Edizione 1
Sommario
Indice
Lista delle figure
Lista delle tabelle
lrm_rsc_op jobLista degli esempi
OCF_CHECK_LEVEL.resource_setsresource-stickiness during working hoursmultiplier is set to 1000:reload Operationreload implementata dall'agente DRBDcl-virt-1Indice
Neretto monospazio
Per visualizzare i contenuti del filemy_next_bestselling_novelnella vostra directory di lavoro corrente, inserire il comandocat my_next_bestselling_novelal prompt della shell e premere Invio per eseguire il comando.
Premere Invio per eseguire il comando.Premere Ctrl+Alt+F2 per usare un terminale virtuale.
neretto monospazio. Per esempio:
Le classi relative ad un file includonofilesystemper file system,fileper file, edirper directory. Ogni classe possiede il proprio set associato di permessi.
Selezionare → → dalla barra del menu principale per lanciare Preferenze del Mouse. Nella scheda Pulsanti, fate clic sulla casella di dialogo mouse per mancini, e successivamente fate clic su per cambiare il pulsante primario del mouse da sinistra a destra (rendendo così il mouse idoneo per un utilizzo con la mano sinistra).Per inserire un carattere speciale in un file gedit selezionare → → dalla barra del menu principale. Selezionare successivamente → dal menu Mappa del carattere, digitare il nome desiderato nel campo Cerca e selezionare . Il carattere desiderato sarà evidenziato nella Tabella dei caratteri. Eseguire un doppio clic sul carattere per poterlo posizionare nel campo Testo da copiare e successivamente fare clic sul pulsante . Ritornare sul documento e selezionare → dalla barra del menu di gedit.
Corsivo neretto monospazioCorsivo neretto proporzionale
Per collegarsi ad una macchina remota utilizzando ssh, digitaresshal prompt della shell. Se la macchina remota èusername@domain.nameexample.comed il nome utente sulla macchina interessata è john, digitaressh john@example.com.Il comandomount -o remountrimonta il file system indicato. Per esempio, per rimontare il file systemfile-system/home, il comando èmount -o remount /home.Per visualizzare la versione di un pacchetto attualmente installato, utilizzare il comandorpm -q. Esso ritornerà il seguente risultato:package.package-version-release
Publican è un sistema di pubblicazione per DocBook.
tondo monospazio e così presentato:
books Desktop documentation drafts mss photos stuff svn books_tests Desktop1 downloads images notes scripts svgs
tondo monospazio ma vengono presentati ed evidenziati nel modo seguente:
package org.jboss.book.jca.ex1; import javax.naming.InitialContext; public class ExClient { public static void main(String args[]) throws Exception { InitialContext iniCtx = new InitialContext(); Object ref = iniCtx.lookup("EchoBean"); EchoHome home = (EchoHome) ref; Echo echo = home.create(); System.out.println("Created Echo"); System.out.println("Echo.echo('Hello') = " + echo.echo("Hello")); } }
Nota
Importante
Avvertimento
Indice
Indice
crm_config)
constraints)
Esempio 2.1. Una configurazione vuota
<cib admin_epoch="0" epoch="0" num_updates="0" have-quorum="false"> <configuration> <crm_config/> <nodes/> <resources/> <constraints/> </configuration> <status/> </cib>
crm_mon utility that will display the current state of an active cluster. It can show the cluster status by node or by resource and can be used in either single-shot or dynamically-updating mode. There are also modes for displaying a list of the operations performed (grouped by node and resource) as well as information about failures.
crm_mon --help command.
Esempio 2.2. Esempio dell'output di crm_mon
============
Last updated: Fri Nov 23 15:26:13 2007
Current DC: sles-3 (2298606a-6a8c-499a-9d25-76242f7006ec)
3 Nodes configured.
5 Resources configured.
============
Node: sles-1 (1186dc9a-324d-425a-966e-d757e693dc86): online
192.168.100.181 (heartbeat::ocf:IPaddr): Started sles-1
192.168.100.182 (heartbeat:IPaddr): Started sles-1
192.168.100.183 (heartbeat::ocf:IPaddr): Started sles-1
rsc_sles-1 (heartbeat::ocf:IPaddr): Started sles-1
child_DoFencing:2 (stonith:external/vmware): Started sles-1
Node: sles-2 (02fb99a8-e30e-482f-b3ad-0fb3ce27d088): standby
Node: sles-3 (2298606a-6a8c-499a-9d25-76242f7006ec): online
rsc_sles-2 (heartbeat::ocf:IPaddr): Started sles-3
rsc_sles-3 (heartbeat::ocf:IPaddr): Started sles-3
child_DoFencing:0 (stonith:external/vmware): Started sles-3Esempio 2.3. Esempio dell'output di crm_mon -n
============
Last updated: Fri Nov 23 15:26:13 2007
Current DC: sles-3 (2298606a-6a8c-499a-9d25-76242f7006ec)
3 Nodes configured.
5 Resources configured.
============
Node: sles-1 (1186dc9a-324d-425a-966e-d757e693dc86): online
Node: sles-2 (02fb99a8-e30e-482f-b3ad-0fb3ce27d088): standby
Node: sles-3 (2298606a-6a8c-499a-9d25-76242f7006ec): online
Resource Group: group-1
192.168.100.181 (heartbeat::ocf:IPaddr): Started sles-1
192.168.100.182 (heartbeat:IPaddr): Started sles-1
192.168.100.183 (heartbeat::ocf:IPaddr): Started sles-1
rsc_sles-1 (heartbeat::ocf:IPaddr): Started sles-1
rsc_sles-2 (heartbeat::ocf:IPaddr): Started sles-3
rsc_sles-3 (heartbeat::ocf:IPaddr): Started sles-3
Clone Set: DoFencing
child_DoFencing:0 (stonith:external/vmware): Started sles-3
child_DoFencing:1 (stonith:external/vmware): Stopped
child_DoFencing:2 (stonith:external/vmware): Started sles-1cibadmin command which talks to a running cluster. With cibadmin, the user can query, add, remove, update or replace any part of the configuration; all changes take effect immediately, so there is no need to perform a reload-like operation.
