" target="pcmk-1" index="2" devices="power"/> <!-- For pcmk-2, try disk and network, and fail back to power --> <fencing-level id="f-p2.1" target="pcmk-2" index="1" devices="disk,network"/> <fencing-level id="f-p2.2" target="pcmk-2" index="2" devices="power"/> </fencing-topology> ... <configuration> <status/> </cib>
fencing-topology in a cluster with the following properties:
fence_ipmi agent
fence_apc_snmp agent targetting 2 fencing devices (one per PSU, either port 10 or 11)
fence_ipmi to try to kill the faulty node. Using a fencing topology, if that first method fails, STONITH will then move on to selecting fence_apc_snmp twice:
fence_ipmi, and so on until the node is fenced or fencing action is cancelled.
<primitive class="stonith" id="fence_prod-mysql1_ipmi" type="fence_ipmilan"> <instance_attributes id="fence_prod-mysql1_ipmi-instance_attributes"> <nvpair id="fence_prod-mysql1_ipmi-instance_attributes-ipaddr" name="ipaddr" value="192.0.2.1"/> <nvpair id="fence_prod-mysql1_ipmi-instance_attributes-action" name="action" value="off"/> <nvpair id="fence_prod-mysql1_ipmi-instance_attributes-login" name="login" value="fencing"/> <nvpair id="fence_prod-mysql1_ipmi-instance_attributes-passwd" name="passwd" value="finishme"/> <nvpair id="fence_prod-mysql1_ipmi-instance_attributes-verbose" name="verbose" value="true"/> <nvpair id="fence_prod-mysql1_ipmi-instance_attributes-pcmk_host_list" name="pcmk_host_list" value="prod-mysql1"/> <nvpair id="fence_prod-mysql1_ipmi-instance_attributes-lanplus" name="lanplus" value="true"/> </instance_attributes> </primitive> <primitive class="stonith" id="fence_prod-mysql2_ipmi" type="fence_ipmilan"> <instance_attributes id="fence_prod-mysql2_ipmi-instance_attributes"> <nvpair id="fence_prod-mysql2_ipmi-instance_attributes-ipaddr" name="ipaddr" value="192.0.2.2"/> <nvpair id="fence_prod-mysql2_ipmi-instance_attributes-action" name="action" value="off"/> <nvpair id="fence_prod-mysql2_ipmi-instance_attributes-login" name="login" value="fencing"/> <nvpair id="fence_prod-mysql2_ipmi-instance_attributes-passwd" name="passwd" value="finishme"/> <nvpair id="fence_prod-mysql2_ipmi-instance_attributes-verbose" name="verbose" value="true"/> <nvpair id="fence_prod-mysql2_ipmi-instance_attributes-pcmk_host_list" name="pcmk_host_list" value="prod-mysql2"/> <nvpair id="fence_prod-mysql2_ipmi-instance_attributes-lanplus" name="lanplus" value="true"/> </instance_attributes> </primitive>
<primitive class="stonith" id="fence_prod-mysql1_apc1" type="fence_apc_snmp"> <instance_attributes id="fence_prod-mysql1_apc1-instance_attributes"> <nvpair id="fence_prod-mysql1_apc1-instance_attributes-ipaddr" name="ipaddr" value="198.51.100.1"/> <nvpair id="fence_prod-mysql1_apc1-instance_attributes-action" name="action" value="off"/> <nvpair id="fence_prod-mysql1_apc1-instance_attributes-port" name="port" value="10"/> <nvpair id="fence_prod-mysql1_apc1-instance_attributes-login" name="login" value="fencing"/> <nvpair id="fence_prod-mysql1_apc1-instance_attributes-passwd" name="passwd" value="fencing"/> <nvpair id="fence_prod-mysql1_apc1-instance_attributes-pcmk_host_list" name="pcmk_host_list" value="prod-mysql1"/> </instance_attributes> </primitive> <primitive class="stonith" id="fence_prod-mysql1_apc2" type="fence_apc_snmp"> <instance_attributes id="fence_prod-mysql1_apc2-instance_attributes"> <nvpair id="fence_prod-mysql1_apc2-instance_attributes-ipaddr" name="ipaddr" value="203.0.113.1"/> <nvpair id="fence_prod-mysql1_apc2-instance_attributes-action" name="action" value="off"/> <nvpair id="fence_prod-mysql1_apc2-instance_attributes-port" name="port" value="10"/> <nvpair id="fence_prod-mysql1_apc2-instance_attributes-login" name="login" value="fencing"/> <nvpair id="fence_prod-mysql1_apc2-instance_attributes-passwd" name="passwd" value="fencing"/> <nvpair id="fence_prod-mysql1_apc2-instance_attributes-pcmk_host_list" name="pcmk_host_list" value="prod-mysql1"/> </instance_attributes> </primitive> <primitive class="stonith" id="fence_prod-mysql2_apc1" type="fence_apc_snmp"> <instance_attributes id="fence_prod-mysql2_apc1-instance_attributes"> <nvpair id="fence_prod-mysql2_apc1-instance_attributes-ipaddr" name="ipaddr" value="198.51.100.1"/> <nvpair id="fence_prod-mysql2_apc1-instance_attributes-action" name="action" value="off"/> <nvpair id="fence_prod-mysql2_apc1-instance_attributes-port" name="port" value="11"/> <nvpair id="fence_prod-mysql2_apc1-instance_attributes-login" name="login" value="fencing"/> <nvpair id="fence_prod-mysql2_apc1-instance_attributes-passwd" name="passwd" value="fencing"/> <nvpair