

Edition 1
[1] It is hoped however, that having understood the concepts explained here, that the functionality of these tools will also be more readily understood.
Table of Contents
List of Figures
List of Tables
List of Examples
multiplier is set to 1000)reload Operationreload OperationTable of Contents
Mono-spaced Bold
To see the contents of the filemy_next_bestselling_novelin your current working directory, enter thecat my_next_bestselling_novelcommand at the shell prompt and press Enter to execute the command.
Press Enter to execute the command.Press Ctrl+Alt+F2 to switch to the first virtual terminal. Press Ctrl+Alt+F1 to return to your X-Windows session.
mono-spaced bold. For example:
File-related classes includefilesystemfor file systems,filefor files, anddirfor directories. Each class has its own associated set of permissions.
Choose → → from the main menu bar to launch Mouse Preferences. In the Buttons tab, click the Left-handed mouse check box and click to switch the primary mouse button from the left to the right (making the mouse suitable for use in the left hand).To insert a special character into a gedit file, choose → → from the main menu bar. Next, choose → from the Character Map menu bar, type the name of the character in the Search field and click . The character you sought will be highlighted in the Character Table. Double-click this highlighted character to place it in the Text to copy field and then click the button. Now switch back to your document and choose → from the gedit menu bar.
Mono-spaced Bold ItalicProportional Bold Italic
To connect to a remote machine using ssh, typesshat a shell prompt. If the remote machine isusername@domain.nameexample.comand your username on that machine is john, typessh john@example.com.Themount -o remountcommand remounts the named file system. For example, to remount thefile-system/homefile system, the command ismount -o remount /home.To see the version of a currently installed package, use therpm -qcommand. It will return a result as follows:package.package-version-release
Publican is a DocBook publishing system.
mono-spaced roman and presented thus:
books Desktop documentation drafts mss photos stuff svn books_tests Desktop1 downloads images notes scripts svgs
mono-spaced roman but add syntax highlighting as follows:
package org.jboss.book.jca.ex1; import javax.naming.InitialContext; public class ExClient { public static void main(String args[]) throws Exception { InitialContext iniCtx = new InitialContext(); Object ref = iniCtx.lookup("EchoBean"); EchoHome home = (EchoHome) ref; Echo echo = home.create(); System.out.println("Created Echo"); System.out.println("Echo.echo('Hello') = " + echo.echo("Hello")); } }
Table of Contents
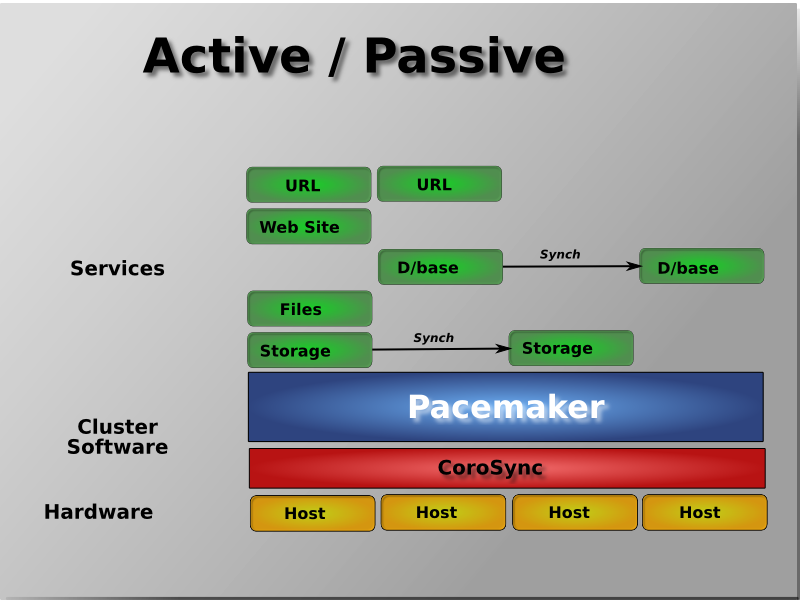
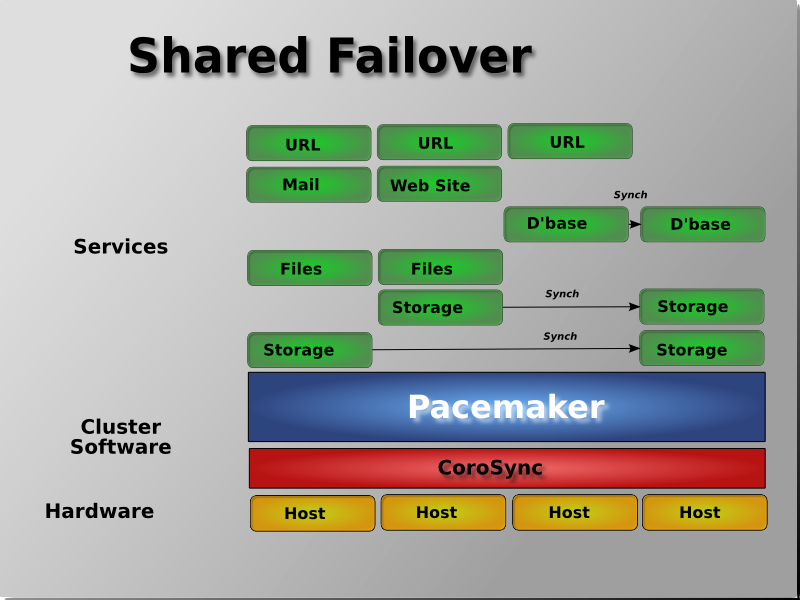
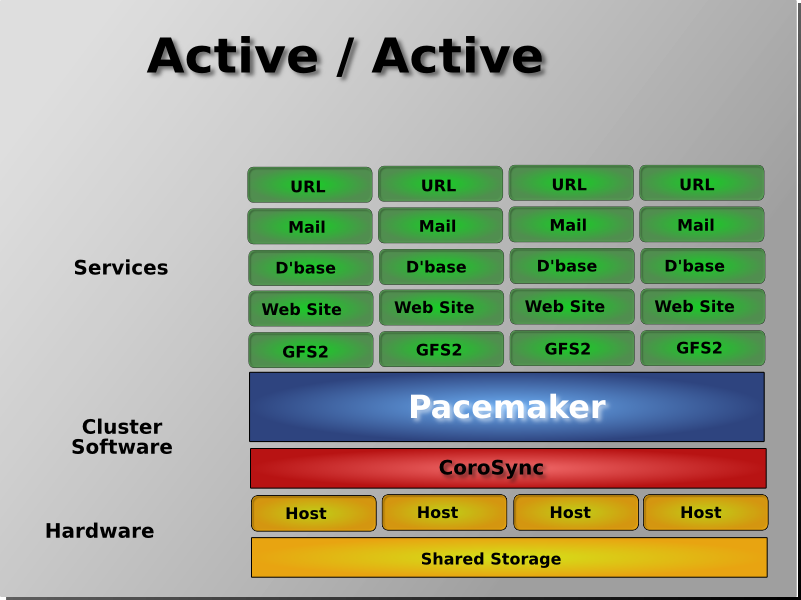
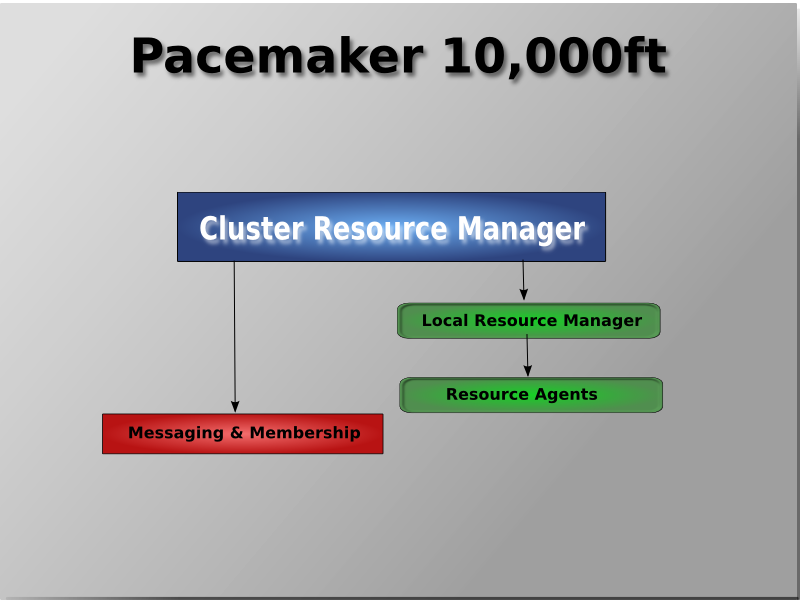
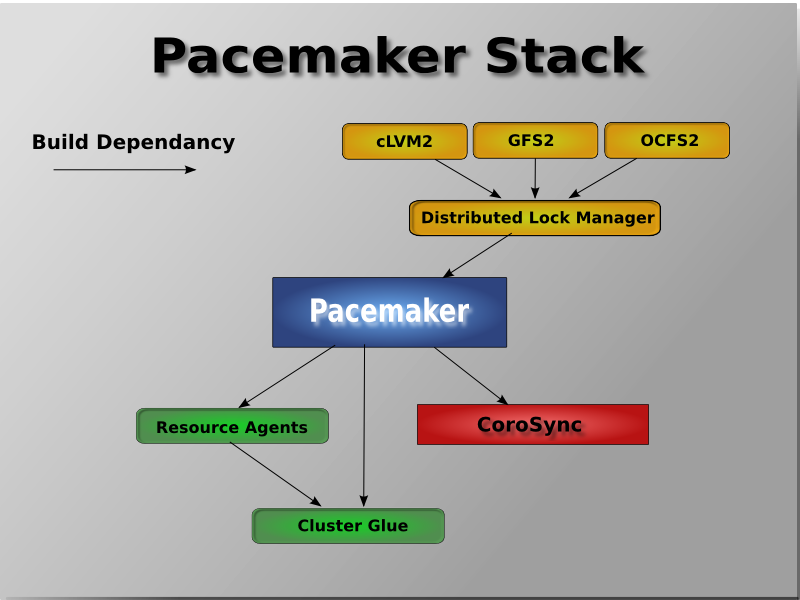
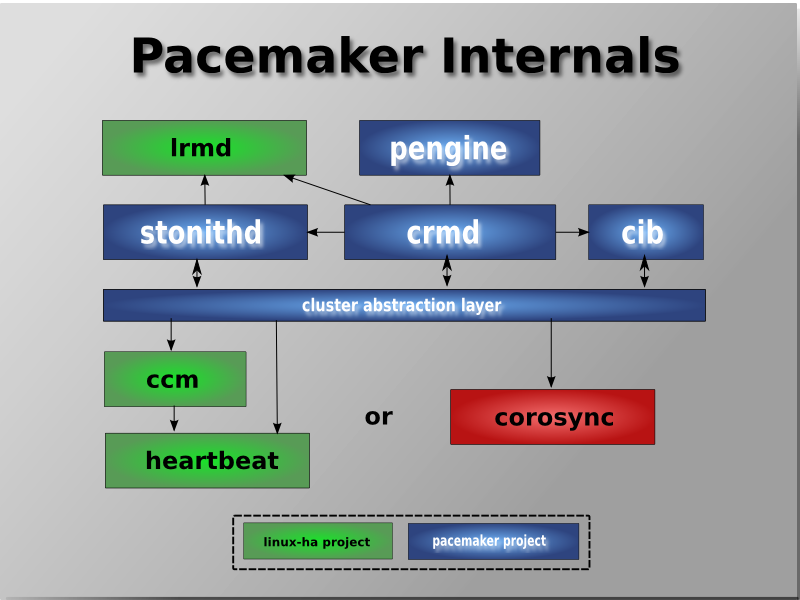
[2] It is hoped however, that having understood the concepts explained here, that the functionality of these tools will also be more readily understood.