Esempio 2.4. Utilizzare un editor per modificare la configurazione del cluster in sicurezza
# cibadmin --query > tmp.xml # vi tmp.xml # cibadmin --replace --xml-file tmp.xml
Esempio 2.5. Utilizzare in sicurezza un editor per modificare una sotto sezione della configurazione del cluster
# cibadmin --query --obj_type resources > tmp.xml # vi tmp.xml # cibadmin --replace --obj_type resources --xml-file tmp.xml
Esempio 2.6. Ricerca di oggetti relativi alla configurazione di STONITH
# cibadmin -Q | grep stonith<nvpair id="cib-bootstrap-options-stonith-action" name="stonith-action" value="reboot"/> <nvpair id="cib-bootstrap-options-stonith-enabled" name="stonith-enabled" value="1"/> <primitive id="child_DoFencing" class="stonith" type="external/vmware"> <lrm_resource id="child_DoFencing:0" type="external/vmware" class="stonith"> <lrm_resource id="child_DoFencing:0" type="external/vmware" class="stonith"> <lrm_resource id="child_DoFencing:1" type="external/vmware" class="stonith"> <lrm_resource id="child_DoFencing:0" type="external/vmware" class="stonith"> <lrm_resource id="child_DoFencing:2" type="external/vmware" class="stonith"> <lrm_resource id="child_DoFencing:0" type="external/vmware" class="stonith"> <lrm_resource id="child_DoFencing:3" type="external/vmware" class="stonith">
primitive and child_DoFencing). Then simply execute:
# cibadmin --delete --crm_xml '<primitive id="child_DoFencing"/>'# crm_attribute --attr-name stonith-enabled --attr-value truesomenode is allowed to run resources, there is:
# crm_standby --get-value --node-uname somenodemy-test-rsc, one can use:
# crm_resource --locate --resource my-test-rsccrm_shadow which creates a "shadow" copy of the configuration and arranges for all the command line tools to use it.
crm_shadow and give it the name of a configuration to create [5] ; be sure to follow the simple on-screen instructions.
Avvertimento
Esempio 2.7. Creazione e visualizzazione dell'ambiente di test
# crm_shadow --create test Setting up shadow instance Type Ctrl-D to exit the crm_shadow shell shadow[test]: shadow[test] # crm_shadow --which test
crm_shadow options and commands, invoke it with the <parameter>--help</parameter> option.
Esempio 2.8. Utilizzare un ambiente di test per effettuare più cambiamenti contemporaneamente
shadow[test] # crm_failcount -G -r rsc_c001n01 name=fail-count-rsc_c001n01 value=0 shadow[test] # crm_standby -v on -n c001n02 shadow[test] # crm_standby -G -n c001n02 name=c001n02 scope=nodes value=on shadow[test] # cibadmin --erase --force shadow[test] # cibadmin --query <cib cib_feature_revision="1" validate-with="pacemaker-1.0" admin_epoch="0" crm_feature_set="3.0" have-quorum="1" epoch="112" dc-uuid="c001n01" num_updates="1" cib-last-written="Fri Jun 27 12:17:10 2008"> <configuration> <crm_config/> <nodes/> <resources/> <constraints/> </configuration> <status/> </cib> shadow[test] # crm_shadow --delete test --force Now type Ctrl-D to exit the crm_shadow shell shadow[test] # exit # crm_shadow --which No shadow instance provided # cibadmin -Q <cib cib_feature_revision="1" validate-with="pacemaker-1.0" admin_epoch="0" crm_feature_set="3.0" have-quorum="1" epoch="110" dc-uuid="c001n01" num_updates="551"> <configuration> <crm_config> <cluster_property_set id="cib-bootstrap-options"> <nvpair id="cib-bootstrap-1" name="stonith-enabled" value="1"/> <nvpair id="cib-bootstrap-2" name="pe-input-series-max" value="30000"/>
crm_shadow --commit mytest --force), it is often advisable to simulate the effect of the changes with crm_simulate, eg.
# crm_simulate --live-check -VVVVV --save-graph tmp.graph --save-dotfile tmp.dottmp.graph and tmp.dot, both are representations of the same thing — the cluster’s response to your changes.
rsc_action_interval node
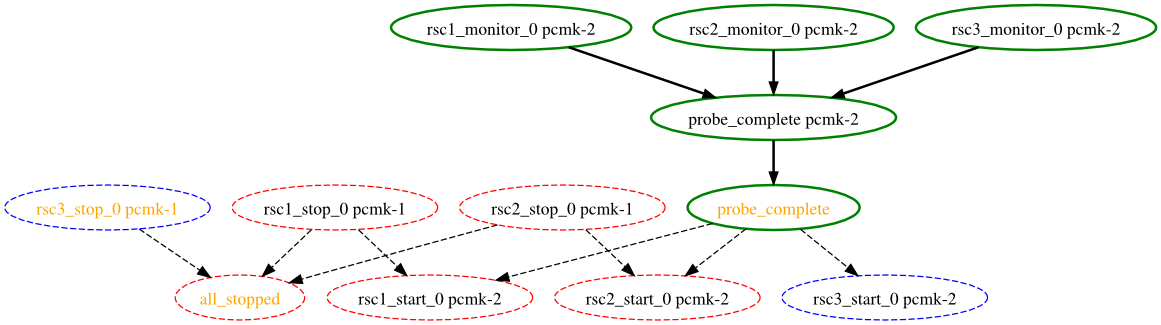
node2, è giunto online e che il cluster sta controllando che rsc1, rsc2 e rsc3 non stiano già funzionando su di esso (indicato dalle entry *_monitor_0). Una volta completato il controllo ed assunto che le risorse non sono attive qui, il cluster vorrebbe stoppare rsc1 ed rsc2 su node1 e muovere tali risorse su node2. Tuttavia, sembrano esserci problemi ed il cluster non può o non riesce ad effettuare lo azioni di stop, che implicano quindi l'impossibilità di eseguire le azioni di start. Per qualche ragione il cluster non vuole avviare rsc3 da nessuna parte.
crm_simulate, use the --help option.
Indice
admin_epoch, epoch, num_updates) tuple to replace the configuration on all the nodes - which makes setting them, and setting them correctly, very important.
Tabella 3.1. Proprietà relative alla versione della configurazione
| Campo | Descrizione |
|---|---|
admin_epoch
|
Never set this value to zero, in such cases the cluster cannot tell the difference between your configuration and the "empty" one used when nothing is found on disk.
|
epoch
| |
num_updates
|
admin_epoch, for example, one would use:
# cibadmin --modify --crm_xml '<cib admin_epoch="42"/>'Esempio 3.1. Un esempio dei campi settati per un oggetto cib
<cib have-quorum="true" validate-with="pacemaker-1.0" admin_epoch="1" epoch="12" num_updates="65" dc-uuid="ea7d39f4-3b94-4cfa-ba7a-952956daabee">
Tabella 3.4. Opzioni del cluster
pengine metadata command.
crm_attribute tool. To get the current value of cluster-delay, simply use:
# crm_attribute --attr-name cluster-delay --get-value# crm_attribute --get-value -n cluster-delay# crm_attribute --get-value -n cluster-delay name=cluster-delay value=60s
# crm_attribute --get-value -n clusta-deway`
name=clusta-deway value=(null)
Error performing operation: The object/attribute does not exist30, simply run:
# crm_attribute --attr-name cluster-delay --attr-value 30s# crm_attribute --attr-name cluster-delay --delete-attrEsempio 3.2. Cancellare un'opzione dichiarata due volte
# crm_attribute --attr-name batch-limit --delete-attr Multiple attributes match name=batch-limit in crm_config: Value: 50 (set=cib-bootstrap-options, id=cib-bootstrap-options-batch-limit) Value: 100 (set=custom, id=custom-batch-limit) Please choose from one of the matches above and supply the 'id' with --attr-id
Indice
Esempio 4.1. Example Heartbeat cluster node entry
<node id="1186dc9a-324d-425a-966e-d757e693dc86" uname="pcmk-1" type="normal"/>
crm_uuid tool to read an existing UUID or define a value before the cluster starts.
uname -n. This can be problematic for services that require the uname -n to be a specific value (ie. for a licence file).
ring0_addr in the nodelist, if it does not contain an IP address; otherwise
name in the nodelist; otherwise
uname -n
crm_node -n command which displays the name used by a running cluster.
crm_node --name-for-id $number is also available to display the name used by the node with the corosync nodeid of $number, for example: crm_node --name-for-id 2.
crm_attribute.