id="fence_prod-mysql2_apc1-instance_attributes-pcmk_host_list" name="pcmk_host_list" value="prod-mysql2"/> </instance_attributes> </primitive> <primitive class="stonith" id="fence_prod-mysql2_apc2" type="fence_apc_snmp"> <instance_attributes id="fence_prod-mysql2_apc2-instance_attributes"> <nvpair id="fence_prod-mysql2_apc2-instance_attributes-ipaddr" name="ipaddr" value="203.0.113.1"/> <nvpair id="fence_prod-mysql2_apc2-instance_attributes-action" name="action" value="off"/> <nvpair id="fence_prod-mysql2_apc2-instance_attributes-port" name="port" value="11"/> <nvpair id="fence_prod-mysql2_apc2-instance_attributes-login" name="login" value="fencing"/> <nvpair id="fence_prod-mysql2_apc2-instance_attributes-passwd" name="passwd" value="fencing"/> <nvpair id="fence_prod-mysql2_apc2-instance_attributes-pcmk_host_list" name="pcmk_host_list" value="prod-mysql2"/> </instance_attributes> </primitive>
<constraints> <rsc_location id="l_fence_prod-mysql1_ipmi" node="prod-mysql1" rsc="fence_prod-mysql1_ipmi" score="-INFINITY"/> <rsc_location id="l_fence_prod-mysql2_ipmi" node="prod-mysql2" rsc="fence_prod-mysql2_ipmi" score="-INFINITY"/> <rsc_location id="l_fence_prod-mysql1_apc2" node="prod-mysql1" rsc="fence_prod-mysql1_apc2" score="-INFINITY"/> <rsc_location id="l_fence_prod-mysql1_apc1" node="prod-mysql1" rsc="fence_prod-mysql1_apc1" score="-INFINITY"/> <rsc_location id="l_fence_prod-mysql2_apc1" node="prod-mysql2" rsc="fence_prod-mysql2_apc1" score="-INFINITY"/> <rsc_location id="l_fence_prod-mysql2_apc2" node="prod-mysql2" rsc="fence_prod-mysql2_apc2" score="-INFINITY"/> </constraints>
<fencing-topology> <fencing-level devices="fence_prod-mysql1_ipmi" id="fencing-2" index="1" target="prod-mysql1"/> <fencing-level devices="fence_prod-mysql1_apc1,fence_prod-mysql1_apc2" id="fencing-3" index="2" target="prod-mysql1"/> <fencing-level devices="fence_prod-mysql2_ipmi" id="fencing-0" index="1" target="prod-mysql2"/> <fencing-level devices="fence_prod-mysql2_apc1,fence_prod-mysql2_apc2" id="fencing-1" index="2" target="prod-mysql2"/> </fencing-topology>
fencing-topology, the lowest index value determines the priority of the first fencing method.
<cib admin_epoch="0" crm_feature_set="3.0.7" epoch="292" have-quorum="1" num_updates="29" validate-with="pacemaker-1.2"> <configuration> <crm_config> <cluster_property_set id="cib-bootstrap-options"> <nvpair id="cib-bootstrap-options-stonith-enabled" name="stonith-enabled" value="true"/> <nvpair id="cib-bootstrap-options-stonith-action" name="stonith-action" value="off"/> <nvpair id="cib-bootstrap-options-expected-quorum-votes" name="expected-quorum-votes" value="3"/> ... </cluster_property_set> </crm_config> <nodes> <node id="prod-mysql1" uname="prod-mysql1"> <node id="prod-mysql2" uname="prod-mysql2"/> <node id="prod-mysql-rep1" uname="prod-mysql-rep1"/> <instance_attributes id="prod-mysql-rep1"> <nvpair id="prod-mysql-rep1-standby" name="standby" value="on"/> </instance_attributes> </node> </nodes> <resources> <primitive class="stonith" id="fence_prod-mysql1_ipmi" type="fence_ipmilan"> <instance_attributes id="fence_prod-mysql1_ipmi-instance_attributes"> <nvpair id="fence_prod-mysql1_ipmi-instance_attributes-ipaddr" name="ipaddr" value="192.0.2.1"/> <nvpair id="fence_prod-mysql1_ipmi-instance_attributes-action" name="action" value="off"/> <nvpair id="fence_prod-mysql1_ipmi-instance_attributes-login" name="login" value="fencing"/> <nvpair id="fence_prod-mysql1_ipmi-instance_attributes-passwd" name="passwd" value="finishme"/> <nvpair id="fence_prod-mysql1_ipmi-instance_attributes-verbose" name="verbose" value="true"/> <nvpair id="fence_prod-mysql1_ipmi-instance_attributes-pcmk_host_list" name="pcmk_host_list" value="prod-mysql1"/> <nvpair id="fence_prod-mysql1_ipmi-instance_attributes-lanplus" name="lanplus" value="true"/> </instance_attributes> </primitive> <primitive class="stonith" id="fence_prod-mysql2_ipmi" type="fence_ipmilan"> <instance_attributes id="fence_prod-mysql2_ipmi-instance_attributes"> <nvpair id="fence_prod-mysql2_ipmi-instance_attributes-ipaddr" name="ipaddr" value="192.0.2.2"/> <nvpair id="fence_prod-mysql2_ipmi-instance_attributes-action" name="action" value="off"/> <nvpair id="fence_prod-mysql2_ipmi-instance_attributes-login" name="login" value="fencing"/> <nvpair id="fence_prod-mysql2_ipmi-instance_attributes-passwd" name="passwd" value="finishme"/> <nvpair id="fence_prod-mysql2_ipmi-instance_attributes-verbose" name="verbose" value="true"/> <nvpair id="fence_prod-mysql2_ipmi-instance_attributes-pcmk_host_list" name="pcmk_host_list" value="prod-mysql2"/> <nvpair