[3] Even though Pacemaker also supports Heartbeat, the filesystems need to use the stack for messaging and membership and Corosync seems to be what they're standardizing on. Technically it would be possible for them to support Heartbeat as well, however there seems little interest in this.
Table of Contents
crm_config)
constraints)
<cib generated="true" admin_epoch="0" epoch="0" num_updates="0" have-quorum="false">
<configuration>
<crm_config/>
<nodes/>
<resources/>
<constraints/>
</configuration>
<status/>
</cib>
crm_mon utility that will display the current state of an active cluster. It can show the cluster status by node or by resource and can be used in either single-shot or dynamically-updating mode. There are also modes for displaying a list of the operations performed (grouped by node and resource) as well as information about failures.
crm_mon --help command.
# crm_mon
============
Last updated: Fri Nov 23 15:26:13 2007
Current DC: sles-3 (2298606a-6a8c-499a-9d25-76242f7006ec)
3 Nodes configured.
5 Resources configured.
============
Node: sles-1 (1186dc9a-324d-425a-966e-d757e693dc86): online
192.168.100.181 (heartbeat::ocf:IPaddr): Started sles-1
192.168.100.182 (heartbeat:IPaddr): Started sles-1
192.168.100.183 (heartbeat::ocf:IPaddr): Started sles-1
rsc_sles-1 (heartbeat::ocf:IPaddr): Started sles-1
child_DoFencing:2 (stonith:external/vmware): Started sles-1
Node: sles-2 (02fb99a8-e30e-482f-b3ad-0fb3ce27d088): standby
Node: sles-3 (2298606a-6a8c-499a-9d25-76242f7006ec): online
rsc_sles-2 (heartbeat::ocf:IPaddr): Started sles-3
rsc_sles-3 (heartbeat::ocf:IPaddr): Started sles-3
child_DoFencing:0 (stonith:external/vmware): Started sles-3
# crm_mon -n
============
Last updated: Fri Nov 23 15:26:13 2007
Current DC: sles-3 (2298606a-6a8c-499a-9d25-76242f7006ec)
3 Nodes configured.
5 Resources configured.
============
Node: sles-1 (1186dc9a-324d-425a-966e-d757e693dc86): online
Node: sles-2 (02fb99a8-e30e-482f-b3ad-0fb3ce27d088): standby
Node: sles-3 (2298606a-6a8c-499a-9d25-76242f7006ec): online
Resource Group: group-1
192.168.100.181 (heartbeat::ocf:IPaddr): Started sles-1
192.168.100.182 (heartbeat:IPaddr): Started sles-1
192.168.100.183 (heartbeat::ocf:IPaddr): Started sles-1
rsc_sles-1 (heartbeat::ocf:IPaddr): Started sles-1
rsc_sles-2 (heartbeat::ocf:IPaddr): Started sles-3
rsc_sles-3 (heartbeat::ocf:IPaddr): Started sles-3
Clone Set: DoFencing
child_DoFencing:0 (stonith:external/vmware): Started sles-3
child_DoFencing:1 (stonith:external/vmware): Stopped
child_DoFencing:2 (stonith:external/vmware): Started sles-1cibadmin --query > tmp.xmlvi tmp.xmlcibadmin --replace --xml-file tmp.xml
cibadmin --query --obj_type resources > tmp.xmlvi tmp.xmlcibadmin --replace --obj_type resources --xml-file tmp.xml
# cibadmin -Q | grep stonith
<nvpair id="cib-bootstrap-options-stonith-action" name="stonith-action" value="reboot"/>
<nvpair id="cib-bootstrap-options-stonith-enabled" name="stonith-enabled" value="1"/>
<primitive id="child_DoFencing" class="stonith" type="external/vmware">
<lrm_resource id="child_DoFencing:0" type="external/vmware" class="stonith">
<lrm_resource id="child_DoFencing:0" type="external/vmware" class="stonith">
<lrm_resource id="child_DoFencing:1" type="external/vmware" class="stonith">
<lrm_resource id="child_DoFencing:0" type="external/vmware" class="stonith">
<lrm_resource id="child_DoFencing:2" type="external/vmware" class="stonith">
<lrm_resource id="child_DoFencing:0" type="external/vmware" class="stonith">
<lrm_resource id="child_DoFencing:3" type="external/vmware" class="stonith">
primitive and child_DoFencing). Then simply execute:
cibadmin --delete --crm_xml ‘<primitive id="child_DoFencing"/>'
crm_attribute --attr-name stonith-enabled --attr-value true
crm_standby --get-value --node-uname somenode
crm_resource --locate --resource my-test-rsc
crm_shadow which creates a "shadow" copy of the configuration and arranges for all the command line tools to use it.
crm_shadow and give it the name of a configuration to create [4] and be sure to follow the simple on-screen instructions.
#crm_shadow --create testSetting up shadow instance Type Ctrl-D to exit the crm_shadow shell shadow[test]: shadow[test] #crm_shadow --whichtest
crm_shadow options and commands, invoke it with the --help option.
shadow[test] #crm_failcount -G -r rsc_c001n01name=fail-count-rsc_c001n01 value=0 shadow[test] #crm_standby -v on -n c001n02shadow[test] #crm_standby -G -n c001n02name=c001n02 scope=nodes value=on shadow[test] #cibadmin --erase --forceshadow[test] #cibadmin --query<cib cib_feature_revision="1" validate-with="pacemaker-1.0" admin_epoch="0" crm_feature_set="3.0" have-quorum="1" epoch="112" dc-uuid="c001n01" num_updates="1" cib-last-written="Fri Jun 27 12:17:10 2008"> <configuration> <crm_config/> <nodes/> <resources/> <constraints/> </configuration> <status/> </cib> shadow[test] #crm_shadow --delete test --forceNow type Ctrl-D to exit the crm_shadow shell shadow[test] #exit#crm_shadow --whichNo shadow instance provided #cibadmin -Q<cib cib_feature_revision="1" validate-with="pacemaker-1.0" admin_epoch="0" crm_feature_set="3.0" have-quorum="1" epoch="110" dc-uuid="c001n01" num_updates="551"> <configuration> <crm_config> <cluster_property_set id="cib-bootstrap-options"> <nvpair id="cib-bootstrap-1" name="stonith-enabled" value="1"/> <nvpair id="cib-bootstrap-2" name="pe-input-series-max" value="30000"/>
crm_shadow --commit mytest --force), it is often advisable to simulate the effect of the changes with ptest. Eg.
ptest --live-check -VVVVV --save-graph tmp.graph --save-dotfile tmp.dot
tmp.graph and tmp.dot, both are representations of the same thing -- the cluster's response to your changes. In the graph file is stored the complete transition, containing a list of all the actions, their parameters and their pre-requisites. Because the transition graph is not terribly easy to read, the tool also generates a Graphviz dot-file representing the same information.
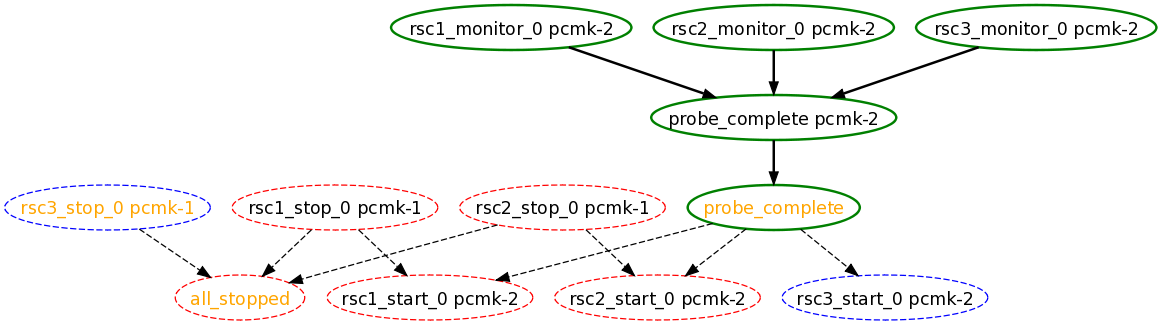
rsc_action_interval node
node2, has come online and that the cluster is checking to make sure rsc1, rsc2 and rsc3 are not already running there (Indicated by the *_monitor_0 entries). Once it did that, and assuming the resources were not active there, it would have liked to stop rsc1 and rsc2 on node1 and move them to node2. However, there appears to be some problem and the cluster cannot or is not permitted to perform the stop actions which implies it also cannot perform the start actions. For some reason the cluster does not want to start rsc3 anywhere.
ptest --help
Table of Contents
admin_epoch, epoch, num_updates) tuple to replace the configuration on all the nodes - which makes setting them and setting them correctly very important.
| Field | Description |
|---|---|
| admin_epoch |
Never modified by the cluster. Use this to make the configurations on any inactive nodes obsolete.
Never set this value to zero, in such cases the cluster cannot tell the difference between your configuration and the "empty" one used when nothing is found on disk.
|
| epoch | Incremented every time the configuration is updated (usually by the admin) |
| num_updates | Incremented every time the configuration or status is updated (usually by the cluster) |
| Field | Description |
|---|---|
| validate-with | Determines the type of validation being done on the configuration. If set to "none", the cluster will not verify that updates conform the the DTD (nor reject ones that don't). This option can be useful when operating a mixed version cluster during an upgrade. |
| Field | Description |
|---|---|
| crm-debug-origin | Indicates where the last update came from. Informational purposes only. |
| cib-last-written | Indicates when the configuration was last written to disk. Informational purposes only. |
| dc-uuid | Indicates which cluster node is the current leader. Used by the cluster when placing resources and determining the order of some events. |
| have-quorum | Indicates if the cluster has quorum. If false, this may mean that the cluster cannot start resources or fence other nodes. See no-quorum-policy below. |
admin_epoch, for example, one would use:
cibadmin --modify --crm_xml ‘<cib admin_epoch="42"/>'
<cib have-quorum="true" validate-with="pacemaker-1.0" admin_epoch="1" epoch="12" num_updates="65"
dc-uuid="ea7d39f4-3b94-4cfa-ba7a-952956daabee">
| Option | Default | Description |
|---|---|---|
| batch-limit | 30 | The number of jobs that the TE is allowed to execute in parallel. The "correct" value will depend on the speed and load of your network and cluster nodes. |
| no-quorum-policy | stop |
What to do when the cluster does not have quorum. Allowed values:
|
| symmetric-cluster | TRUE | Can all resources run on any node by default? |
| stonith-enabled | TRUE |
Should failed nodes and nodes with resources that can't be stopped be shot? If you value your data, set up a STONITH device and enable this.