Esempio 4.3. Risultato dell'utilizzo di crm_attribute per specificare quale kernel sta funzionando su pcmk-1
# crm_attribute --type nodes --node-uname pcmk-1 --attr-name kernel --attr-value `uname -r`<node uname="pcmk-1" type="normal" id="101"> <instance_attributes id="nodes-101"> <nvpair id="kernel-101" name="kernel" value="2.6.16.46-0.4-default"/> </instance_attributes> </node>
crm_attribute command again:
# crm_attribute --type nodes --node-uname pcmk-1 --attr-name kernel --get-value--type nodes the admin tells the cluster that this attribute is persistent. There are also transient attributes which are kept in the status section which are "forgotten" whenever the node rejoins the cluster. The cluster uses this area to store a record of how many times a resource has failed on that node but administrators can also read and write to this section by specifying --type status.
mcastaddr option to match the new node’s IP address.
/etc/init.d/corosync stop
# crm_node -R pcmk-1Nota
autojoin any in ha.cf, adding a new node is as simple as installing heartbeat and copying ha.cf and authkeys from an existing node.
autojoin, then after setting up ha.cf and authkeys, you must use hb_addnode before starting the new node.
/etc/init.d/corosync stop
# hb_delnode pcmk-1# crm_node -R pcmk-1Nota
crm_uuid -w and the UUID from step 2
Indice
start, stop or monitor command.
OCF_RESKEY_. So, a parameter which the user thinks of as ip it will be passed to the script as OCF_RESKEY_ip. The number and purpose of the parameters is completely arbitrary, however your script should advertise any that it supports using the meta-data command.
init scripts, systemd has unit files. Generally the services (or unit files) are provided by the OS/distribution but there are some instructions for converting from init scripts at: http://0pointer.de/blog/projects/systemd-for-admins-3.html
Nota
not configured to start any services at boot time that should be controlled by the cluster.
init scripts, upstart has jobs. Generally the services (or jobs) are provided by the OS/distribution.
Nota
not configured to start any services at boot time that should be controlled by the cluster.
systemd, upstart, and lsb), Pacemaker supports a special alias which intelligently figures out which one applies to a given cluster node.
systemd, upstart, and lsb.
crm_resource tool. For example
# crm_resource --resource Email --query-xmlNota
Esempio 5.2. Un esempio di risorsa OCF
<primitive id="Public-IP" class="ocf" type="IPaddr" provider="heartbeat"> <instance_attributes id="params-public-ip"> <nvpair id="public-ip-addr" name="ip" value="1.2.3.4"/> </instance_attributes> </primitive>
--meta option of the crm_resource command.
Tabella 5.2. Opzioni per una Primitive Resource
| Campo | Default | Descrizione |
|---|---|---|
priority
|
0
| |
target-role
|
Started
|
In quale stato il cluster deve cercare di tenere questa risorsa? Valori permessi:
* Stopped - Force the resource to be stopped
* Started - Allow the resource to be started (In the case of multi-state resources, they will not promoted to master)
|
is-managed
|
TRUE
| |
resource-stickiness
|
Calculated
| |
requires
|
Calculated
|
Under what conditions can the resource be started. (Since 1.1.8)
Defaults to
fencing unless stonith-enabled is false or class is stonith - under those conditions the default is quorum. Possible values:
* nothing - can always be started
* quorum - The cluster can only start this resource if a majority of the configured nodes are active
* fencing - The cluster can only start this resource if a majority of the configured nodes are active and any failed or unknown nodes have been powered off.
|
migration-threshold
|
INFINITY (disabled)
| |
failure-timeout
|
0 (disabled)
| |
multiple-active
|
stop_start
|
Cosa dovrebbe fare il cluster se mai trovasse la risorsa attiva su più di un nodo. Valori permessi:
* block - mark the resource as unmanaged
* stop_only - stop all active instances and leave them that way
* stop_start - stop all active instances and start the resource in one location only
|
# crm_resource --meta --resource Email --set-parameter priority --property-value 100 # crm_resource --meta --resource Email --set-parameter multiple-active --property-value block
Esempio 5.3. Una risorsa LSB con le opzioni cluster
<primitive id="Email" class="lsb" type="exim"> <meta_attributes id="meta-email"> <nvpair id="email-priority" name="priority" value="100"/> <nvpair id="email-active" name="multiple-active" value="block"/> </meta_attributes> </primitive>
rsc_defaults section with crm_attribute. Thus,
# crm_attribute --type rsc_defaults --attr-name is-managed --attr-value falseis-managed set to true).
crm_resource command. For instance
# crm_resource --resource Public-IP --set-parameter ip --property-value 1.2.3.4Esempio 5.4. Una risorsa OCF di esempio con attributi di istanza
<primitive id="Public-IP" class="ocf" type="IPaddr" provider="heartbeat"> <instance_attributes id="params-public-ip"> <nvpair id="public-ip-addr" name="ip" value="1.2.3.4"/> </instance_attributes> </primitive>
OCF_RESKEY_ip with a value of 1.2.3.4.
meta-data command. The output contains an XML description of all the supported attributes, their purpose and default values.
Esempio 5.5. Visualizzazione dei metadata per il template del resource agent Dummy
# export OCF_ROOT=/usr/lib/ocf # $OCF_ROOT/resource.d/pacemaker/Dummy meta-data
<?xml version="1.0"?> <!DOCTYPE resource-agent SYSTEM "ra-api-1.dtd"> <resource-agent name="Dummy" version="0.9"> <version>1.0</version> <longdesc lang="en-US"> This is a Dummy Resource Agent. It does absolutely nothing except keep track of whether its running or not. Its purpose in life is for testing and to serve as a template for RA writers. </longdesc> <shortdesc lang="en-US">Dummy resource agent</shortdesc> <parameters> <parameter name="state" unique="1"> <longdesc lang="en-US"> Location to store the resource state in. </longdesc> <shortdesc lang="en-US">State file</shortdesc> <content type="string" default="/var/run/Dummy-{OCF_RESOURCE_INSTANCE}.state" /> </parameter> <parameter name="dummy" unique="0"> <longdesc lang="en-US"> Dummy attribute that can be changed to cause a reload </longdesc> <shortdesc lang="en-US">Dummy attribute that can be changed to cause a reload</shortdesc> <content type="string" default="blah" /> </parameter> </parameters> <actions> <action name="start" timeout="90" /> <action name="stop" timeout="100" /> <action name="monitor" timeout="20" interval="10",height="0" start-delay="0" /> <action name="reload" timeout="90" /> <action name="migrate_to" timeout="100" /> <action name="migrate_from" timeout="90" /> <action name="meta-data" timeout="5" /> <action name="validate-all" timeout="30" /> </actions> </resource-agent>
monitor operation to the resource’s definition.