id="fence_prod-mysql2_ipmi-instance_attributes-lanplus" name="lanplus" value="true"/> </instance_attributes> </primitive> <primitive class="stonith" id="fence_prod-mysql1_apc1" type="fence_apc_snmp"> <instance_attributes id="fence_prod-mysql1_apc1-instance_attributes"> <nvpair id="fence_prod-mysql1_apc1-instance_attributes-ipaddr" name="ipaddr" value="198.51.100.1"/> <nvpair id="fence_prod-mysql1_apc1-instance_attributes-action" name="action" value="off"/> <nvpair id="fence_prod-mysql1_apc1-instance_attributes-port" name="port" value="10"/> <nvpair id="fence_prod-mysql1_apc1-instance_attributes-login" name="login" value="fencing"/> <nvpair id="fence_prod-mysql1_apc1-instance_attributes-passwd" name="passwd" value="fencing"/> <nvpair id="fence_prod-mysql1_apc1-instance_attributes-pcmk_host_list" name="pcmk_host_list" value="prod-mysql1"/> </instance_attributes> </primitive> <primitive class="stonith" id="fence_prod-mysql1_apc2" type="fence_apc_snmp"> <instance_attributes id="fence_prod-mysql1_apc2-instance_attributes"> <nvpair id="fence_prod-mysql1_apc2-instance_attributes-ipaddr" name="ipaddr" value="203.0.113.1"/> <nvpair id="fence_prod-mysql1_apc2-instance_attributes-action" name="action" value="off"/> <nvpair id="fence_prod-mysql1_apc2-instance_attributes-port" name="port" value="10"/> <nvpair id="fence_prod-mysql1_apc2-instance_attributes-login" name="login" value="fencing"/> <nvpair id="fence_prod-mysql1_apc2-instance_attributes-passwd" name="passwd" value="fencing"/> <nvpair id="fence_prod-mysql1_apc2-instance_attributes-pcmk_host_list" name="pcmk_host_list" value="prod-mysql1"/> </instance_attributes> </primitive> <primitive class="stonith" id="fence_prod-mysql2_apc1" type="fence_apc_snmp"> <instance_attributes id="fence_prod-mysql2_apc1-instance_attributes"> <nvpair id="fence_prod-mysql2_apc1-instance_attributes-ipaddr" name="ipaddr" value="198.51.100.1"/> <nvpair id="fence_prod-mysql2_apc1-instance_attributes-action" name="action" value="off"/> <nvpair id="fence_prod-mysql2_apc1-instance_attributes-port" name="port" value="11"/> <nvpair id="fence_prod-mysql2_apc1-instance_attributes-login" name="login" value="fencing"/> <nvpair id="fence_prod-mysql2_apc1-instance_attributes-passwd" name="passwd" value="fencing"/> <nvpair id="fence_prod-mysql2_apc1-instance_attributes-pcmk_host_list" name="pcmk_host_list" value="prod-mysql2"/> </instance_attributes> </primitive> <primitive class="stonith" id="fence_prod-mysql2_apc2" type="fence_apc_snmp"> <instance_attributes id="fence_prod-mysql2_apc2-instance_attributes"> <nvpair id="fence_prod-mysql2_apc2-instance_attributes-ipaddr" name="ipaddr" value="203.0.113.1"/> <nvpair id="fence_prod-mysql2_apc2-instance_attributes-action" name="action" value="off"/> <nvpair id="fence_prod-mysql2_apc2-instance_attributes-port" name="port" value="11"/> <nvpair id="fence_prod-mysql2_apc2-instance_attributes-login" name="login" value="fencing"/> <nvpair id="fence_prod-mysql2_apc2-instance_attributes-passwd" name="passwd" value="fencing"/> <nvpair id="fence_prod-mysql2_apc2-instance_attributes-pcmk_host_list" name="pcmk_host_list" value="prod-mysql2"/> </instance_attributes> </primitive> </resources> <constraints> <rsc_location id="l_fence_prod-mysql1_ipmi" node="prod-mysql1" rsc="fence_prod-mysql1_ipmi" score="-INFINITY"/> <rsc_location id="l_fence_prod-mysql2_ipmi" node="prod-mysql2" rsc="fence_prod-mysql2_ipmi" score="-INFINITY"/> <rsc_location id="l_fence_prod-mysql1_apc2" node="prod-mysql1" rsc="fence_prod-mysql1_apc2" score="-INFINITY"/> <rsc_location id="l_fence_prod-mysql1_apc1" node="prod-mysql1" rsc="fence_prod-mysql1_apc1" score="-INFINITY"/> <rsc_location id="l_fence_prod-mysql2_apc1" node="prod-mysql2" rsc="fence_prod-mysql2_apc1" score="-INFINITY"/> <rsc_location id="l_fence_prod-mysql2_apc2" node="prod-mysql2" rsc="fence_prod-mysql2_apc2" score="-INFINITY"/> </constraints> <fencing-topology> <fencing-level devices="fence_prod-mysql1_ipmi" id="fencing-2" index="1" target="prod-mysql1"/> <fencing-level devices="fence_prod-mysql1_apc1,fence_prod-mysql1_apc2" id="fencing-3" index="2" target="prod-mysql1"/> <fencing-level devices="fence_prod-mysql2_ipmi" id="fencing-0" index="1" target="prod-mysql2"/> <fencing-level devices="fence_prod-mysql2_apc1,fence_prod-mysql2_apc2" id="fencing-1" index="2" target="prod-mysql2"/> </fencing-topology> ... </configuration> </cib>
stonith-action is reboot or because a reboot was manually requested (such as by stonith_admin --reboot), it will remap that to other commands in two cases:
reboot command, the cluster will ask it to perform off instead.