If true, or unset, the cluster will refuse to start resources unless one or more STONITH resources have been configured also.
|
| stonith-action | reboot | Action to send to STONITH device. Allowed values: reboot, poweroff. |
| cluster-delay | 60s | Round trip delay over the network (excluding action execution). The "correct" value will depend on the speed and load of your network and cluster nodes. |
| stop-orphan-resources | TRUE | Should deleted resources be stopped |
| stop-orphan-actions | TRUE | Should deleted actions be cancelled |
| start-failure-is-fatal | TRUE | When set to FALSE, the cluster will instead use the resource's failcount and value for resource-failure-stickiness |
| pe-error-series-max | -1 (all) | The number of PE inputs resulting in ERRORs to save. Used when reporting problems. |
| pe-warn-series-max | -1 (all) | The number of PE inputs resulting in WARNINGs to save. Used when reporting problems. |
| pe-input-series-max | -1 (all) | The number of "normal" PE inputs to save. Used when reporting problems. |
crm_attribute --attr-name cluster-delay --get-value
crm_attribute --get-value -n cluster-delay
# crm_attribute --get-value -n cluster-delay
name=cluster-delay value=60s
# crm_attribute --get-value -n clusta-deway
name=clusta-deway value=(null)
Error performing operation: The object/attribute does not existcrm_attribute --attr-name cluster-delay --attr-value 30s
crm_attribute --attr-name cluster-delay --delete-attr
# crm_attribute --attr-name batch-limit --delete-attr
Multiple attributes match name=batch-limit in crm_config:
Value: 50 (set=cib-bootstrap-options, id=cib-bootstrap-options-batch-limit)
Value: 100 (set=custom, id=custom-batch-limit)
Please choose from one of the matches above and supply the 'id' with --attr-id[5] This will be described later in the section on Chapter 8, Rules where we will show how to have the cluster use different sets of options during working hours (when downtime is usually to be avoided at all costs) than it does during the weekends (when resources can be moved to the their preferred hosts without bothering end users)
Table of Contents
<node id="1186dc9a-324d-425a-966e-d757e693dc86" uname="pcmk-1" type="normal"/>
crm_attribute.
crm_attribute --type nodes --node-uname pcmk-1 --attr-name kernel --attr-value `uname -r`
<node uname="pcmk-1" type="normal" id="1186dc9a-324d-425a-966e-d757e693dc86">
<instance_attributes id="nodes-1186dc9a-324d-425a-966e-d757e693dc86">
<nvpair id="kernel-1186dc9a-324d-425a-966e-d757e693dc86" name="kernel" value="2.6.16.46-0.4-default"/>
</instance_attributes>
</node>
crm_attribute --type nodes --node-uname pcmk-1 --attr-name kernel --get-value
--type nodes the admin tells the cluster that this attribute is persistent. There are also transient attributes which are kept in the status section which are "forgotten" whenever the node rejoins the cluster. The cluster uses this area to store a record of how many times a resource has failed on that node but administrators can also read and write to this section by specifying --type status.
/etc/corosync/corosync.conf and /etc/ais/authkey (if it exists) from an existing node. You may need to modify the mcastaddr option to match the new node's IP address.
ha.cf, adding a new is as simple as installing heartbeat and copying ha.cf and authkeys from an existing node.
ha.cf and authkeys, you must use the hb_addnode command before starting the new node.
pcmk-1 in the example below).
crm_node -i
/etc/init.d/corosync stop
crm_node -R COROSYNC_ID
cibadmin --delete --obj_type nodes --crm_xml '<node uname="pcmk-1"/>'
cibadmin --delete --obj_type status --crm_xml '<node_state uname="pcmk-1"/>'
hb_delnode pcmk-1
cibadmin --delete --obj_type nodes --crm_xml '<node uname="pcmk-1"/>'
cibadmin --delete --obj_type status --crm_xml '<node_state uname="pcmk-1"/>'
/etc/corosync/corosync.conf and /etc/ais/authkey (if it exists) to the new node
/var/lib/heartbeat/hostcache
Table of Contents
OCF_RESKEY_. So, if you need to be given a parameter which the user thinks of as ip it will be passed to the script as OCF_RESKEY_ip. The number and purpose of the parameters is completely arbitrary, however your script should advertise any that it supports using the meta-data command.
/etc/init.d. Generally they are provided by the OS/distribution and in order to be used with the cluster, must conform to the LSB Spec.
| Field | Description |
|---|---|
| id | Your name for the resource |
| class | The standard the script conforms to. Allowed values: heartbeat, lsb, ocf, stonith |
| type | The name of the Resource Agent you wish to use. eg. IPaddr or Filesystem |
| provider | The OCF spec allows multiple vendors to supply the same ResourceAgent. To use the OCF resource agents supplied with Heartbeat, you should specify heartbeat here. |
crm_resource --resource Email --query-xml<primitive id="Email" class="lsb" type="exim"/>
<primitive id="Public-IP" class="ocf" type="IPaddr" provider="heartbeat">
<instance_attributes id="params-public-ip">
<nvpair id="public-ip-addr" name="ip" value="1.2.3.4"/>
</instance_attributes>
</primitive>
<primitive id="Public-IP-legacy" class="heartbeat" type="IPaddr">
<instance_attributes id="params-public-ip-legacy">
<nvpair id="public-ip-addr-legacy" name="1" value="1.2.3.4"/>
</instance_attributes>
</primitive>
--meta option of the crm_resource command.
| Field | Default | Description |
|---|---|---|
| priority | 0 | If not all resources can be active, the cluster will stop lower priority resources in order to keep higher priority ones active. |
| target-role | Started |
What state should the cluster attempt to keep this resource in? Allowed values:
|
| is-managed | TRUE | Is the cluster allowed to start and stop the resource? Allowed values: true, false |
| resource-stickiness | Inherited | How much does the resource prefer to stay where it is? Defaults to the value of resource-stickiness in the rsc_defaults section |
| migration-threshold | 0 (disabled) | How many failures should occur for this resource on a node before making the node ineligible to host this resource. |
| failure-timeout | 0 (disabled) | How many seconds to wait before acting as if the failure had not occurred (and potentially allowing the resource back to the node on which it failed. |
| multiple-active | stop_start |
What should the cluster do if it ever finds the resource active on more than one node. Allowed values:
|
crm_resource --meta --resource Email --set-parameter priority --property-value 100crm_resource --meta --resource Email --set-parameter multiple-active --property-value block
<primitive id="Email" class="lsb" type="exim">
<meta_attributes id="meta-email">
<nvpair id="email-priority" name="priority" value="100"/>
<nvpair id="email-active" name="multiple-active" value="block"/>
</meta_attributes>
</primitive>
rsc_defaults section with crm_attribute. Thus,
crm_attribute --type rsc_defaults --attr-name is-managed --attr-value false
is-managed set to true).
crm_resource command. For instance
crm_resource --resource Public-IP --set-parameter ip --property-value 1.2.3.4
<primitive id="Public-IP" class="ocf" type="IPaddr" provider="heartbeat">
<instance_attributes id="params-public-ip">
<nvpair id="public-ip-addr" name="ip" value="1.2.3.4"/>
</instance_attributes>
</primitive>
OCF_RESKEY_ip with a value of 1.2.3.4
meta-data command. The output contains an XML description of all the supported attributes, their purpose and default values.
export OCF_ROOT=/usr/lib/ocf; $OCF_ROOT/resource.d/pacemaker/Dummy meta-data
<?xml version="1.0"?>
<!DOCTYPE resource-agent SYSTEM "ra-api-1.dtd">
<resource-agent name="Dummy" version="0.9">
<version>1.0</version>
<longdesc lang="en-US">
This is a Dummy Resource Agent. It does absolutely nothing except
keep track of whether its running or not.
Its purpose in life is for testing and to serve as a template for RA writers.
</longdesc>
<shortdesc lang="en-US">Dummy resource agent</shortdesc>
<parameters>
<parameter name="state" unique="1">
<longdesc lang="en-US">
Location to store the resource state in.
</longdesc>
<shortdesc lang="en-US">State file</shortdesc>
<content type="string" default="/var/run//Dummy-{OCF_RESOURCE_INSTANCE}.state" />
</parameter>
<parameter name="dummy" unique="0">
<longdesc lang="en-US">
Dummy attribute that can be changed to cause a reload
</longdesc>
<shortdesc lang="en-US">Dummy attribute that can be changed to cause a reload</shortdesc>
<content type="string" default="blah" />
</parameter>
</parameters>
<actions>
<action name="start" timeout="90" />
<action name="stop" timeout="100" />
<action name="monitor" timeout="20" interval="10" depth="0" start-delay="0" />
<action name="reload" timeout="90" />
<action name="migrate_to" timeout="100" />
<action name="migrate_from" timeout="90" />
<action name="meta-data" timeout="5" />
<action name="validate-all" timeout="30" />
</actions>
</resource-agent>
<primitive id="Public-IP" class="ocf" type="IPaddr" provider="heartbeat">
<operations>
<op id="public-ip-check" name="monitor" interval="60s"/>
</operations>
<instance_attributes id="params-public-ip">
<nvpair id="public-ip-addr" name="ip" value="1.2.3.4"/>
</instance_attributes>
</primitive>
| Field | Description |
|---|---|
| id | Your name for the action. Must be unique. |
| name | The action to perform. Common values: monitor, start, stop |
| interval | How frequently (in seconds) to perform the operation. Default value: 0 |
| timeout | How long to wait before declaring the action has failed. |
| requires |
What conditions need to be satisfied before this action occurs. Allowed values:
STONITH resources default to nothing, and all others default to fencing if STONITH is enabled and quorum otherwise.
|
| on-fail |
The action to take if this action ever fails. Allowed values:
The default for the stop operation is fence when STONITH is enabled and block otherwise. All other operations default to stop.
|
| enabled | If false, the operation is treated as if it does not exist. Allowed values: true, false |
crm_attribute --type op_defaults --attr-name timeout --attr-value 20s
timeout, then that value would be used instead (for that operation only).
<primitive id="Public-IP" class="ocf" type="IPaddr" provider="heartbeat">
<operations>
<op id="public-ip-startup" name="monitor" interval="0" timeout="90s"/>
<op id="public-ip-start" name="start" interval="0" timeout="180s"/>
<op id="public-ip-stop" name="stop" interval="0" timeout="15min"/>
</operations>
<instance_attributes id="params-public-ip">
<nvpair id="public-ip-addr" name="ip" value="1.2.3.4"/>
</instance_attributes>
</primitive>
OCF_CHECK_LEVEL for this purpose and dictates that it is made available to the resource agent without the normal OCF_RESKEY_ prefix.
<primitive id="Public-IP" class="ocf" type="IPaddr" provider="heartbeat">
<operations>
<op id="public-ip-health-60" name="monitor" interval="60">
<instance_attributes id="params-public-ip-depth-60">
<nvpair id="public-ip-depth-60" name="OCF_CHECK_LEVEL" value="10"/>
</instance_attributes>
</op>
<op id="public-ip-health-300" name="monitor" interval="300">
<instance_attributes id="params-public-ip-depth-300">
<nvpair id="public-ip-depth-300" name="OCF_CHECK_LEVEL" value="20"/>
</instance_attributes>
</op>
</operations>
<instance_attributes id="params-public-ip">
<nvpair id="public-ip-level" name="ip" value="1.2.3.4"/>
</instance_attributes>
</primitive>
disabled="true" to the operation's definition.