Esempio 5.6. Una risorsa OCF con un controllo dello stato di salute ciclico
<primitive id="Public-IP" class="ocf" type="IPaddr" provider="heartbeat"> <operations> <op id="public-ip-check" name="monitor" interval="60s"/> </operations> <instance_attributes id="params-public-ip"> <nvpair id="public-ip-addr" name="ip" value="1.2.3.4"/> </instance_attributes> </primitive>
Tabella 5.3. Proprietà di un'operazione
| Campo | Descrizione |
|---|---|
id
| |
name
| |
interval
| |
timeout
| |
on-fail
|
L'azione da intraprendere se l'azione principale dovesse fallire. Valori permessi:
* ignore - Pretend the resource did not fail
* block - Don’t perform any further operations on the resource
* stop - Stop the resource and do not start it elsewhere
* restart - Stop the resource and start it again (possibly on a different node)
* fence - STONITH the node on which the resource failed
* standby - Move all resources away from the node on which the resource failed
|
enabled
|
op_defaults section with crm_attribute. Thus,
# crm_attribute --type op_defaults --attr-name timeout --attr-value 20stimeout to 20 seconds. If an operation’s definition also includes a value for timeout, then that value would be used instead (for that operation only).
start, stop and a non-recurring monitor operation (used at startup to check the resource isn’t already active). If one of these is taking too long, then you can create an entry for them and simply specify a new value.
Esempio 5.7. Una risorsa OCF on timeout personalizzato per le proprie azioni implicite
<primitive id="Public-IP" class="ocf" type="IPaddr" provider="heartbeat"> <operations> <op id="public-ip-startup" name="monitor" interval="0" timeout="90s"/> <op id="public-ip-start" name="start" interval="0" timeout="180s"/> <op id="public-ip-stop" name="stop" interval="0" timeout="15min"/> </operations> <instance_attributes id="params-public-ip"> <nvpair id="public-ip-addr" name="ip" value="1.2.3.4"/> </instance_attributes> </primitive>
OCF_CHECK_LEVEL for this purpose and dictates that it is "made available to the resource agent without the normal OCF_RESKEY prefix".
instance_attributes block to the op tag. Note that it is up to each resource agent to look for the parameter and decide how to use it.
Esempio 5.8. An OCF resource with two recurring health checks, performing different levels of checks - specified via OCF_CHECK_LEVEL.
<primitive id="Public-IP" class="ocf" type="IPaddr" provider="heartbeat"> <operations> <op id="public-ip-health-60" name="monitor" interval="60"> <instance_attributes id="params-public-ip-depth-60"> <nvpair id="public-ip-depth-60" name="OCF_CHECK_LEVEL" value="10"/> </instance_attributes> </op> <op id="public-ip-health-300" name="monitor" interval="300"> <instance_attributes id="params-public-ip-depth-300"> <nvpair id="public-ip-depth-300" name="OCF_CHECK_LEVEL" value="20"/> </instance_attributes> </op> </operations> <instance_attributes id="params-public-ip"> <nvpair id="public-ip-level" name="ip" value="1.2.3.4"/> </instance_attributes> </primitive>
enabled="false" to the operation’s definition.
Esempio 5.9. Esempio di una risorsa OCF con controllo di sanità disabilitato
<primitive id="Public-IP" class="ocf" type="IPaddr" provider="heartbeat"> <operations> <op id="public-ip-check" name="monitor" interval="60s" enabled="false"/> </operations> <instance_attributes id="params-public-ip"> <nvpair id="public-ip-addr" name="ip" value="1.2.3.4"/> </instance_attributes> </primitive>
# cibadmin -M -X '<op id="public-ip-check" enabled="false"/>'Indice
Tabella 6.1. Opzioni per semplici vincoli di locazione (location constraints)
| Campo | Descrizione |
|---|---|
id
| |
rsc
| |
node
| |
score
|
Positive values indicate the resource should run on this node. Negative values indicate the resource should not run on this node.
|
# crm_attribute --attr-name symmetric-cluster --attr-value falsesles-1, the database prefers sles-2 and both can fail over to sles-3 if their most preferred node fails.
Esempio 6.1. Example set of opt-in location constraints
<constraints> <rsc_location id="loc-1" rsc="Webserver" node="sles-1" score="200"/> <rsc_location id="loc-2" rsc="Webserver" node="sles-3" score="0"/> <rsc_location id="loc-3" rsc="Database" node="sles-2" score="200"/> <rsc_location id="loc-4" rsc="Database" node="sles-3" score="0"/> </constraints>
# crm_attribute --attr-name symmetric-cluster --attr-value trueEsempio 6.2. Example set of opt-out location constraints
<constraints> <rsc_location id="loc-1" rsc="Webserver" node="sles-1" score="200"/> <rsc_location id="loc-2-dont-run" rsc="Webserver" node="sles-2" score="-INFINITY"/> <rsc_location id="loc-3-dont-run" rsc="Database" node="sles-1" score="-INFINITY"/> <rsc_location id="loc-4" rsc="Database" node="sles-2" score="200"/> </constraints>
Esempio 6.3. Example of two resources that prefer two nodes equally
<constraints> <rsc_location id="loc-1" rsc="Webserver" node="sles-1" score="INFINITY"/> <rsc_location id="loc-2" rsc="Webserver" node="sles-2" score="INFINITY"/> <rsc_location id="loc-3" rsc="Database" node="sles-1" score="500"/> <rsc_location id="loc-4" rsc="Database" node="sles-2" score="300"/> <rsc_location id="loc-5" rsc="Database" node="sles-2" score="200"/> </constraints>
Tabella 6.2. Properties of an Ordering Constraint
| Campo | Descrizione |
|---|---|
id
| |
first
| |
then
| |
kind
|
How to enforce the constraint. (Since 1.1.2)
* Optional - Just a suggestion. Only applies if both resources are starting/stopping.
* Mandatory - Always. If first is stopping or cannot be started, then must be stopped.
* Serialize - Ensure that no two stop/start actions occur concurrently for a set of resources.
|
symmetrical
|
then resource cannot run without the first resource being active, one should use mandatory constraints. To specify a constraint is mandatory, use scores greater than zero. This will ensure that the then resource will react when the first resource changes state.
first resource was running and is stopped, the then resource will also be stopped (if it is running).
first resource was not running and cannot be started, the then resource will be stopped (if it is running).
first resource is (re)started while the then resource is running, the then resource will be stopped and restarted.
score="0" is specified for a constraint, the constraint is considered optional and only has an effect when both resources are stopping and/or starting. Any change in state by the first resource will have no effect on the then resource.