off, then ask the devices to perform on.
off commands succeed, because then it is safe for the cluster to recover any resources that were on the node. Timeouts and errors in the on phase will be logged but ignored.
pcmk_off_timeout will be used when executing the off command, not pcmk_reboot_timeout).
Note
Table of Contents
crm_mon.
status section.
Example 14.1. A bare-bones status entry for a healthy node cl-virt-1
<node_state id="cl-virt-1" uname="cl-virt-2" ha="active" in_ccm="true" crmd="online" join="member" expected="member" crm-debug-origin="do_update_resource"> <transient_attributes id="cl-virt-1"/> <lrm id="cl-virt-1"/> </node_state>
Table 14.1. Authoritative Sources for State Information
| CIB Object | Authoritative Source |
|---|---|
node_state
|
crmd
|
transient_attributes
|
attrd
|
lrm
|
lrmd
|
node_state objects are named as they are largely for historical reasons and are rooted in Pacemaker’s origins as the Heartbeat resource manager. They have remained unchanged to preserve compatibility with older versions.
Table 14.2. Node Status Fields
| Field | Description |
|---|---|
id
| |
uname
| |
ha
| |
in_ccm
| |
crmd
| |
join
| |
expected
| |
crm-debug-origin
|
transient_attributes section help to describe the node. However they are forgotten by the cluster when the node goes offline. This can be useful, for instance, when you want a node to be in standby mode (not able to run resources) just until the next reboot.
Example 14.2. A set of transient node attributes for node cl-virt-1
<transient_attributes id="cl-virt-1"> <instance_attributes id="status-cl-virt-1"> <nvpair id="status-cl-virt-1-pingd" name="pingd" value="3"/> <nvpair id="status-cl-virt-1-probe_complete" name="probe_complete" value="true"/> <nvpair id="status-cl-virt-1-fail-count-pingd:0.monitor_30000" name="fail-count-pingd:0#monitor_30000" value="1"/> <nvpair id="status-cl-virt-1-last-failure-pingd:0" name="last-failure-pingd:0" value="1239009742"/> </instance_attributes> </transient_attributes>
pingd:0 resource has failed once, at 09:22:22 UTC 6 April 2009. [20] We also see that the node is connected to three pingd peers and that all known resources have been checked for on this machine (probe_complete).
lrm_resources tag (a child of the lrm tag). The information stored here includes enough information for the cluster to stop the resource safely if it is removed from the configuration section. Specifically, the resource’s id, class, type and provider are stored.
Example 14.3. A record of the apcstonith resource
<lrm_resource id="apcstonith" type="apcmastersnmp" class="stonith"/>
resource, action and interval. The concatenation of the values in this tuple are used to create the id of the lrm_rsc_op object.
Table 14.3. Contents of an lrm_rsc_op job
| Field | Description |
|---|---|
id
|
Identifier for the job constructed from the resource’s
id, operation and interval.
|
call-id
|
The job’s ticket number. Used as a sort key to determine the order in which the jobs were executed.
|
operation
|
The action the resource agent was invoked with.
|
interval
|
The frequency, in milliseconds, at which the operation will be repeated. A one-off job is indicated by 0.
|
op-status
|
The job’s status. Generally this will be either 0 (done) or -1 (pending). Rarely used in favor of
rc-code.
|
rc-code
|
The job’s result. Refer to Section B.4, “OCF Return Codes” for details on what the values here mean and how they are interpreted.
|
last-run
|
Machine-local date/time, in seconds since epoch, at which the job was executed. For diagnostic purposes.
|
last-rc-change
|
Machine-local date/time, in seconds since epoch, at which the job first returned the current value of
rc-code. For diagnostic purposes.
|
exec-time
|
Time, in milliseconds, that the job was running for. For diagnostic purposes.
|
queue-time
|
Time, in seconds, that the job was queued for in the LRMd. For diagnostic purposes.
|
crm_feature_set
|
The version which this job description conforms to. Used when processing
op-digest.
|
transition-key
|
A concatenation of the job’s graph action number, the graph number, the expected result and the UUID of the crmd instance that scheduled it. This is used to construct
transition-magic (below).
|
transition-magic
|
A concatenation of the job’s
op-status, rc-code and transition-key. Guaranteed to be unique for the life of the cluster (which ensures it is part of CIB update notifications) and contains all the information needed for the crmd to correctly analyze and process the completed job. Most importantly, the decomposed elements tell the crmd if the job entry was expected and whether it failed.
|
op-digest
|
An MD5 sum representing the parameters passed to the job. Used to detect changes to the configuration, to restart resources if necessary.