<primitive id="Public-IP" class="ocf" type="IPaddr" provider="heartbeat">
<operations>
<op id="public-ip-check" name="monitor" interval="60s" disabled="true"/>
</operations>
<instance_attributes id="params-public-ip">
<nvpair id="public-ip-addr" name="ip" value="1.2.3.4"/>
</instance_attributes>
</primitive>
cibadmin -M -X ‘<op id="public-ip-check" disabled="true"/>'
cibadmin -M -X ‘<op id="public-ip-check" disabled="false"/>'
Table of Contents
INFINITY is currently defined as 1,000,000 and addition/subtraction with it follows the following 3 basic rules:
INFINITY = INFINITY
INFINITY = -INFINITY
INFINITY - INFINITY = -INFINITY
| Field | Description |
|---|---|
| id | A unique name for the constraint |
| rsc | A resource name |
| node | A node's uname |
| score |
Positive values indicate the resource can run on this node. Negative values indicate the resource can not run on this node. Values of +/- INFINITY change "can" to "must".
|
crm_attribute --attr-name symmetric-cluster --attr-value false
<constraints>
<rsc_location id="loc-1" rsc="Webserver" node="sles-1" score="200"/>
<rsc_location id="loc-2" rsc="Webserver" node="sles-3" score="0"/>
<rsc_location id="loc-3" rsc="Database" node="sles-2" score="200"/>
<rsc_location id="loc-4" rsc="Database" node="sles-3" score="0"/>
</constraints>
crm_attribute --attr-name symmetric-cluster --attr-value true
<constraints>
<rsc_location id="loc-1" rsc="Webserver" node="sles-1" score="200"/>
<rsc_location id="loc-2-dont-run" rsc="Webserver" node="sles-2" score="-INFINITY"/>
<rsc_location id="loc-3-dont-run" rsc="Database" node="sles-1" score="-INFINITY"/>
<rsc_location id="loc-4" rsc="Database" node="sles-2" score="200"/>
</constraints>
<constraints>
<rsc_location id="loc-1" rsc="Webserver" node="sles-1" score="INFINITY"/>
<rsc_location id="loc-2" rsc="Webserver" node="sles-2" score="INFINITY"/>
<rsc_location id="loc-3" rsc="Database" node="sles-1" score="500"/>
<rsc_location id="loc-4" rsc="Database" node="sles-2" score="300"/>
<rsc_location id="loc-5" rsc="Database" node="sles-2" score="200"/>
</constraints>
rsc_order constraints.
| Field | Description |
|---|---|
| id | A unique name for the constraint |
| first | The name of a resource that must be started before the then resource is allowed to. |
| then | The name of a resource. This resource will start after the first resource. |
| score | If greater than zero, the constraint is mandatory. Otherwise it is only a suggestion. Default value: INFINITY |
| symmetrical | If true, which is the default, stop the resources in the reverse order. Default value: true |
score="0" is specified for a constraint, the constraint is considered optional and only has an effect when both resources are stopping and or starting. Any change in state by the first resource will have no effect on the then resource.
<constraints>
<rsc_order id="order-1" first="Database" then="Webserver" />
<rsc_order id="order-2" first="IP" then="Webserver" score="0"/>
</constraints>
| Field | Description |
|---|---|
| id | A unique name for the constraint |
| rsc | The colocation source. If the constraint cannot be satisfied, the cluster may decide not to allow the resource to run at all. |
| with-rsc | The colocation target. The cluster will decide where to put this resource first and then decide where to put the resource in the rsc field |
| score |
Positive values indicate the resource should run on the same node. Negative values indicate the resources should not run on the same node. Values of +/- INFINITY change "should" to "must".
|
+INFINITY or -INFINITY. In such cases, if the constraint can't be satisfied, then the rsc resource is not permitted to run. For score=INFINITY, this includes cases where the with-rsc resource is not active.
<rsc_colocation id="colocate" rsc="resource1" with-rsc="resource2" score="INFINITY"/>
INFINITY was used, if resource2 can't run on any of the cluster nodes (for whatever reason) then resource1 will not be allowed to run.
score="-INFINITY"
<rsc_colocation id="anti-colocate" rsc="resource1" with-rsc="resource2" score="-INFINITY"/>
-INFINTY, the constraint is binding. So if the only place left to run is where resource2 already is, then resource1 may not run anywhere.
-INFINITY and less than INFINITY, the cluster will try and accommodate your wishes but may ignore them if the alternative is to stop some of the cluster resources.
<rsc_colocation id="colocate-maybe" rsc="resource1" with-rsc="resource2" score="500"/>
<constraints>
<rsc_order id="order-1" first="A" then="B" />
<rsc_order id="order-2" first="B" then="C" />
<rsc_order id="order-3" first="C" then="D" />
</constraints>

<constraints>
<rsc_order id="order-1">
<resource_set id="ordered-set-example" sequential="true">
<resource_ref id="A"/>
<resource_ref id="B"/>
<resource_ref id="C"/>
<resource_ref id="D"/>
</resource_set>
</rsc_order>
</constraints>
<group id="dummy">
<primitive id="A" .../>
<primitive id="B" .../>
<primitive id="C" .../>
<primitive id="D" .../>
</group>
<constraints>
<rsc_order id="order-1">
<resource_set id="ordered-set-1" sequential="false">
<resource_ref id="A"/>
<resource_ref id="B"/>
</resource_set>
<resource_set id="ordered-set-2" sequential="false">
<resource_ref id="C"/>
<resource_ref id="D"/>
</resource_set>
</rsc_order>
</constraints>
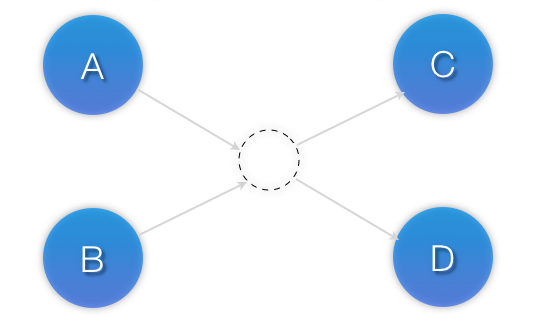
sequential="true") and there is no limit to the number of sets that can be specified.
<constraints>
<rsc_order id="order-1">
<resource_set id="ordered-set-1" sequential="false">
<resource_ref id="A"/>
<resource_ref id="B"/>
</resource_set>
<resource_set id="ordered-set-2" sequential="true">
<resource_ref id="C"/>
<resource_ref id="D"/>
</resource_set>
<resource_set id="ordered-set-3" sequential="false">
<resource_ref id="E"/>
<resource_ref id="F"/>
</resource_set>
</rsc_order>
</constraints>
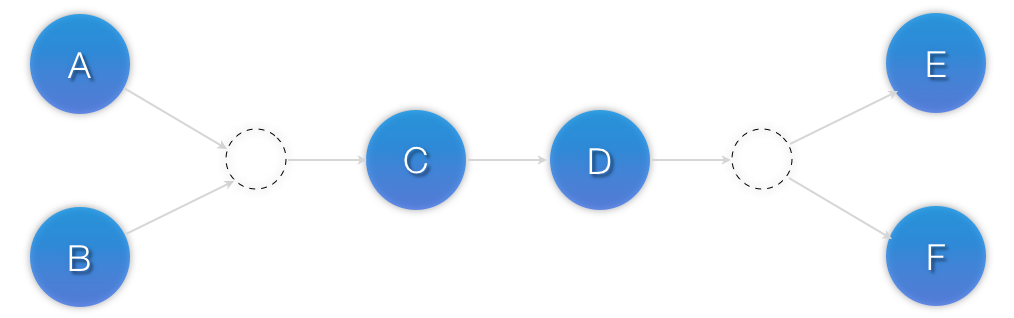
<constraints>
<rsc_colocation id="coloc-1" rsc="B" with-rsc="A" score="INFINITY"/>
<rsc_colocation id="coloc-2" rsc="C" with-rsc="B" score="INFINITY"/>
<rsc_colocation id="coloc-3" rsc="D" with-rsc="C" score="INFINITY"/>
</constraints>
<constraints>
<rsc_colocation id="coloc-1" score="INFINITY" >
<resource_set id="collocated-set-example" sequential="true">
<resource_ref id="A"/>
<resource_ref id="B"/>
<resource_ref id="C"/>
<resource_ref id="D"/>
</resource_set>
</rsc_colocation>
</constraints>
<group id="dummy">
<primitive id="A" .../>
<primitive id="B" .../>
<primitive id="C" .../>
<primitive id="D" .../>
</group>
<constraints>
<rsc_colocation id="coloc-1" score="INFINITY" >
<resource_set id="collocated-set-1" sequential="false">
<resource_ref id="A"/>
<resource_ref id="B"/>
<resource_ref id="C"/>
</resource_set>
<resource_set id="collocated-set-2" sequential="true">
<resource_ref id="D"/>
</resource_set>
</rsc_colocation>
</constraints>
sequential="true", then in order for member M to be active, member M+1 must also be active. You can even specify the role in which the members of a set must be in using the set's role attribute.
<constraints>
<rsc_colocation id="coloc-1" score="INFINITY" >
<resource_set id="collocated-set-1" sequential="true">
<resource_ref id="A"/>
<resource_ref id="B"/>
</resource_set>
<resource_set id="collocated-set-2" sequential="false">
<resource_ref id="C"/>
<resource_ref id="D"/>
<resource_ref id="E"/>
</resource_set>
<resource_set id="collocated-set-2" sequential="true" role="Master">
<resource_ref id="F"/>
<resource_ref id="G"/>
</resource_set>
</rsc_colocation>
</constraints>
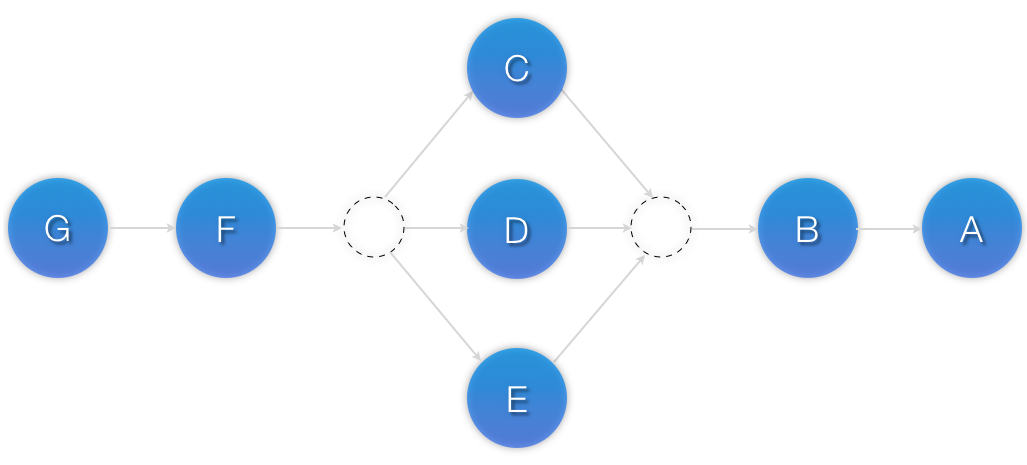
[8] While the human brain is sophisticated enough to read the constraint in any order and choose the correct one depending on the situation, the cluster is not quite so smart. Yet.
Table of Contents
| Field | Description |
|---|---|
| role | Limits the rule to only apply when the resource is in that role. Allowed values: Started, Slave, Master. NOTE: A rule with role="Master" can not determine the initial location of a clone instance. It will only affect which of the active instances will be promoted. |
| score | The score to apply if the rule evaluates to "true". Limited to use in rules that are part of location constraints. |
| score-attribute | The node attribute to look up and use as a score if the rule evaluates to "true". Limited to use in rules that are part of location constraints. |
| boolean-op | How to combine the result of multiple expression objects. Allowed values: and, or |
#uname that can also be used.
| Field | Description |
|---|---|
| value | User supplied value for comparison |
| attribute | The node attribute to test |
| type | Determines how the value(s) should be tested. Allowed values: integer, string, version |
| operation |
The comparison to perform. Allowed values:
|
date_spec and/or duration object depending on the context.
| Field | Description |
|---|---|
| start | A date/time conforming to the ISO8601 specification. |
| end | A date/time conforming to the ISO8601 specification. Can be inferred by supplying a value for start and a duration. |
| operation |
Compares the current date/time with the start and/or end date, depending on the context. Allowed values:
|
date_spec) include the time, the eq, neq, gte and lte operators have not been implemented.
date_spec objects are used to create cron-like expressions relating to time. Each field can contain a single number or a single range. Instead of defaulting to zero, any field not supplied is ignored.
monthdays="1" matches the first day of every month and hours="09-17" matches the hours between 9am and 5pm inclusive). However at this time one cannot specify weekdays="1,2" or weekdays="1-2,5-6" since they contain multiple ranges. Depending on demand, this may be implemented in a future release.
| Field | Description |
|---|---|
| id | A unique name for the date |
| hours | Allowed values: 0-23 |
| monthdays | Allowed values: 0-31 (depending on current month and year) |
| weekdays | Allowed values: 1-7 (1=Monday, 7=Sunday) |
| yeardays | Allowed values: 1-366 (depending on the current year) |
| months | Allowed values: 1-12 |
| weeks | Allowed values: 1-53 (depending on weekyear) |
| years | Year according the Gregorian calendar |
| weekyears |
May differ from Gregorian years.