Esempio 6.4. Example of an optional and mandatory ordering constraint
<constraints> <rsc_order id="order-1" first="Database" then="Webserver" /> <rsc_order id="order-2" first="IP" then="Webserver" score="0"/> </constraints>
+INFINITY or -INFINITY. In such cases, if the constraint can’t be satisfied, then the rsc resource is not permitted to run. For score=INFINITY, this includes cases where the with-rsc resource is not active.
resource1 to always run on the same machine as resource2, you would add the following constraint:
<rsc_colocation id="colocate" rsc="resource1" with-rsc="resource2" score="INFINITY"/>
INFINITY was used, if resource2 can’t run on any of the cluster nodes (for whatever reason) then resource1 will not be allowed to run.
resource1 cannot run on the same machine as resource2. In this case use score="-INFINITY"
<rsc_colocation id="anti-colocate" rsc="resource1" with-rsc="resource2" score="-INFINITY"/>
-INFINTY, the constraint is binding. So if the only place left to run is where resource2 already is, then resource1 may not run anywhere.
-INFINITY and less than INFINITY, the cluster will try and accommodate your wishes but may ignore them if the alternative is to stop some of the cluster resources.
<rsc_colocation id="colocate-maybe" rsc="resource1" with-rsc="resource2" score="500"/>
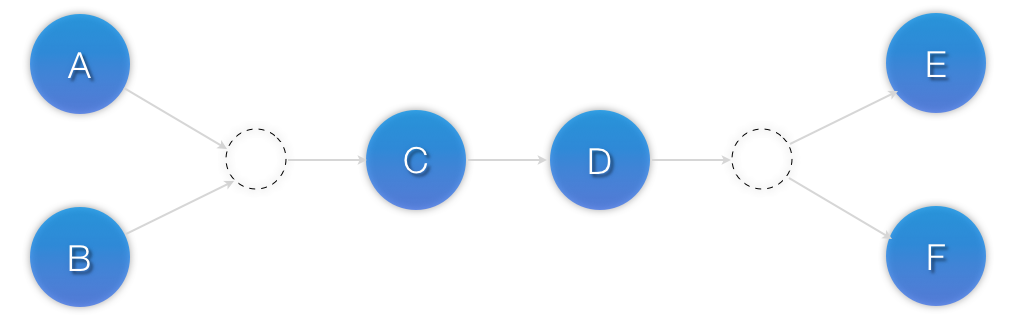
Esempio 6.5. A chain of ordered resources
<constraints> <rsc_order id="order-1" first="A" then="B" /> <rsc_order id="order-2" first="B" then="C" /> <rsc_order id="order-3" first="C" then="D" /> </constraints>
Esempio 6.6. A chain of ordered resources expressed as a set
<constraints> <rsc_order id="order-1"> <resource_set id="ordered-set-example" sequential="true"> <resource_ref id="A"/> <resource_ref id="B"/> <resource_ref id="C"/> <resource_ref id="D"/> </resource_set> </rsc_order> </constraints>
Nota
Esempio 6.7. A group resource with the equivalent ordering rules
<group id="dummy"> <primitive id="A" .../> <primitive id="B" .../> <primitive id="C" .../> <primitive id="D" .../> </group>
rscA and rscB can both start in parallel, as can rscC and rscD, however rscC and rscD can only start once both rscA and rscB are active.
Esempio 6.8. Ordered sets of unordered resources
<constraints> <rsc_order id="order-1"> <resource_set id="ordered-set-1" sequential="false"> <resource_ref id="A"/> <resource_ref id="B"/> </resource_set> <resource_set id="ordered-set-2" sequential="false"> <resource_ref id="C"/> <resource_ref id="D"/> </resource_set> </rsc_order> </constraints>
sequential="true") and there is no limit to the number of sets that can be specified.
Esempio 6.9. Advanced use of set ordering - Three ordered sets, two of which are internally unordered
<constraints> <rsc_order id="order-1"> <resource_set id="ordered-set-1" sequential="false"> <resource_ref id="A"/> <resource_ref id="B"/> </resource_set> <resource_set id="ordered-set-2" sequential="true"> <resource_ref id="C"/> <resource_ref id="D"/> </resource_set> <resource_set id="ordered-set-3" sequential="false"> <resource_ref id="E"/> <resource_ref id="F"/> </resource_set> </rsc_order> </constraints>
Esempio 6.10. A chain of collocated resources
<constraints> <rsc_colocation id="coloc-1" rsc="B" with-rsc="A" score="INFINITY"/> <rsc_colocation id="coloc-2" rsc="C" with-rsc="B" score="INFINITY"/> <rsc_colocation id="coloc-3" rsc="D" with-rsc="C" score="INFINITY"/> </constraints>
resource_sets. Just like the expanded version, a resource that can’t be active also prevents any resource that must be collocated with it from being active. For example, if B was not able to run, then both C (+and by inference +D) must also remain stopped.
Esempio 6.11. The equivalent colocation chain expressed using resource_sets
<constraints> <rsc_colocation id="coloc-1" score="INFINITY" > <resource_set id="collocated-set-example" sequential="true"> <resource_ref id="A"/> <resource_ref id="B"/> <resource_ref id="C"/> <resource_ref id="D"/> </resource_set> </rsc_colocation> </constraints>
Nota
<group id="dummy"> <primitive id="A" .../> <primitive id="B" .../> <primitive id="C" .../> <primitive id="D" .../> </group>
B would be allowed to remain active even if A or C (or both) were inactive.
Esempio 6.12. Using colocation sets to specify a common peer.
<constraints> <rsc_colocation id="coloc-1" score="INFINITY" > <resource_set id="collocated-set-1" sequential="false"> <resource_ref id="A"/> <resource_ref id="B"/> <resource_ref id="C"/> </resource_set> <resource_set id="collocated-set-2" sequential="true"> <resource_ref id="D"/> </resource_set> </rsc_colocation> </constraints>
sequential="true", then in order for member M to be active, member M+1 must also be active. You can even specify the role in which the members of a set must be in using the set’s role attribute.
Esempio 6.13. A colocation chain where the members of the middle set have no inter-dependencies and the last has master status.