|
crm-debug-origin
|
The origin of the current values. For diagnostic purposes.
|
Example 14.4. A monitor operation (determines current state of the apcstonith resource)
<lrm_resource id="apcstonith" type="apcmastersnmp" class="stonith"> <lrm_rsc_op id="apcstonith_monitor_0" operation="monitor" call-id="2" rc-code="7" op-status="0" interval="0" crm-debug-origin="do_update_resource" crm_feature_set="3.0.1" op-digest="2e3da9274d3550dc6526fb24bfcbcba0" transition-key="22:2:7:2668bbeb-06d5-40f9-936d-24cb7f87006a" transition-magic="0:7;22:2:7:2668bbeb-06d5-40f9-936d-24cb7f87006a" last-run="1239008085" last-rc-change="1239008085" exec-time="10" queue-time="0"/> </lrm_resource>
apcstonith resource.
transition-key, we can see that this was the 22nd action of the 2nd graph produced by this instance of the crmd (2668bbeb-06d5-40f9-936d-24cb7f87006a).
transition-key contains a 7, which indicates that the job expects to find the resource inactive. By looking at the rc-code property, we see that this was the case.
Example 14.5. Resource history of a pingd clone with multiple jobs
<lrm_resource id="pingd:0" type="pingd" class="ocf" provider="pacemaker"> <lrm_rsc_op id="pingd:0_monitor_30000" operation="monitor" call-id="34" rc-code="0" op-status="0" interval="30000" crm-debug-origin="do_update_resource" crm_feature_set="3.0.1" transition-key="10:11:0:2668bbeb-06d5-40f9-936d-24cb7f87006a" ... last-run="1239009741" last-rc-change="1239009741" exec-time="10" queue-time="0"/> <lrm_rsc_op id="pingd:0_stop_0" operation="stop" crm-debug-origin="do_update_resource" crm_feature_set="3.0.1" call-id="32" rc-code="0" op-status="0" interval="0" transition-key="11:11:0:2668bbeb-06d5-40f9-936d-24cb7f87006a" ... last-run="1239009741" last-rc-change="1239009741" exec-time="10" queue-time="0"/> <lrm_rsc_op id="pingd:0_start_0" operation="start" call-id="33" rc-code="0" op-status="0" interval="0" crm-debug-origin="do_update_resource" crm_feature_set="3.0.1" transition-key="31:11:0:2668bbeb-06d5-40f9-936d-24cb7f87006a" ... last-run="1239009741" last-rc-change="1239009741" exec-time="10" queue-time="0" /> <lrm_rsc_op id="pingd:0_monitor_0" operation="monitor" call-id="3" rc-code="0" op-status="0" interval="0" crm-debug-origin="do_update_resource" crm_feature_set="3.0.1" transition-key="23:2:7:2668bbeb-06d5-40f9-936d-24cb7f87006a" ... last-run="1239008085" last-rc-change="1239008085" exec-time="20" queue-time="0"/> </lrm_resource>
call-id before interpreting them.
call-id of 3
call-id of 32
call-id of 33
call-id of 34
stop operation with a lower call-id than that of the start operation, we can conclude that the resource has been restarted. Specifically this occurred as part of actions 11 and 31 of transition 11 from the crmd instance with the key 2668bbeb…. This information can be helpful for locating the relevant section of the logs when looking for the source of a failure.
date command to print a human-readable version of any seconds-since-epoch value, for example date -d @1239009742.
Table of Contents
rsc_ticket constraints. Only if the ticket is available at a site can the respective resources be started there. Vice versa, if the ticket is revoked, the resources depending on that ticket must be stopped.
have-quorum flag as a special, cluster-wide ticket that is granted in case of node majority.)
true (the site has the ticket) or false (the site does not have the ticket). The absence of a certain ticket (during the initial state of the multi-site cluster) is the same as the value false.
loss-policy="fence" in rsc_ticket constraints.
rsc_ticket constraint lets you specify the resources depending on a certain ticket. Together with the constraint, you can set a loss-policy that defines what should happen to the respective resources if the ticket is revoked.
loss-policy can have the following values:
fence: Fence the nodes that are running the relevant resources.
stop: Stop the relevant resources.
freeze: Do nothing to the relevant resources.
demote: Demote relevant resources that are running in master mode to slave mode.
Example 15.1. Constraint that fences node if ticketA is revoked
<rsc_ticket id="rsc1-req-ticketA" rsc="rsc1" ticket="ticketA" loss-policy="fence"/>
rsc1-req-ticketA. It defines that the resource rsc1 depends on ticketA and that the node running the resource should be fenced if ticketA is revoked.
rsc1 were a multi-state resource (i.e. it could run in master or slave mode), you might want to configure that only master mode depends on ticketA. With the following configuration, rsc1 will be demoted to slave mode if ticketA is revoked:
Example 15.2. Constraint that demotes rsc1 if ticketA is revoked
<rsc_ticket id="rsc1-req-ticketA" rsc="rsc1" rsc-role="Master" ticket="ticketA" loss-policy="demote"/>
rsc_ticket constraints to let multiple resources depend on the same ticket. However, rsc_ticket also supports resource sets (see Section 6.5, “Resource Sets”), so one can easily list all the resources in one rsc_ticket constraint instead.