Eg. "2005-001 Ordinal" is also "2005-01-01 Gregorian" is also "2004-W53-6 Weekly"
|
| moon | Allowed values: 0..7 (0 is new, 4 is full moon). Seriously, you can use this. This was implemented to demonstrate the ease with which new comparisons could be added. |
date_spec objects but without the limitations (ie. you can have a duration of 19 days). Like date_specs, any field not supplied is ignored.
<rule id="rule1">
<date_expression id="date_expr1" start="2005-001" operation="in_range">
<duration years="1"/>
</date_expression>
</rule>
<rule id="rule2">
<date_expression id="date_expr2" operation="date_spec">
<date_spec years="2005"/>
</date_expression>
</rule>
<rule id="rule3">
<date_expression id="date_expr3" operation="date_spec">
<date_spec hours="9-16" days="1-5"/>
</date_expression>
</rule>
<rule id="rule4" boolean_op="or">
<date_expression id="date_expr4-1" operation="date_spec">
<date_spec hours="9-16" days="1-5"/>
</date_expression>
<date_expression id="date_expr4-2" operation="date_spec">
<date_spec days="6"/>
</date_expression>
</rule>
<rule id="rule5" boolean_op="and">
<rule id="rule5-nested1" boolean_op="or">
<date_expression id="date_expr5-1" operation="date_spec">
<date_spec hours="9-16"/>
</date_expression>
<date_expression id="date_expr5-2" operation="date_spec">
<date_spec hours="21-23"/>
</date_expression>
</rule>
<date_expression id="date_expr5-3" operation="date_spec">
<date_spec days="1-5"/>
</date_expression>
</rule>
<rule id="rule6" boolean_op="and">
<date_expression id="date_expr6-1" operation="date_spec">
<date_spec weekdays="1"/>
</date_expression>
<date_expression id="date_expr6-2" operation="in_range" start="2005-03-01" end="2005-04-01"/>
</rule>
<rule id="rule7" boolean_op="and">
<date_expression id="date_expr7" operation="date_spec">
<date_spec weekdays="5" monthdays="13" moon="4"/>
</date_expression>
</rule>
<rsc_location id="dont-run-apache-on-c001n03" rsc="myApacheRsc" score="-INFINITY" node="c001n03"/>
<rsc_location id="dont-run-apache-on-c001n03" rsc="myApacheRsc">
<rule id="dont-run-apache-rule" score="-INFINITY">
<expression id="dont-run-apache-expr" attribute="#uname" operation="eq" value="c00n03"/>
</rule>
</rsc_location>
<nodes>
<node id="uuid1" uname="c001n01" type="normal">
<instance_attributes id="uuid1-custom_attrs">
<nvpair id="uuid1-cpu_mips" name="cpu_mips" value="1234"/>
</instance_attributes>
</node>
<node id="uuid2" uname="c001n02" type="normal">
<instance_attributes id="uuid2-custom_attrs">
<nvpair id="uuid2-cpu_mips" name="cpu_mips" value="5678"/>
</instance_attributes>
</node>
</nodes>
<rule id="need-more-power-rule" score="-INFINITY">
<expression id=" need-more-power-expr" attribute="cpu_mips" operation="lt" value="3000"/>
</rule>
score-attribute Instead of scorescore-attribute="cpu_mips", c001n01 would have its preference to run the resource increased by 1234 whereas c001n02 would have its preference increased by 5678.
instance_attributes objects for the resource and adding a rule to each, we can easily handle these special cases.
<primitive id="mySpecialRsc" class="ocf" type="Special" provider="me">
<instance_attributes id="special-node1" score="3">
<rule id="node1-special-case" score="INFINITY" >
<expression id="node1-special-case-expr" attribute="#uname" operation="eq" value="node1"/>
</rule>
<nvpair id="node1-interface" name="interface" value="eth1"/>
</instance_attributes>
<instance_attributes id="special-node2" score="2" >
<rule id="node2-special-case" score="INFINITY">
<expression id="node2-special-case-expr" attribute="#uname" operation="eq" value="node2"/>
</rule>
<nvpair id="node2-interface" name="interface" value="eth2"/>
<nvpair id="node2-port" name="port" value="8888"/>
</instance_attributes>
<instance_attributes id="defaults" score="1" >
<nvpair id="default-interface" name="interface" value="eth0"/>
<nvpair id="default-port" name="port" value="9999"/>
</instance_attributes>
</primitive>
instance_attributes objects are evaluated is determined by their score (highest to lowest). If not supplied, score defaults to zero and objects with an equal score are processed in listed order. If the instance_attributes object does not have a rule or has a rule that evaluates to true, then for any parameter the resource does not yet have a value for, the resource will use the parameter values defined by the instance_attributes object.
resource-stickiness value during and outside of work hours. This allows resources to automatically move back to their most preferred hosts, but at a time that (in theory) does not interfere with business activities.
<rsc_defaults>
<meta_attributes id="core-hours" score="2">
<rule id="core-hour-rule" score="0">
<date_expression id="nine-to-five-Mon-to-Fri" operation="date_spec">
<date_spec id="nine-to-five-Mon-to-Fri-spec" hours="9-17" weekdays="1-5"/>
</date_expression>
</rule>
<nvpair id="core-stickiness" name="resource-stickiness" value="INFINITY"/>
</meta_attributes>
<meta_attributes id="after-hours" score="1" >
<nvpair id="after-stickiness" name="resource-stickiness" value="0"/>
</meta_attributes>
</rsc_defaults>
cluster-recheck-interval option. This tells the cluster to periodically recalculate the ideal state of the cluster. For example, if you set cluster-recheck-interval=5m, then sometime between 9:00 and 9:05 the cluster would notice that it needs to start resource X, and between 17:00 and 17:05 it would realize it needed to be stopped.
Table of Contents
| Environment Variable | Description |
|---|---|
| CIB_user | The user to connect as. Needs to be part of the hacluster group on the target host. Defaults to $USER |
| CIB_passwd | The user's password. Read from the command line if unset |
| CIB_server | The host to contact. Defaults to localhost. |
| CIB_port | The port on which to contact the server. Required. |
| CIB_encrypted | Encrypt network traffic. Defaults to true. |
export CIB_port=1234; export CIB_server=c001n01; export CIB_user=someguy; cibadmin -Q
remote-tls-port (encrypted) or remote-clear-port (unencrypted) top-level options (ie. those kept in the cib tag , like num_updates and epoch).
| Field | Description |
|---|---|
| remote-tls-port | Listen for encrypted remote connections on this port. Default: none |
| remote-clear-port | Listen for plaintext remote connections on this port. Default: none |
interval-origin. The cluster uses this point to calculate the correct start-delay such that the operation will occur at origin + (interval * N).
interval-origin can be any date/time conforming to the ISO8601 standard. By way of example, to specify an operation that would run on the first Monday of 2009 and every Monday after that you would add:
<op id="my-weekly-action" name="custom-action" interval="P7D" interval-origin="2009-W01-1"/>
crm_standby. To check the standby status of the current machine, simply run:
crm_standby --get-value
--node-uname option. Eg.
crm_standby --get-value --node-uname sles-2
--attr-value instead of --get-value. Eg.
crm_standby --attr-value
--node-uname.
crm_resource command which creates and modifies the extra constraints for you. If Email was running on sles-1 and you wanted it moved to a specific location, the command would look something like:
crm_resource -M -r Email -H sles-2
<rsc_location rsc="Email" node="sles-2" score="INFINITY"/>
crm_resource -M are not cumulative. So if you ran:
crm_resource -M -r Email -H sles-2
crm_resource -M -r Email -H sles-3
crm_resource -U -r Email
crm_resource -U:
crm_resource -M -r Email -H sles-1
crm_resource -U -r Email
crm_resource -M -r Email
-INFINITY constraint will prevent the resource from running on that node until crm_resource -U is used. This includes the situation where every other cluster node is no longer available.
INFINITY, it is possible that you will end up with the problem described in Section 6.2.4, “What if Two Nodes Have the Same Score”. The tool can detect some of these cases and deals with them by also creating both a positive and negative constraint. Eg.
-INFINITY
INFINITY
migration-threshold=N for a resource and it will migrate to a new node after N failures. There is no threshold defined by default. To determine the resource's current failure status and limits, use crm_mon --failcounts
crm_failcount (after hopefully first fixing the failure's cause). However it is possible to expire them by setting the resource's failure-timeout option.
migration-threshold=2 and failure-timeout=60s would cause the resource to move to a new node after 2 failures and potentially allow it to move back (depending on the stickiness and constraint scores) after one minute.
INFINITY and thus always cause the resource to move immediately.
| Field | Description |
|---|---|
| dampen | The time to wait (dampening) for further changes occur. Use this to prevent a resource from bouncing around the cluster when cluster nodes notice the loss of connectivity at slightly different times. |
| multiplier | The number by which to multiply the number of connected ping nodes by. Useful when there are multiple ping nodes configured. |
| host_list | The machines to contact in order to determine the current connectivity status. Allowed values include resolvable DNS hostnames, IPv4 and IPv6 addresses. |
<clone id="Connected">
<primitive id="ping" provider="pacemaker" class="ocf" type="ping">
<instance_attributes id="ping-attrs">
<nvpair id="pingd-dampen" name="dampen" value="5s"/>
<nvpair id="pingd-multiplier" name="multiplier" value="1000"/>
<nvpair id="pingd-hosts" name="host_list" value="my.gateway.com www.bigcorp.com"/>
</instance_attributes>
<operations>
<op id="ping-monitor-60s" interval="60s" name="monitor"/>
</operations>
</primitive>
</clone>
<rsc_location id="WebServer-no-connectivity" rsc="Webserver">
<rule id="ping-exclude-rule" score="-INFINITY" >
<expression id="ping-exclude" attribute="pingd" operation="not_defined"/>
</rule>
</rsc_location>
multiplier is set to 1000)
<rsc_location id="WebServer-connectivity" rsc="Webserver">
<rule id="ping-prefer-rule" score="-INFINITY" >
<expression id="ping-prefer" attribute="pingd" operation="lt" value="3000"/>
</rule>
</rsc_location>
resource-stickiness (and don't set either of them to INFINITY).
<rsc_location id="WebServer-connectivity" rsc="Webserver">
<rule id="ping-prefer-rule" score-attribute="pingd" >
<expression id="ping-prefer" attribute="pingd" operation="defined"/>
</rule>
</rsc_location>
<rsc_location id="ping-1" rsc="Webserver" node="sles-1" score="5000"/> <rsc_location id="ping-2" rsc="Webserver" node="sles-2" score="2000"/>
<rsc_location id="WebServer-connectivity" rsc="Webserver">
<rule id="ping-exclude-rule" score="-INFINITY" >
<expression id="ping-exclude" attribute="pingd" operation="lt" value="3000"/>
</rule>
<rule id="ping-prefer-rule" score-attribute="pingd" >
<expression id="ping-prefer" attribute="pingd" operation="defined"/>
</rule>
</rsc_location>
migrate_to (performed on the current location) and migrate_from (performed on the destination).
migrate_to action and, if anything, the activation would occur during migrate_from.
migrate_to action is practically empty and migrate_from does most of the work, extracting the relevant resource state from the old location and activating it.
id-ref instead of an id.