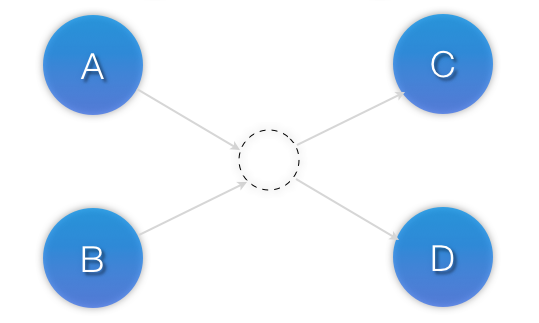
<constraints> <rsc_colocation id="coloc-1" score="INFINITY" > <resource_set id="collocated-set-1" sequential="true"> <resource_ref id="A"/> <resource_ref id="B"/> </resource_set> <resource_set id="collocated-set-2" sequential="false"> <resource_ref id="C"/> <resource_ref id="D"/> <resource_ref id="E"/> </resource_set> <resource_set id="collocated-set-2" sequential="true" role="Master"> <resource_ref id="F"/> <resource_ref id="G"/> </resource_set> </rsc_colocation> </constraints>
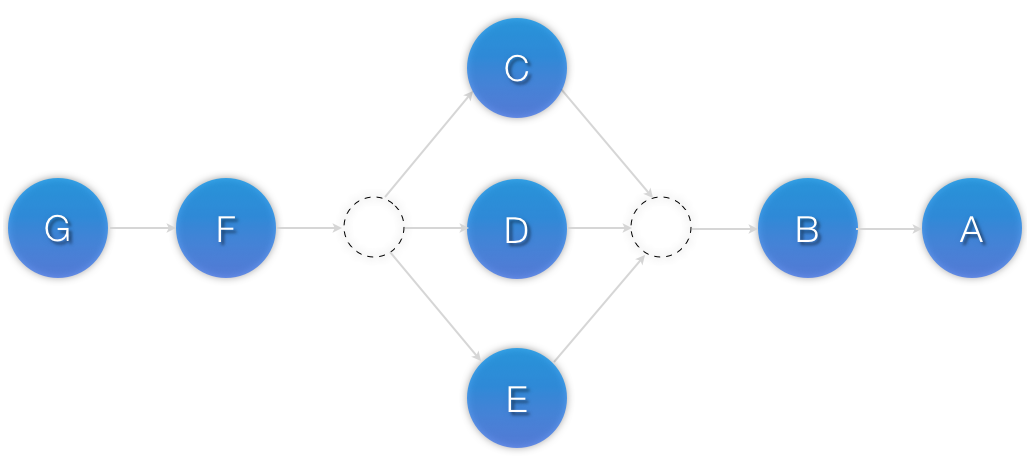
Figura 6.4. Visual representation of a colocation chain where the members of the middle set have no inter-dependencies
Indice
ocf:pacemaker:ClusterMon resource can monitor the cluster status and triggers alerts on each cluster event. This resource runs crm_mon in the background at regular intervals (configurable) and uses crm_mon capabilities to send emails (SMTP), SNMP traps or to execute an external program via the extra_options parameter.
Nota
crm_mon --help output to see if these options are available to you. In any case, executing an external agent will always be available, and you can have this agent to send emails, SNMP traps, or whatever action you develop.
Esempio 7.1. Configuring ClusterMon to send SNMP traps
<clone id="ClusterMon-clone"> <primitive class="ocf" id="ClusterMon-SNMP" provider="pacemaker" type="ClusterMon"> <instance_attributes id="ClusterMon-instance_attributes"> <nvpair id="ClusterMon-instance_attributes-user" name="user" value="root"/> <nvpair id="ClusterMon-instance_attributes-update" name="update" value="30"/> <nvpair id="ClusterMon-instance_attributes-extra_options" name="extra_options" value="-S snmphost.example.com -C public"/> </instance_attributes> </primitive> </clone>
Esempio 7.2. Configuring ClusterMon to send email alerts
<clone id="ClusterMon-clone"> <primitive class="ocf" id="ClusterMon-SMTP" provider="pacemaker" type="ClusterMon"> <instance_attributes id="ClusterMon-instance_attributes"> <nvpair id="ClusterMon-instance_attributes-user" name="user" value="root"/> <nvpair id="ClusterMon-instance_attributes-update" name="update" value="30"/> <nvpair id="ClusterMon-instance_attributes-extra_options" name="extra_options" value="-T pacemaker@example.com -F pacemaker@node2.example.com -P PACEMAKER -H mail.example.com"/> </instance_attributes> </primitive> </clone>
Esempio 7.3. Configuring ClusterMon to execute an external-agent
<clone id="ClusterMon-clone"> <primitive class="ocf" id="ClusterMon" provider="pacemaker" type="ClusterMon"> <instance_attributes id="ClusterMon-instance_attributes"> <nvpair id="ClusterMon-instance_attributes-user" name="user" value="root"/> <nvpair id="ClusterMon-instance_attributes-update" name="update" value="30"/> <nvpair id="ClusterMon-instance_attributes-extra_options" name="extra_options" value="-E /usr/local/bin/example.sh -e 192.168.12.1"/> </instance_attributes> </primitive> </clone>
Tabella 7.1. Environment Variables Passed to the External Agent
| Environment Variable | Description |
|---|---|
CRM_notify_recipient
| |
CRM_notify_node
| |
CRM_notify_rsc
| |
CRM_notify_task
| |
CRM_notify_desc
| |
CRM_notify_rc
| |
CRM_notify_target_rc
| |
CRM_notify_status
|
Indice
resource-stickiness during working hours, to prevent resources from being moved back to their most preferred location, and another on weekends when no-one is around to notice an outage.
boolean-op field to determine if the rule ultimately evaluates to true or false. What happens next depends on the context in which the rule is being used.
#uname.
Tabella 8.2. Proprietà di un'espressione
| Campo | Descrizione |
|---|---|
value
| |
attribute
| |
type
| |
operation
|
Il confronto da effettuare. Valori permessi:
* lt - True if the node attribute’s value is less than
value
* gt - True if the node attribute’s value is greater than
value
* lte - True if the node attribute’s value is less than or equal to
value
* gte - True if the node attribute’s value is greater than or equal to
value
* eq - True if the node attribute’s value is equal to
value
* ne - True if the node attribute’s value is not equal to
value
* defined - True if the node has the named attribute
|
date_expressions are used to control a resource or cluster option based on the current date/time. They can contain an optional date_spec and/or duration object depending on the context.
Tabella 8.3. Proprietà di un'espressione basata sulla data
| Campo | Descrizione |
|---|---|
start
| |
end
| |
operation
|
Confronta la data/ora attuale con la data/ora indicata nei parametri start ed end, dipendentemente dal contesto. Valori permessi:
* gt - True if the current date/time is after
start
* lt - True if the current date/time is before
end
* in-range - True if the current date/time is after
start and before end
|
Nota
date_spec) include the time, the eq, neq, gte and lte operators have not been implemented since they would only be valid for a single second.
date_spec sono utilizzati per creare espressioni simili a quelle cron. Ogi campo contiene un singolo numero ed un singolo range Anziché impostare per default zero, ogni campo non difinito viene ignorato.
monthdays="1" matches the first day of every month and hours="09-17" matches the hours between 9am and 5pm (inclusive). However, at this time one cannot specify weekdays="1,2" or weekdays="1-2,5-6" since they contain multiple ranges. Depending on demand, this may be implemented in a future release.
Tabella 8.4. Prorpietà di una specifica data
| Campo | Descrizione |
|---|---|
id
| |
hours
| |
monthdays
| |
weekdays
| |
yeardays
| |
months
| |
weeks
| |
years
| |
weekyears
| |
moon
|
Esempio 8.1. Vero se "now" è un qualsiasi momento nell'anno 2005
<rule id="rule1"> <date_expression id="date_expr1" start="2005-001" operation="in_range"> <duration years="1"/> </date_expression> </rule>
Esempio 8.2. Equivalent expression
<rule id="rule2"> <date_expression id="date_expr2" operation="date_spec"> <date_spec years="2005"/> </date_expression> </rule>
Esempio 8.3. 9:00-17:00, lunedì-venerdì
<rule id="rule3"> <date_expression id="date_expr3" operation="date_spec"> <date_spec hours="9-16" days="1-5"/> </date_expression> </rule>
16 matches up to 16:59:59, as the numeric value (hour) still matches!