Example 15.3. Ticket constraint for multiple resources
<rsc_ticket id="resources-dep-ticketA" ticket="ticketA" loss-policy="fence"> <resource_set id="resources-dep-ticketA-0" role="Started"> <resource_ref id="rsc1"/> <resource_ref id="group1"/> <resource_ref id="clone1"/> </resource_set> <resource_set id="resources-dep-ticketA-1" role="Master"> <resource_ref id="ms1"/> </resource_set> </rsc_ticket>
rsc_ticket constraint. There’s no dependency between the two resource sets, and there’s no dependency among the resources within a resource set. Each of the resources just depends on ticketA.
rsc_ticket constraints, and even referencing them within resource sets, is also supported.
rsc_ticket.
crm_ticket command line tool to grant and revoke tickets.
# crm_ticket --ticket ticketA --grant
# crm_ticket --ticket ticketA --revoke
Important
crm_ticket command with great care, because it cannot check whether the same ticket is already granted elsewhere.
boothd.
Boothd at each site connects to its peers running at the other sites and exchanges connectivity details. Once a ticket is granted to a site, the booth mechanism will manage the ticket automatically: If the site which holds the ticket is out of service, the booth daemons will vote which of the other sites will get the ticket. To protect against brief connection failures, sites that lose the vote (either explicitly or implicitly by being disconnected from the voting body) need to relinquish the ticket after a time-out. Thus, it is made sure that a ticket will only be re-distributed after it has been relinquished by the previous site. The resources that depend on that ticket will fail over to the new site holding the ticket. The nodes that have run the resources before will be treated according to the loss-policy you set within the rsc_ticket constraint.
booth command-line tool. After you have initially granted a ticket to a site, boothd will take over and manage the ticket automatically.
Important
booth command-line tool can be used to grant, list, or revoke tickets and can be run on any machine where boothd is running. If you are managing tickets via Booth, use only booth for manual intervention, not crm_ticket. That ensures the same ticket will only be owned by one cluster site at a time.
# crm_ticket --info
# crm_mon --tickets
rsc_ticket constraints that apply to a ticket:
# crm_ticket --ticket ticketA --constraints
loss-policy="fence", the dependent resources could not be gracefully stopped/demoted, and other unrelated resources could even be affected.
# crm_ticket --ticket ticketA --standby
# crm_ticket --ticket ticketA --activate
Table of Contents
/usr/lib/ocf/resource.d/ so that they are not confused with (or overwritten by) the agents shipped by existing providers.
/usr/lib/ocf/resource.d/bigCorp/bigApp and define a resource:
<primitive id="custom-app" class="ocf" provider="bigCorp" type="bigApp"/>
Table B.1. Required Actions for OCF Agents
| Action | Description | Instructions |
|---|---|---|
start
|
Start the resource
| |
stop
|
Stop the resource
| |
monitor
|
Check the resource’s state
|
NOTE: The monitor script should test the state of the resource on the local machine only.
|
meta-data
|
Describe the resource
|
NOTE: This is not performed as root.
|
validate-all
|
Verify the supplied parameters
|
Table B.2. Optional Actions for OCF Resource Agents
| Action | Description | Instructions |
|---|---|---|
promote
|
Promote the local instance of a multi-state resource to the master (primary) state.
| |
demote
|
Demote the local instance of a multi-state resource to the slave (secondary) state.
| |
notify
|
Used by the cluster to send the agent pre- and post-notification events telling the resource what has happened and will happen.
|
recover, is not currently used by the cluster. It is intended to be a variant of the start action that tries to recover a resource locally.
Table B.3. Types of recovery performed by the cluster
| Type | Description | Action Taken by the Cluster |
|---|---|---|
soft
|
A transient error occurred
| |
hard
|
A non-transient error that may be specific to the current node occurred
| |
fatal
|
A non-transient error that will be common to all cluster nodes (e.g. a bad configuration was specified)
|
OCF_SUCCESS) can be considered to have failed, if 0 was not the expected return value.
Table B.4. OCF Return Codes and their Recovery Types
| RC | OCF Alias | Description | RT |
|---|---|---|---|
0
|
OCF_SUCCESS
|
soft
| |
1
|
OCF_ERR_GENERIC
|
soft
| |
2
|
OCF_ERR_ARGS
|
hard
| |
3
|
OCF_ERR_UNIMPLEMENTED
|
hard
| |
4
|
OCF_ERR_PERM
|
hard
| |
5
|
OCF_ERR_INSTALLED
|
hard
| |
6
|
OCF_ERR_CONFIGURED
|
fatal
| |
7
|
OCF_NOT_RUNNING
|
N/A
| |
8
|
OCF_RUNNING_MASTER
|
soft
| |
9
|
OCF_FAILED_MASTER
|
soft
| |
other
|
N/A
|
soft
|
multiple-active property (see Section 5.4, “Resource Options”).
OCF_ERR_UNIMPLEMENTED do not cause any type of recovery.
Table of Contents
/etc/corosync/corosync.conf.