<rsc_location id="WebServer-connectivity" rsc="Webserver">
<rule id="ping-prefer-rule" score-attribute="pingd" >
<expression id="ping-prefer" attribute="pingd" operation="defined"/>
</rule>
</rsc_location>
<rsc_location id="WebDB-connectivity" rsc="WebDB">
<rule id-ref="ping-prefer-rule"/>
</rsc_location>
rule exists somewhere. Attempting to add a reference to a non-existing rule will cause a validation failure, as will attempting to remove a rule that is referenced elsewhere.
meta_attributes and instance_attributes as illustrated in the example below
<primitive id="mySpecialRsc" class="ocf" type="Special" provider="me">
<instance_attributes id="mySpecialRsc-attrs" score="1" >
<nvpair id="default-interface" name="interface" value="eth0"/>
<nvpair id="default-port" name="port" value="9999"/>
</instance_attributes>
<meta_attributes id="mySpecialRsc-options">
<nvpair id="failure-timeout" name="failure-timeout" value="5m"/>
<nvpair id="migration-threshold" name="migration-threshold" value="1"/>
<nvpair id="stickiness" name="resource-stickiness" value="0"/>
</meta_attributes>
<operations id="health-checks">
<op id="health-check" name="monitor" interval="60s"/>
<op id="health-check" name="monitor" interval="30min"/>
</operations>
</primitive>
<primitive id="myOtherlRsc" class="ocf" type="Other" provider="me">
<instance_attributes id-ref="mySpecialRsc-attrs"/>
<meta_attributes id-ref="mySpecialRsc-options"/>
<operations id-ref="health-checks"/>
</primitive>
reload operation and perform any required actions.
reload Operation
case $1 in
start)
drbd_start
;;
stop)
drbd_stop
;;
reload)
drbd_reload
;;
monitor)
drbd_monitor
;;
*)
drbd_usage
exit $OCF_ERR_UNIMPLEMENTED
;;
esac
exit $?
reload operation in the actions section of its metadata
reload Operation
<?xml version="1.0"?>
<!DOCTYPE resource-agent SYSTEM "ra-api-1.dtd">
<resource-agent name="drbd">
<version>1.1</version>
<longdesc lang="en">
Master/Slave OCF Resource Agent for DRBD
</longdesc>
<shortdesc lang="en">
This resource agent manages a DRBD resource as a master/slave
resource. DRBD is a shared-nothing replicated storage device.
</shortdesc>
<parameters>
<parameter name="drbd_resource" unique="1" required="1">
<longdesc lang="en">The name of the drbd resource from the drbd.conf file.</longdesc>
<shortdesc lang="en">drbd resource name</shortdesc>
<content type="string"/>
</parameter>
<parameter name="drbdconf" unique="0">
<longdesc lang="en">Full path to the drbd.conf file.</longdesc>
<shortdesc lang="en">Path to drbd.conf</shortdesc>
<content type="string" default="${OCF_RESKEY_drbdconf_default}"/>
</parameter>
</parameters>
<actions>
<action name="start" timeout="240" />
<action name="reload" timeout="240" />
<action name="promote" timeout="90" />
<action name="demote" timeout="90" />
<action name="notify" timeout="90" />
<action name="stop" timeout="100" />
<action name="meta-data" timeout="5" />
<action name="validate-all" timeout="30" />
</actions>
</resource-agent>
reload.
unique set to 0 is eligable to be used in this way.
<parameter name="drbdconf" unique="0">
<longdesc lang="en">Full path to the drbd.conf file.</longdesc>
<shortdesc lang="en">Path to drbd.conf</shortdesc>
<content type="string" default="${OCF_RESKEY_drbdconf_default}"/>
</parameter>
unique=0
[9] The naming of this option was unfortunate as it is easily confused with true migration, the process of moving a resource from one node to another without stopping it. Xen virtual guests are the most common example of resources that can be migrated in this manner.
[10] The attribute name is customizable which allows multiple ping groups to be defined
Table of Contents
<group id="shortcut">
<primitive id="Public-IP" class="ocf" type="IPaddr" provider="heartbeat">
<instance_attributes id="params-public-ip">
<nvpair id="public-ip-addr" name="ip" value="1.2.3.4"/>
</instance_attributes>
</primitive>
<primitive id="Email" class="lsb" type="exim"/>
</group>
<configuration>
<resources>
<primitive id="Public-IP" class="ocf" type="IPaddr" provider="heartbeat">
<instance_attributes id="params-public-ip">
<nvpair id="public-ip-addr" name="ip" value="1.2.3.4"/>
</instance_attributes>
</primitive>
<primitive id="Email" class="lsb" type="exim"/>
</resources>
<constraints>
<rsc_colocation id="xxx" rsc="Email" with-rsc="Public-IP" score="INFINITY"/>
<rsc_order id="yyy" first="Public-IP" then="Email"/>
</constraints>
</configuration>
| Field | Description |
|---|---|
| id | Your name for the group |
priority, target-role, is-managed
<constraints>
<rsc_location id="group-prefers-node1" rsc="shortcut" node="node1" score="500"/>
<rsc_colocation id="webserver-with-group" rsc="Webserver" with-rsc="shortcut"/>
<rsc_order id="start-group-then-webserver" first="Webserver" then="shortcut"/>
</constraints>
resource-stickiness is 100 a group has seven members, five of which are active, then the group as a whole will prefer its current location with a score of 500.
<clone id="apache-clone">
<meta_attributes id="apache-clone-meta">
<nvpair id="apache-unique" name="globally-unique" value="false"/>
</meta_attributes>
<primitive id="apache" class="lsb" type="apache"/>
</clone>
| Field | Description |
|---|---|
| id | Your name for the clone |
priority, target-role, is-managed
| Field | Description |
|---|---|
| clone-max | How many copies of the resource to start. Defaults to the number of nodes in the cluster. |
| clone-node-max | How many copies of the resource can be started on a single node. Defaults to 1. |
| notify | When stopping or starting a copy of the clone, tell all the other copies beforehand and when the action was successful. Allowed values: true, false |
| globally-unique | Does each copy of the clone perform a different function? Allowed values: true, false |
| ordered | Should the copies be started in series (instead of in parallel). Allowed values: true, false |
| interleave | Changes the behavior of ordering constraints (between clones/masters) so that instances can start/stop as soon as their peer instance has (rather than waiting for every instance of the other clone has). Allowed values: true, false |
<constraints>
<rsc_location id="clone-prefers-node1" rsc="apache-clone" node="node1" score="500"/>
<rsc_colocation id="stats-with-clone" rsc="apache-stats" with="apache-clone"/>
<rsc_order id="start-clone-then-stats" first="apache-clone" then="apache-stats"/>
</constraints>
resource-stickiness is provided, the clone will use a value of 1. Being a small value, it causes minimal disturbance to the score calculations of other resources but is enough to prevent Pacemaker from needlessly moving copies around the cluster.
${OCF_SUCCESS} if the node has that exact instance active. All other probes for instances of the clone should result in ${OCF_NOT_RUNNING}. Unless of course they are failed, in which case they should return one of the other OCF error codes.
OCF_RESKEY_CRM_meta_clone_max environment variable and which copy it is by examining OCF_RESKEY_CRM_meta_clone.
OCF_RESKEY_CRM_meta_clone) about which copies are active. In particular, the list of active copies will not always be an unbroken sequence, nor always start at 0.
notify action to be implemented. Once supported, the notify action will be passed a number of extra variables which, when combined with additional context, can be used to calculate the current state of the cluster and what is about to happen to it.
| Variable | Description |
|---|---|
| OCF_RESKEY_CRM_meta_notify_type | Allowed values: pre, post |
| OCF_RESKEY_CRM_meta_notify_operation | Allowed values: start, stop |
| OCF_RESKEY_CRM_meta_notify_start_resource | Resources to be started |
| OCF_RESKEY_CRM_meta_notify_stop_resource | Resources to be stopped |
| OCF_RESKEY_CRM_meta_notify_active_resource | Resources the that are running |
| OCF_RESKEY_CRM_meta_notify_inactive_resource | Resources the that are not running |
| OCF_RESKEY_CRM_meta_notify_start_uname | Nodes on which resources will be started |
| OCF_RESKEY_CRM_meta_notify_stop_uname | Nodes on which resources will be stopped |
| OCF_RESKEY_CRM_meta_notify_active_uname | Nodes on which resources are running |
| OCF_RESKEY_CRM_meta_notify_inactive_uname | Nodes on which resources are not running |
OCF_RESKEY_CRM_meta_notify_start_resource and OCF_RESKEY_CRM_meta_notify_start_uname and should be treated as an array of whitespace separated elements.
OCF_RESKEY_CRM_meta_notify_start_resource="clone:0 clone:2 clone:3"
OCF_RESKEY_CRM_meta_notify_start_uname="sles-1 sles-3 sles-2"
| Field | Description |
|---|---|
| id | Your name for the multi-state resource |
priority, target-role, is-managed
clone-max, clone-node-max, notify, globally-unique, ordered, interleave
| Field | Description |
|---|---|
| master-max | How many copies of the resource can be promoted to master status. Defaults to 1. |
| master-node-max | How many copies of the resource can be promoted to master status on a single node. Defaults to 1. |
role="Master".
<master id="myMasterRsc">
<primitive id="myRsc" class="ocf" type="myApp" provider="myCorp">
<operations>
<op id="public-ip-slave-check" name="monitor" interval="60"/>
<op id="public-ip-master-check" name="monitor" interval="61" role="Master"/>
</operations>
</primitive>
</master>
rsc-role and/or with-rsc-role (for colocation constraints) and first-action and/or then-action (for ordering constraints) are used.
| Field | Description |
|---|---|
| rsc-role |
An additional attribute of colocation constraints that specifies the role that rsc must be in.
Allowed values: Started, Master, Slave
|
| with-rsc-role |
An additional attribute of colocation constraints that specifies the role that with-rsc must be in.
Allowed values: Started, Master, Slave
|
| first-action |
An additional attribute of ordering constraints that specifies the action that the first resource must complete before executing the specified action for the then resource.
Allowed values: start, stop, promote, demote
|
| then-action |
An additional attribute of ordering constraints that specifies the action that the then resource can only execute after the first-action on the first resource has completed.
Allowed values: start, stop, promote, demote. Defaults to the value (specified or implied) of first-action
|
with-rsc clone is (or will be) in the specified role. Allocation is then performed as-per-normal.
<constraints> <rsc_location id="db-prefers-node1" rsc="database" node="node1" score="500"/> <rsc_colocation id="backup-with-db-slave" rsc="backup" with-rsc="database" with-rsc-role="Slave"/> <rsc_colocation id="myapp-with-db-master" rsc="myApp" with-rsc="database" with-rsc-role="Master"/> <rsc_order id="start-db-before-backup" first="database" then="backup"/> <rsc_order id="promote-db-then-app" first="database" first-action="promote" then="myApp" then-action="start"/> </constraints>
resource-stickiness is provided, the clone will use a value of 1. Being a small value, it causes minimal disturbance to the score calculations of other resources but is enough to prevent Pacemaker from needlessly moving copies around the cluster.
crm_master utility. This tool automatically detects both the resource and host and should be used to set a preference for being promoted. Based on this, master-max, and master-node-max, the instance(s) with the highest preference will be promoted.