Esempio 8.4. 9:00-18:00, lunedì-venerdì, o qualsiasi ora di sabato
<rule id="rule4" boolean_op="or"> <date_expression id="date_expr4-1" operation="date_spec"> <date_spec hours="9-16" days="1-5"/> </date_expression> <date_expression id="date_expr4-2" operation="date_spec"> <date_spec days="6"/> </date_expression> </rule>
Esempio 8.5. 9:00-17:00 o 21:00-24:00, lunedì-venerdì
<rule id="rule5" boolean_op="and"> <rule id="rule5-nested1" boolean_op="or"> <date_expression id="date_expr5-1" operation="date_spec"> <date_spec hours="9-16"/> </date_expression> <date_expression id="date_expr5-2" operation="date_spec"> <date_spec hours="21-23"/> </date_expression> </rule> <date_expression id="date_expr5-3" operation="date_spec"> <date_spec days="1-5"/> </date_expression> </rule>
Esempio 8.6. Tutti i lunedì del mese di marzo 2005
<rule id="rule6" boolean_op="and"> <date_expression id="date_expr6-1" operation="date_spec"> <date_spec weekdays="1"/> </date_expression> <date_expression id="date_expr6-2" operation="in_range" start="2005-03-01" end="2005-04-01"/> </rule>
Nota
end="2005-03-31T23:59:59" to avoid confusion.
Esempio 8.7. In luna piena di venerdì 13
<rule id="rule7" boolean_op="and"> <date_expression id="date_expr7" operation="date_spec"> <date_spec weekdays="5" monthdays="13" moon="4"/> </date_expression> </rule>
false, the cluster treats the constraint as if it was not there. When the rule evaluates to true, the node’s preference for running the resource is updated with the score associated with the rule.
Esempio 8.8. Impedisci a myApacheRsc di essere eseguita su c001n03
<rsc_location id="dont-run-apache-on-c001n03" rsc="myApacheRsc" score="-INFINITY" node="c001n03"/>
Esempio 8.9. Impedisci a myApacheRsc di essere eseguita su c001n03 - versione estesa
<rsc_location id="dont-run-apache-on-c001n03" rsc="myApacheRsc"> <rule id="dont-run-apache-rule" score="-INFINITY"> <expression id="dont-run-apache-expr" attribute="#uname" operation="eq" value="c00n03"/> </rule> </rsc_location>
Esempio 8.10. Una sezione nodi di esempio da utilizzare con score-attribute
<nodes> <node id="uuid1" uname="c001n01" type="normal"> <instance_attributes id="uuid1-custom_attrs"> <nvpair id="uuid1-cpu_mips" name="cpu_mips" value="1234"/> </instance_attributes> </node> <node id="uuid2" uname="c001n02" type="normal"> <instance_attributes id="uuid2-custom_attrs"> <nvpair id="uuid2-cpu_mips" name="cpu_mips" value="5678"/> </instance_attributes> </node> </nodes>
<rule id="need-more-power-rule" score="-INFINITY"> <expression id=" need-more-power-expr" attribute="cpu_mips" operation="lt" value="3000"/> </rule>
score-attribute instead of score, each node matched by the rule has its score adjusted differently, according to its value for the named node attribute. Thus, in the previous example, if a rule used score-attribute="cpu_mips", c001n01 would have its preference to run the resource increased by 1234 whereas c001n02 would have its preference increased by 5678.
instance_attributes multipli per le risorse ed aggiungendo una regola per ognuno.
mySpecialRsc will use eth1 and port 9999 when run on node1, eth2 and port 8888 on node2 and default to eth0 and port 9999 for all other nodes.
Esempio 8.11. Definire opzioni per le risorse differenti in base al nome del nodo
<primitive id="mySpecialRsc" class="ocf" type="Special" provider="me"> <instance_attributes id="special-node1" score="3"> <rule id="node1-special-case" score="INFINITY" > <expression id="node1-special-case-expr" attribute="#uname" operation="eq" value="node1"/> </rule> <nvpair id="node1-interface" name="interface" value="eth1"/> </instance_attributes> <instance_attributes id="special-node2" score="2" > <rule id="node2-special-case" score="INFINITY"> <expression id="node2-special-case-expr" attribute="#uname" operation="eq" value="node2"/> </rule> <nvpair id="node2-interface" name="interface" value="eth2"/> <nvpair id="node2-port" name="port" value="8888"/> </instance_attributes> <instance_attributes id="defaults" score="1" > <nvpair id="default-interface" name="interface" value="eth0"/> <nvpair id="default-port" name="port" value="9999"/> </instance_attributes> </primitive>
instance_attributes sono valutati è determinato dal loro peso (dal più alto al più basso). Se non è fornito il punteggio di default è zero e gli oggetti con lo stesso punteggio vengono processati nell'ordine della lista. Se l'oggetto instance_attributes non ha una rule o ha una rule che risulta in true, allora la risorsa non avrà ancora un valore per qualsiasi parametro ed utilizzerà quindi il valore fornito dall'oggetto instance_attributes.
resource-stickiness value during and outside of work hours. This allows resources to automatically move back to their most preferred hosts, but at a time that (in theory) does not interfere with business activities.
Esempio 8.12. Change resource-stickiness during working hours
<rsc_defaults> <meta_attributes id="core-hours" score="2"> <rule id="core-hour-rule" score="0"> <date_expression id="nine-to-five-Mon-to-Fri" operation="date_spec"> <date_spec id="nine-to-five-Mon-to-Fri-spec" hours="9-16" weekdays="1-5"/> </date_expression> </rule> <nvpair id="core-stickiness" name="resource-stickiness" value="INFINITY"/> </meta_attributes> <meta_attributes id="after-hours" score="1" > <nvpair id="after-stickiness" name="resource-stickiness" value="0"/> </meta_attributes> </rsc_defaults>
cluster-recheck-interval option. This tells the cluster to periodically recalculate the ideal state of the cluster. For example, if you set cluster-recheck-interval=5m, then sometime between 9:00 and 9:05 the cluster would notice that it needs to start resource X, and between 17:00 and 17:05 it would realize that X needed to be stopped.
Indice
Tabella 9.1. Variabili d'ambiente utilizzate per connettersi ad istanze remote del CIB
| Variabile d'ambiente | Descrizione |
|---|---|
CIB_user
| |
CIB_passwd
| |
CIB_server
| |
CIB_port
| |
CIB_encrypted
|
c001n01 is an active cluster node and is listening on 1234 for connections, and someguy is a member of the hacluster group, then the following would prompt for someguy's password and return the cluster’s current configuration:
# export CIB_port=1234; export CIB_server=c001n01; export CIB_user=someguy; # cibadmin -Q
remote-tls-port (encrypted) or remote-clear-port (unencrypted) top-level options (ie., those kept in the cib tag, like num_updates and epoch).
interval-origin. The cluster uses this point to calculate the correct start-delay such that the operation will occur at origin + (interval * N).