Example C.1. Corosync 2.x configuration file for two nodes myhost1 and myhost2
totem {
version: 2
secauth: off
cluster_name: mycluster
transport: udpu
}
nodelist {
node {
ring0_addr: myhost1
nodeid: 1
}
node {
ring0_addr: myhost2
nodeid: 2
}
}
quorum {
provider: corosync_votequorum
two_node: 1
}
logging {
to_syslog: yes
}Example C.2. Corosync 2.x configuration file for three nodes myhost1, myhost2 and myhost3
totem {
version: 2
secauth: off
cluster_name: mycluster
transport: udpu
}
nodelist {
node {
ring0_addr: myhost1
nodeid: 1
}
node {
ring0_addr: myhost2
nodeid: 2
}
node {
ring0_addr: myhost3
nodeid: 3
}
}
quorum {
provider: corosync_votequorum
}
logging {
to_syslog: yes
}totem section defines what protocol version and options (including encryption) to use, [23] and gives the cluster a unique name (mycluster in these examples).
node section lists the nodes in this cluster. (See Section 4.2, “Where Pacemaker Gets the Node Name” for how this affects pacemaker.)
quorum section defines how the cluster uses quorum. The important thing is that two-node clusters must be handled specially, so two_node: 1 must be defined for two-node clusters (and only for two-node clusters).
logging section should be self-explanatory.
Example C.3. Corosync 1.x configuration file for a cluster with all nodes on the 192.0.2.0/24 network
totem {
version: 2
secauth: off
threads: 0
interface {
ringnumber: 0
bindnetaddr: 192.0.2.0
mcastaddr: 239.255.1.1
mcastport: 1234
}
}
logging {
fileline: off
to_syslog: yes
syslog_facility: daemon
}
amf {
mode: disabled
}totem section contains the protocol version and options as with 2.x. However, nodes are also listed here, in the interface section. The bindnetaddr option is usually the network address, thus allowing the same configuration file to be used on all nodes. IPv4 or IPv6 addresses can be used with corosync.
amf section refers to the Availability Management Framework and is not covered in this document.
Example C.4. Corosync 1._x_configuration fragment to enable Pacemaker plugin
aisexec {
user: root
group: root
}
service {
name: pacemaker
ver: 0
}lrmd in particular) have sufficient privileges to perform the actions requested of it. After all, a cluster manager that can’t add an IP address or start apache is of little use.
ha.cf configuration file.
ha.cf configuration file and restart Heartbeat:
Table of Contents
Table D.1. Upgrade Methods
| Method | Available between all versions | Can be used with Pacemaker Remote nodes | Service outage during upgrade | Service recovery during upgrade | Exercises failover logic | Allows change of messaging layer [a] |
|---|---|---|---|---|---|---|
|
yes
|
yes
|
always
|
N/A
|
no
|
yes
| |
|
no
|
yes
|
always [b]
|
yes
|
yes
|
no
| |
|
yes
|
no
|
only due to failure
|
no
|
no
|
yes
| |
[a]
For example, switching from Heartbeat to Corosync.
[b]
Any active resources will be moved off the node being upgraded, so there will be at least a brief outage unless all resources can be migrated "live".
| ||||||
crm_verify tool.
Warning
crm_verify tool.
Note
Table D.2. Version Compatibility Table
| Version being Installed | Oldest Compatible Version |
|---|---|
|
Pacemaker 1.x.y
|
Pacemaker 1.0.0
|
|
Pacemaker 0.7.x
|
Pacemaker 0.6 or Heartbeat 2.1.3
|
|
Pacemaker 0.6.x
|
Heartbeat 2.0.8
|
|
Heartbeat 2.1.3 (or less)
|
Heartbeat 2.0.4
|
|
Heartbeat 2.0.4 (or less)
|
Heartbeat 2.0.0
|
|
Heartbeat 2.0.0
|
None. Use an alternate upgrade strategy.
|
# crm_attribute --name maintenance-mode --update true
crm_verify tool.
# crm_attribute --name maintenance-mode --delete
Note
is-managed to false for all resources.
cibadmin --upgrade.
# crm_shadow --create shadow
# crm_verify --live-check
# cibadmin --upgrade
# crm_shadow --diff
# crm_shadow --edit
# crm_simulate --live-check --save-dotfile shadow.dot -S # graphviz shadow.dot
crm_simulate and graphviz.
# crm_shadow --commit shadow --force
Note
upgrade*.xsl conversion scripts provided with the source code. These will often be installed in a location such as /usr/share/pacemaker, or may be obtained from the source repository.
# xsltproc /path/to/upgrade06.xsl config06.xml > config10.xml
pacemaker.rng script (from the same location as the xsl files).
# xmllint --relaxng /path/to/pacemaker.rng config10.xml
Rules, instance_attributes, meta_attributes and sets of operations can be defined once and referenced in multiple places. See Section 11.2, “Reusing Rules, Options and Sets of Operations”
cibadmin help text.
master_slave was renamed to master
attributes container tag was removed
pre-req has been renamed requires
interval, start/stop must have it set to zero
stonith-enabled option now defaults to true.
stonith-enabled is true (or unset) and no STONITH resources have been defined
resource-failure-stickiness has been replaced by migration-threshold. See Section 9.3, “Handling Resource Failure”
crm_config. See Section 5.4.2, “Setting Global Defaults for Resource Meta-Attributes” and Section 5.5.3, “Setting Global Defaults for Operations” instead.