<rsc_location id="master-location" rsc="myMasterRsc">
<rule id="master-rule" score="100" role="Master">
<expression id="master-exp" attribute="#uname" operation="eq" value="node1"/>
</rule>
</rsc_location>
OCF_SUCCESS if they completed successfully or a relevant error code if they did not.
| Monitor Return Code | Description |
|---|---|
| OCF_NOT_RUNNING | Stopped |
| OCF_SUCCESS | Running (Slave) |
| OCF_RUNNING_MASTER | Running (Master) |
| OCF_FAILED_MASTER | Failed (Master) |
| Other | Failed (Slave) |
notify action to be implemented. Once supported, the notify action will be passed a number of extra variables which, when combined with additional context, can be used to calculate the current state of the cluster and what is about to happen to it.
| Variable | Description |
|---|---|
| OCF_RESKEY_CRM_meta_notify_type | Allowed values: pre, post |
| OCF_RESKEY_CRM_meta_notify_operation | Allowed values: start, stop |
| OCF_RESKEY_CRM_meta_notify_active_resource | Resources the that are running |
| OCF_RESKEY_CRM_meta_notify_inactive_resource | Resources the that are not running |
| OCF_RESKEY_CRM_meta_notify_master_resource | Resources that are running in Master mode |
| OCF_RESKEY_CRM_meta_notify_slave_resource | Resources that are running in Slave mode |
| OCF_RESKEY_CRM_meta_notify_start_resource | Resources to be started |
| OCF_RESKEY_CRM_meta_notify_stop_resource | Resources to be stopped |
| OCF_RESKEY_CRM_meta_notify_promote_resource | Resources to be promoted |
| OCF_RESKEY_CRM_meta_notify_demote_resource | Resources to be demoted |
| OCF_RESKEY_CRM_meta_notify_start_uname | Nodes on which resources will be started |
| OCF_RESKEY_CRM_meta_notify_stop_uname | Nodes on which resources will be stopped |
| OCF_RESKEY_CRM_meta_notify_promote_uname | Nodes on which resources will be promoted |
| OCF_RESKEY_CRM_meta_notify_demote_uname | Nodes on which resources will be demoted |
| OCF_RESKEY_CRM_meta_notify_active_uname | Nodes on which resources are running |
| OCF_RESKEY_CRM_meta_notify_inactive_uname | Nodes on which resources are not running |
| OCF_RESKEY_CRM_meta_notify_master_uname | Nodes on which resources are running in Master mode |
| OCF_RESKEY_CRM_meta_notify_slave_uname | Nodes on which resources are running in Slave mode |
[11] Variables in bold are specific to Master resources and all behave in the same manner as described for Clone resources.
Table of Contents
stonith -L
stonith -t type -n
lrmadmin -M stonith type pacemaker
type and a parameter for each of the values returned in step 2
cibadmin -C -o resources --xml-file stonith.xml
external/ibmrsa driver in step 2 and obtain the following list of parameters
stonith -t external/ibmrsa -nhostname ipaddr userid passwd type
<clone id="Fencing">
<meta_attributes id="fencing">
<nvpair id="Fencing-unique" name="globally-unique" value="false"/>
</meta_attributes>
<primitive id="rsa" class="stonith" type="external/ibmrsa">
<operations>
<op id="rsa-mon-1" name="monitor" interval="120s"/>
</operations>
<instance_attributes id="rsa-parameters">
<nvpair id="rsa-attr-1" name="hostname" value="node1 node2 node3 node4"/>
<nvpair id="rsa-attr-1" name="ipaddr" value="10.0.0.1"/>
<nvpair id="rsa-attr-1" name="userid" value="testuser"/>
<nvpair id="rsa-attr-1" name="passwd" value="abc123"/>
<nvpair id="rsa-attr-1" name="type" value="ibm"/>
</instance_attributes>
</primitive>
</clone>
Table of Contents
crm_mon. However for those with a curious inclination, the following attempts to proved an overview of its contents.
<node_state id="cl-virt-1" uname="cl-virt-2" ha="active" in_ccm="true" crmd="online" join="member" expected="member" crm-debug-origin="do_update_resource"> <transient_attributes id="cl-virt-1"/> <lrm id="cl-virt-1"/> </node_state>
| Dataset | Authoritative Source |
|---|---|
| node_state fields | crmd |
| transient_attributes tag | attrd |
| lrm tag | lrmd |
node_state objects are named as they are largely for historical reasons and are rooted in Pacemaker's origins as the Heartbeat resource manager. They have remained unchanged to preserve compatibility with older versions.
| Field | Description |
|---|---|
| id | Unique identifier for the node. Corosync based clusters use the same value as uname, Heartbeat cluster use a human-readable (but annoying) UUID. |
| uname | The node's machine name (output from uname -n) |
| ha | Is the cluster software active on the node. Allowed values: active, dead |
| in_ccm | Is the node part of the cluster's membership. Allowed values: true, false |
| crmd | Is the crmd process active on the node. Allowed values: online, offline |
| join | Is the node participating in hosting resources. Allowed values: down, pending, member, banned |
| expected | Expected value for join |
| crm-debug-origin | Diagnostic indicator. The origin of the most recent change(s). |
<transient_attributes id="cl-virt-1">
<instance_attributes id="status-cl-virt-1">
<nvpair id="status-cl-virt-1-pingd" name="pingd" value="3"/>
<nvpair id="status-cl-virt-1-probe_complete" name="probe_complete" value="true"/>
<nvpair id="status-cl-virt-1-fail-count-pingd:0" name="fail-count-pingd:0" value="1"/>
<nvpair id="status-cl-virt-1-last-failure-pingd:0" name="last-failure-pingd:0" value="1239009742"/>
</instance_attributes>
</transient_attributes>
Mon Apr 6 11:22:22 2009. [12] We also see that the node is connected to three "pingd" peers and that all known resources have been checked for on this machine (probe_complete).
lrm_resources tag (a child of the lrm tag). The information stored here includes enough information for the cluster to stop the resource safely if it is removed from the configuration section. Specifically we store the resource's id, class, type and provider.
<lrm_resource id="apcstonith" type="apcmastersnmp" class="stonith">
resource, action and interval. The concatenation of the values in this tuple are used to create the id of the lrm_rsc_op object.
| Field | Description |
|---|---|
| id | Identifier for the job constructed from the resource id, operation and interval. |
| call-id | The job's ticket number. Used as a sort key to determine the order in which the jobs were executed. |
| operation | The action the resource agent was invoked with. |
| interval | The frequency, in milliseconds, at which the operation will be repeated. 0 indicates a one-off job. |
| op-status | The job's status. Generally this will be either 0 (done) or -1 (pending). Rarely used in favor of rc-code. |
| rc-code | The job's result. Refer to Section B.3, “How Does the Cluster Interpret the OCF Return Codes?” for details on what the values here mean and how they are interpreted. |
| last-run | Diagnostic indicator. Machine local date/time, in seconds since epoch, at which the job was executed. |
| last-rc-change | Diagnostic indicator. Machine local date/time, in seconds since epoch, at which the job first returned the current value of rc-code |
| exec-time | Diagnostic indicator. Time, in seconds, that the job was running for |
| queue-time | Diagnostic indicator. Time, in seconds, that the job was queued for in the LRMd |
| crm_feature_set | The version which this job description conforms to. Used when processing op-digest |
| transition-key | A concatenation of the job's graph action number, the graph number, the expected result and the UUID of the crmd instance that scheduled it. This is used to construct transition-magic (below). |
| transition-magic | A concatenation of the job's op-status, rc-code and transition-key. Guaranteed to be unique for the life of the cluster (which ensures it is part of CIB update notifications) and contains all the information needed for the crmd to correctly analyze and process the completed job. Most importantly, the decomposed elements tell the crmd if the job entry was expected and whether it failed. |
| op-digest | An MD5 sum representing the parameters passed to the job. Used to detect changes to the configuration and restart resources if necessary. |
| crm-debug-origin | Diagnostic indicator. The origin of the current values. |
<lrm_resource id="apcstonith" type="apcmastersnmp" class="stonith">
<lrm_rsc_op id="apcstonith_monitor_0" operation="monitor" call-id="2" rc-code="7" op-status="0" interval="0"
crm-debug-origin="do_update_resource" crm_feature_set="3.0.1"
op-digest="2e3da9274d3550dc6526fb24bfcbcba0"
transition-key="22:2:7:2668bbeb-06d5-40f9-936d-24cb7f87006a"
transition-magic="0:7;22:2:7:2668bbeb-06d5-40f9-936d-24cb7f87006a"
last-run="1239008085" last-rc-change="1239008085" exec-time="10" queue-time="0"/>
</lrm_resource>
transition-key, we can see that this was the 22nd action of the 2nd graph produced by this instance of the crmd (2668bbeb-06d5-40f9-936d-24cb7f87006a). The third field of the transition-key contains a 7, this indicates that the job expects to find the resource inactive. By now looking at the rc-code property, we see that this was the case.
<lrm_resource id="pingd:0" type="pingd" class="ocf" provider="pacemaker">
<lrm_rsc_op id="pingd:0_monitor_30000" operation="monitor" call-id="34" rc-code="0" op-status="0" interval="30000"
crm-debug-origin="do_update_resource" crm_feature_set="3.0.1"
op-digest="a0f8398dac7ced82320fe99fd20fbd2f"
transition-key="10:11:0:2668bbeb-06d5-40f9-936d-24cb7f87006a"
transition-magic="0:0;10:11:0:2668bbeb-06d5-40f9-936d-24cb7f87006a"
last-run="1239009741" last-rc-change="1239009741" exec-time="10" queue-time="0"/>
<lrm_rsc_op id="pingd:0_stop_0" operation="stop"
crm-debug-origin="do_update_resource" crm_feature_set="3.0.1" call-id="32" rc-code="0" op-status="0" interval="0"
op-digest="313aee7c6aad26e290b9084427bbab60"
transition-key="11:11:0:2668bbeb-06d5-40f9-936d-24cb7f87006a"
transition-magic="0:0;11:11:0:2668bbeb-06d5-40f9-936d-24cb7f87006a"
last-run="1239009741" last-rc-change="1239009741" exec-time="10" queue-time="0"/>
<lrm_rsc_op id="pingd:0_start_0" operation="start" call-id="33" rc-code="0" op-status="0" interval="0"
crm-debug-origin="do_update_resource" crm_feature_set="3.0.1"
op-digest="313aee7c6aad26e290b9084427bbab60"
transition-key="31:11:0:2668bbeb-06d5-40f9-936d-24cb7f87006a"
transition-magic="0:0;31:11:0:2668bbeb-06d5-40f9-936d-24cb7f87006a"
last-run="1239009741" last-rc-change="1239009741" exec-time="10" queue-time="0" />
<lrm_rsc_op id="pingd:0_monitor_0" operation="monitor" call-id="3" rc-code="0" op-status="0" interval="0"
crm-debug-origin="do_update_resource" crm_feature_set="3.0.1"
op-digest="313aee7c6aad26e290b9084427bbab60"
transition-key="23:2:7:2668bbeb-06d5-40f9-936d-24cb7f87006a"
transition-magic="0:0;23:2:7:2668bbeb-06d5-40f9-936d-24cb7f87006a"
last-run="1239008085" last-rc-change="1239008085" exec-time="20" queue-time="0"/>
</lrm_resource>
call-id before interpret them. Once sorted, the above example can be summarized as:
stop operation with a lower call-id than that of the start operation, we can conclude that the resource has been restarted. Specifically this occurred as part of actions 11 and 31 of transition 11 from the crmd instance with the key 2668bbeb-06d5-40f9-936d-24cb7f87006a. This information can be helpful for locating the relevant section of the logs when looking for the source of a failure.
[12] You can use the following Perl one-liner to print a human readable of any seconds-since-epoch value:
perl -e 'print scalar(localtime($seconds))."\n"'
Table of Contents
/usr/lib/ocf/resource.d/provider.
/usr/lib/ocf/resource.d/ so that they are not confused with (or overwritten by) the agents shipped with Heartbeat. So, for example, if you chose the provider name of bigCorp and wanted a new resource named bigApp, you would create a script called /usr/lib/ocf/resource.d/bigCorp/bigApp and define a resource:
<primitive id="custom-app" class="ocf" provider="bigCorp" type="bigApp"/>
| Action | Description | Instructions |
|---|---|---|
| start | Start the resource | Return 0 on success and an appropriate error code otherwise. Must not report success until the resource is fully active. |
| stop | Stop the resource | Return 0 on success and an appropriate error code otherwise. Must not report success until the resource is fully stopped. |
| monitor | Check the resource's state |
Exit 0 if the resource is running, 7 if it is stopped and anything else if it is failed.
NOTE: The monitor script should test the state of the resource on the local machine only.
|
| meta-data | Describe the resource |
Provide information about this resource as an XML snippet. Exit with 0.
NOTE: This is not performed as root.
|
| validate-all | Verify the supplied parameters are correct | Exit with 0 if parameters are valid, 2 if not valid, 6 if resource is not configured. |
| Action | Description | Instructions |
|---|---|---|
| promote | Promote the local instance of a multi-state resource to the master/primary state | Return 0 on success |
| demote | Demote the local instance of a multi-state resource to the slave/secondary state | Return 0 on success |
| notify | Used by the cluster to send the agent pre and post notification events telling the resource what is or did just take place | Must not fail. Must exit 0 |
| Recovery Type | Description | Action Taken by the Cluster |
|---|---|---|
| soft | A transient error occurred | Restart the resource or move it to a new location |
| hard | A non-transient error that may be specific to the current node occurred | Move the resource elsewhere and prevent it from being retried on the current node |
| fatal | A non-transient error that will be common to all cluster nodes (I.e. a bad configuration was specified) | Stop the resource and prevent it from being started on any cluster node |
| OCF Return Code | OCF Alias | Description | Recovery Type |
|---|---|---|---|
| 0 | OCF_SUCCESS | Success. The command complete successfully. This is the expected result for all start, stop, promote and demote commands. | soft |
| 1 | OCF_ERR_GENERIC | Generic "there was a problem" error code. | soft |
| 2 | OCF_ERR_ARGS | The resource's configuration is not valid on this machine. Eg. Refers to a location/tool not found on the node. | hard |
| 3 | OCF_ERR_UNIMPLEMENTED | The requested action is not implemented. | hard |
| 4 | OCF_ERR_PERM | The resource agent does not have sufficient privileges to complete the task. | hard |
| 5 | OCF_ERR_INSTALLED | The tools required by the resource are not installed on this machine. | hard |
| 6 | OCF_ERR_CONFIGURED | The resource's configuration is invalid. Eg. A required parameters are missing. | fatal |
| 7 | OCF_NOT_RUNNING | The resource is safely stopped. The cluster will not attempt to stop a resource that returns this for any action. | N/A |
| 8 | OCF_RUNNING_MASTER | The resource is running in Master mode. | soft |
| 9 | OCF_FAILED_MASTER | The resource is in Master mode but has failed. The resource will be demoted, stopped and then started (and possibly promoted) again. | soft |
| other | NA | Custom error code. | soft |
OCF_SUCCESS) can be considered to have failed. This can happen when a resource that is expected to be in the Master state is found running as a Slave, or when a resource is found active on multiple machines..
multiple-active property of the resource
OCF_ERR_UNIMPLEMENTED do not cause any type of recovery
Table of Contents
Rules, instance_attributes, meta_attributes and sets of operations can be defined once and referenced in multiple places. See Section 9.4, “Reusing Rules, Options and Sets of Operations”
cibadmin help text.
master_slave was renamed to master
attributes container tag was removed
pre-req has been renamed requires
interval, start/stop must have it set to zero
stonith-enabled option now defaults to true.
stonith-enabled is true (or unset) and no STONITH resources have been defined
resource-failure-stickiness has been replaced by migration-threshold. See Section 9.3.2, “Moving Resources Due to Failure”
ha.cf Simply include the lists of hosts in your ping resource(s).
crm_config. See Section 5.5, “Setting Global Defaults for Resource Options” and Section 5.8, “Setting Global Defaults for Operations” instead.
Table of Contents
/etc/corosync/corosync.conf and an example for a machine with an address of 1.2.3.4 in a cluster communicating on port 1234 (without peer authentication and message encryption) is shown below.
totem {
version: 2
secauth: off
threads: 0
interface {
ringnumber: 0
bindnetaddr: 1.2.3.4
mcastaddr: 226.94.1.1
mcastport: 1234
}
}
logging {
fileline: off
to_syslog: yes
syslog_facility: daemon
}
amf {
mode: disabled
}
bindnetaddr: fec0::1:a800:4ff:fe00:20 mcastaddr: ff05::1
aisexec {
user: root
group: root
}
service {
name: pacemaker
ver: 0
}
ha.cf configuration file and restart Heartbeat
crm respawn
[13] Please consult the Corosync website and documentation for details on enabling encryption and peer authentication for the cluster.
Table of Contents
| Type | Available between all software versions | Service Outage During Upgrade | Service Recovery During Upgrade | Exercises Failover Logic/Configuration | Allows change of cluster stack type [a] |
|---|---|---|---|---|---|
| Shutdown | yes | always | N/A | no | yes |
| Rolling | no | always | yes | yes | no |
| Reattach | yes | only due to failure | no | no | yes |
[a] For example, switching from Heartbeat to Corosync. Consult the Heartbeat or Corosync documentation to see if upgrading them to a newer version is also supported | |||||
crm_verify tool if available.
crm_verify tool if available.
| Version being Installed | Oldest Compatible Version |
|---|---|
| Pacemaker 1.0.x | Pacemaker 1.0.0 |
| Pacemaker 0.7.x | Pacemaker 0.6 or Heartbeat 2.1.3 |
| Pacemaker 0.6.x | Heartbeat 2.0.8 |
| Heartbeat 2.1.3 (or less) | Heartbeat 2.0.4 |
| Heartbeat 2.0.4 (or less) | Heartbeat 2.0.0 |
| Heartbeat 2.0.0 | None. Use an alternate upgrade strategy. |
crm_attribute -t crm_config -n is-managed-default -v false
crm_resource -t primitive -r <rsc_id> -p is-managed -v false
crm_verify tool if available.
crm_attribute -t crm_config -n is-managed-default -v true
crm_resource -t primitive -r <rsc_id> -p is-managed -v false
Table of Contents
crm_shadow --create upgrade06
crm_verify --live-check
cibadmin --upgrade
crm_shadow --diff
crm_shadow --edit
EDITOR environment variable).
ptest -VVVVV --live-check --save-dotfile upgrade06.dot
graphviz upgrade06.dot
crm_shadow --commit upgrade06 --force
upgrade06.xsl conversion script or download the latest version from version control
xsltproc /path/tp/upgrade06.xsl config06.xml > config10.xml
pacemaker.rng script.
xmllint --relaxng /path/tp/pacemaker.rng config10.xml
[14] The most common reason is ID values being repeated or invalid. Pacemaker 1.0 is much stricter regarding this type of validation
/etc/init.d/some_service start ; echo "result: $?"
/etc/init.d/some_service status ; echo "result: $?"
/etc/init.d/some_service start ; echo "result: $?"
/etc/init.d/some_service stop ; echo "result: $?"
/etc/init.d/some_service status ; echo "result: $?"
/etc/init.d/some_service stop ; echo "result: $?"
Table of Contents
<cib admin_epoch="0" epoch="0" num_updates="0" have-quorum="false">
<configuration>
<crm_config/>
<nodes/>
<resources/>
<constraints/>
</configuration>
<status/>
</cib>
<cib admin_epoch="0" epoch="1" num_updates="0" have-quorum="false" validate-with="pacemaker-1.0">
<configuration>
<crm_config>
<nvpair id="option-1" name="symmetric-cluster" value="true"/>
<nvpair id="option-2" name="no-quorum-policy" value="stop"/>
</crm_config>
<op_defaults>
<nvpair id="op-default-1" name="timeout" value="30s"/>
</op_defaults>
<rsc_defaults>
<nvpair id="rsc-default-1" name="resource-stickiness" value="100"/>
<nvpair id="rsc-default-2" name="migration-threshold" value="10"/>
</rsc_defaults>
<nodes>
<node id="xxx" uname="c001n01" type="normal"/>
<node id="yyy" uname="c001n02" type="normal"/>
</nodes>
<resources>
<primitive id="myAddr" class="ocf" provider="heartbeat" type="IPaddr">
<operations>
<op id="myAddr-monitor" name="monitor" interval="300s"/>
</operations>
<instance_attributes>
<nvpair name="ip" value="10.0.200.30"/>
</instance_attributes>
</primitive>
</resources>
<constraints>
<rsc_location id="myAddr-prefer" rsc="myAddr" node="c001n01" score="INFINITY"/>
</constraints>
</configuration>
<status/>
</cib>
<cib admin_epoch="0" epoch="1" num_updates="0" have-quorum="false" validate-with="pacemaker-1.0">
<configuration>
<crm_config>
<nvpair id="option-1" name="symmetric-cluster" value="true"/>
<nvpair id="option-2" name="no-quorum-policy" value="stop"/>
<nvpair id="option-3" name="stonith-enabled" value="true"/>
</crm_config>
<op_defaults>
<nvpair id="op-default-1" name="timeout" value="30s"/>
</op_defaults>
<rsc_defaults>
<nvpair id="rsc-default-1" name="resource-stickiness" value="100"/>
<nvpair id="rsc-default-2" name="migration-threshold" value="10"/>
</rsc_defaults>
<nodes>
<node id="xxx" uname="c001n01" type="normal"/>
<node id="yyy" uname="c001n02" type="normal"/>
<node id="zzz" uname="c001n03" type="normal"/>
</nodes>
<resources>
<primitive id="myAddr" class="ocf" provider="heartbeat" type="IPaddr">
<operations>
<op id="myAddr-monitor" name="monitor" interval="300s"/>
</operations>
<instance_attributes>
<nvpair name="ip" value="10.0.200.30"/>
</instance_attributes>
</primitive>
<group id="myGroup">
<primitive id="database" class="lsb" type="oracle">
<operations>
<op id="database-monitor" name="monitor" interval="300s"/>
</operations>
</primitive>
<primitive id="webserver" class="lsb" type="apache">
<operations>
<op id="webserver-monitor" name="monitor" interval="300s"/>
</operations>
</primitive>
</group>
<clone id="STONITH">
<meta_attributes id="stonith-options">
<nvpair id="stonith-option-1" name="globally-unique" value="false"/>
</meta_attributes>
<primitive id="stonithclone" class="stonith" type="external/ssh">
<operations>
<op id="stonith-op-mon" name="monitor" interval="5s"/>
</operations>
<instance_attributes id="stonith-attrs">
<nvpair id="stonith-attr-1" name="hostlist" value="c001n01,c001n02"/>
</instance_attributes>
</primitive>
</clone>
</resources>
<constraints>
<rsc_location id="myAddr-prefer" rsc="myAddr" node="c001n01" score="INFINITY"/>
<rsc_colocation id="group-with-ip" rsc="myGroup" with-rsc="myAddr" score="INFINITY"/>
</constraints>
</configuration>
<status/>
</cib>
| Revision History | ||||
|---|---|---|---|---|
| Revision 1 | 19 Oct 2009 | |||
| ||||
| Revision 2 | 26 Oct 2009 | |||
| ||||
| Revision 3 | Tue Nov 12 2009 | |||
| ||||