some_service is configured correctly and currently inactive, the following sequence will help you determine if it is LSB-compatible:
# /etc/init.d/some_service start ; echo "result: $?"
# /etc/init.d/some_service status ; echo "result: $?"
# /etc/init.d/some_service start ; echo "result: $?"
# /etc/init.d/some_service stop ; echo "result: $?"
# /etc/init.d/some_service status ; echo "result: $?"
# /etc/init.d/some_service stop ; echo "result: $?"
Table of Contents
Example F.1. An Empty Configuration
<cib crm_feature_set="3.0.7" validate-with="pacemaker-1.2" admin_epoch="1" epoch="0" num_updates="0"> <configuration> <crm_config/> <nodes/> <resources/> <constraints/> </configuration> <status/> </cib>
Example F.2. A simple configuration with two nodes, some cluster options and a resource
<cib crm_feature_set="3.0.7" validate-with="pacemaker-1.2" admin_epoch="1" epoch="0" num_updates="0"> <configuration> <crm_config> <cluster_property_set id="cib-bootstrap-options"> <nvpair id="option-1" name="symmetric-cluster" value="true"/> <nvpair id="option-2" name="no-quorum-policy" value="stop"/> <nvpair id="option-3" name="stonith-enabled" value="0"/> </cluster_property_set> </crm_config> <nodes> <node id="xxx" uname="c001n01" type="normal"/> <node id="yyy" uname="c001n02" type="normal"/> </nodes> <resources> <primitive id="myAddr" class="ocf" provider="heartbeat" type="IPaddr"> <operations> <op id="myAddr-monitor" name="monitor" interval="300s"/> </operations> <instance_attributes id="myAddr-params"> <nvpair id="myAddr-ip" name="ip" value="192.0.2.10"/> </instance_attributes> </primitive> </resources> <constraints> <rsc_location id="myAddr-prefer" rsc="myAddr" node="c001n01" score="INFINITY"/> </constraints> <rsc_defaults> <meta_attributes id="rsc_defaults-options"> <nvpair id="rsc-default-1" name="resource-stickiness" value="100"/> <nvpair id="rsc-default-2" name="migration-threshold" value="10"/> </meta_attributes> </rsc_defaults> <op_defaults> <meta_attributes id="op_defaults-options"> <nvpair id="op-default-1" name="timeout" value="30s"/> </meta_attributes> </op_defaults> </configuration> <status/> </cib>
c001n01 until either the resource fails 10 times or the host shuts down.
Example F.3. An advanced configuration with groups, clones and STONITH
<cib crm_feature_set="3.0.7" validate-with="pacemaker-1.2" admin_epoch="1" epoch="0" num_updates="0"> <configuration> <crm_config> <cluster_property_set id="cib-bootstrap-options"> <nvpair id="option-1" name="symmetric-cluster" value="true"/> <nvpair id="option-2" name="no-quorum-policy" value="stop"/> <nvpair id="option-3" name="stonith-enabled" value="true"/> </cluster_property_set> </crm_config> <nodes> <node id="xxx" uname="c001n01" type="normal"/> <node id="yyy" uname="c001n02" type="normal"/> <node id="zzz" uname="c001n03" type="normal"/> </nodes> <resources> <primitive id="myAddr" class="ocf" provider="heartbeat" type="IPaddr"> <operations> <op id="myAddr-monitor" name="monitor" interval="300s"/> </operations> <instance_attributes id="myAddr-attrs"> <nvpair id="myAddr-attr-1" name="ip" value="192.0.2.10"/> </instance_attributes> </primitive> <group id="myGroup"> <primitive id="database" class="lsb" type="oracle"> <operations> <op id="database-monitor" name="monitor" interval="300s"/> </operations> </primitive> <primitive id="webserver" class="lsb" type="apache"> <operations> <op id="webserver-monitor" name="monitor" interval="300s"/> </operations> </primitive> </group> <clone id="STONITH"> <meta_attributes id="stonith-options"> <nvpair id="stonith-option-1" name="globally-unique" value="false"/> </meta_attributes> <primitive id="stonithclone" class="stonith" type="external/ssh"> <operations> <op id="stonith-op-mon" name="monitor" interval="5s"/> </operations> <instance_attributes id="stonith-attrs"> <nvpair id="stonith-attr-1" name="hostlist" value="c001n01,c001n02"/> </instance_attributes> </primitive> </clone> </resources> <constraints> <rsc_location id="myAddr-prefer" rsc="myAddr" node="c001n01" score="INFINITY"/> <rsc_colocation id="group-with-ip" rsc="myGroup" with-rsc="myAddr" score="INFINITY"/> </constraints> <op_defaults> <meta_attributes id="op_defaults-options"> <nvpair id="op-default-1" name="timeout" value="30s"/> </meta_attributes> </op_defaults> <rsc_defaults> <meta_attributes id="rsc_defaults-options"> <nvpair id="rsc-default-1" name="resource-stickiness" value="100"/> <nvpair id="rsc-default-2" name="migration-threshold" value="10"/> </meta_attributes> </rsc_defaults> </configuration> <status/> </cib>
| Revision History | ||||
|---|---|---|---|---|
| Revision 1-0 | 19 Oct 2009 | |||
| ||||
| Revision 2-0 | 26 Oct 2009 | |||
| ||||
| Revision 3-0 | Tue Nov 12 2009 | |||
| ||||
| Revision 4-0 | Mon Oct 8 2012 | |||
| ||||
| Revision 5-0 | Mon Feb 23 2015 | |||
| ||||
| Revision 6-0 | Tue Dec 8 2015 | |||
| ||||
| Revision 7-0 | Tue May 3 2016 | |||
| ||||
| Revision 7-1 | Fri Oct 28 2016 | |||
| ||||
| Revision 8-0 | Tue Oct 25 2016 | |||
| ||||
| Revision 9-0 | Tue Jul 11 2017 | |||
| ||||
| Revision 10-0 | Fri Oct 6 2017 | |||
| ||||