02:00 and it is currently 14:32, then the cluster would initiate the operation with a start delay of 11 hours and 28 minutes. If the resource is moved to another node before 2am, then the operation is of course cancelled.
interval-origin può essere un qualsiasi date/time conforme allo standard ISO8601. Facendo un esempio, per dichiarare un'operazione che verrà eseguita il primo lunedì del 2009 ed ogni lunedì successivo bisognerà aggiungere:
Esempio 9.1. Specificare una base di partenza per gli intervalli relativi alle azioni ricorrenti
<op id="my-weekly-action" name="custom-action" interval="P7D" interval-origin="2009-W01-1"/>
crm_standby. To check the standby status of the current machine, simply run:
# crm_standby --get-valuetrue indicates that the node is NOT able to host any resources, while a value of false says that it CAN.
--node-uname option:
# crm_standby --get-value --node-uname sles-2--attr-value instead of --get-value.
# crm_standby --attr-value--node-uname.
crm_resource command, which creates and modifies the extra constraints for you. If Email was running on sles-1 and you wanted it moved to a specific location, the command would look something like:
# crm_resource -M -r Email -H sles-2<rsc_location rsc="Email" node="sles-2" score="INFINITY"/>
crm_resource -M are not cumulative. So, if you ran these commands
# crm_resource -M -r Email -H sles-2 # crm_resource -M -r Email -H sles-3
# crm_resource -U -r Emailresource-stickiness, it might stay where it is. To be absolutely certain that it moves back to sles-1, move it there before issuing the call to crm_resource -U:
# crm_resource -M -r Email -H sles-1 # crm_resource -U -r Email
# crm_resource -M -r Email`<rsc_location rsc="Email" node="sles-1" score="-INFINITY"/>
-INFINITY constraint will prevent the resource from running on that node until crm_resource -U is used. This includes the situation where every other cluster node is no longer available!
resource-stickiness is set to INFINITY, it is possible that you will end up with the problem described in Sezione 6.2.4, «What if Two Nodes Have the Same Score». The tool can detect some of these cases and deals with them by also creating both a positive and negative constraint. Eg.
Email prefers sles-1 with a score of -INFINITY
Email prefers sles-2 with a score of INFINITY
migration-threshold=N for a resource and it will migrate to a new node after N failures. There is no threshold defined by default. To determine the resource’s current failure status and limits, use crm_mon --failcounts.
crm_failcount (after hopefully first fixing the failure’s cause). However it is possible to expire them by setting the resource’s failure-timeout option.
migration-threshold=2 and failure-timeout=60s would cause the resource to move to a new node after 2 failures, and allow it to move back (depending on the stickiness and constraint scores) after one minute.
INFINITY and thus always cause the resource to move immediately.
Importante
ping resource to the cluster. The ping resource uses the system utility of the same name to a test if list of machines (specified by DNS hostname or IPv4/IPv6 address) are reachable and uses the results to maintain a node attribute normally called pingd. [14]
Nota
Importante
Esempio 9.2. An example ping cluster resource that checks node connectivity once every minute
<clone id="Connected"> <primitive id="ping" provider="pacemaker" class="ocf" type="ping"> <instance_attributes id="ping-attrs"> <nvpair id="pingd-dampen" name="dampen" value="5s"/> <nvpair id="pingd-multiplier" name="multiplier" value="1000"/> <nvpair id="pingd-hosts" name="host_list" value="my.gateway.com www.bigcorp.com"/> </instance_attributes> <operations> <op id="ping-monitor-60s" interval="60s" name="monitor"/> </operations> </primitive> </clone>
Importante
ocf:pacemaker:ping is recording.
Nota
Esempio 9.3. Don’t run on unconnected nodes
<rsc_location id="WebServer-no-connectivity" rsc="Webserver"> <rule id="ping-exclude-rule" score="-INFINITY" > <expression id="ping-exclude" attribute="pingd" operation="not_defined"/> </rule> </rsc_location>
Esempio 9.4. Run only on nodes connected to three or more ping nodes; this assumes multiplier is set to 1000:
<rsc_location id="WebServer-connectivity" rsc="Webserver"> <rule id="ping-prefer-rule" score="-INFINITY" > <expression id="ping-prefer" attribute="pingd" operation="lt" value="3000"/> </rule> </rsc_location>
multiplier to a value higher than that of resource-stickiness (and don’t set either of them to INFINITY).
Esempio 9.5. Prediligi il nodo che il maggior numero di nodi ping
<rsc_location id="WebServer-connectivity" rsc="Webserver"> <rule id="ping-prefer-rule" score-attribute="pingd" > <expression id="ping-prefer" attribute="pingd" operation="defined"/> </rule> </rsc_location>
sles-1 is connected to all 5 ping nodes but sles-2 is only connected to 2, then it would be as if you instead had the following constraints in your configuration:
Esempio 9.6. Come il cluster traduce le constraint pingd
<rsc_location id="ping-1" rsc="Webserver" node="sles-1" score="5000"/> <rsc_location id="ping-2" rsc="Webserver" node="sles-2" score="2000"/>
multiplier is set to 1000).
Esempio 9.7. Un esempio più complesso di location basata sui valori di connettività
<rsc_location id="WebServer-connectivity" rsc="Webserver"> <rule id="ping-exclude-rule" score="-INFINITY" > <expression id="ping-exclude" attribute="pingd" operation="lt" value="3000"/> </rule> <rule id="ping-prefer-rule" score-attribute="pingd" > <expression id="ping-prefer" attribute="pingd" operation="defined"/> </rule> </rsc_location>
migrate_to (eseguita sulla locazione attuale) e migrate_from (eseguita sulla destinazione).
migrate_to action and, if anything, the activation would occur during migrate_from.
migrate_to è praticamente nulla mentre la maggior parte del lavoro è svoloto durante migrate_from, che estrae lo stato rilevante della risorsa nella vecchia locazione e lo attiva.
migrate_to and migrate_from, and advertise them in its metadata.
allow-migrate meta-attribute set to true (which is not the default).
id-ref instead of an id.
<rsc_location id="WebServer-connectivity" rsc="Webserver"> <rule id="ping-prefer-rule" score-attribute="pingd" > <expression id="ping-prefer" attribute="pingd" operation="defined"/> </rule> </rsc_location>
Esempio 9.8. Referenziare regole da altre constraint
<rsc_location id="WebDB-connectivity" rsc="WebDB"> <rule id-ref="ping-prefer-rule"/> </rsc_location>
Importante
rule esiste da qualche parte. Cercare di aggiungere una referenza ad una regola inesistente provocherà problemi nella validazione, in quanto seguirà un tentativo di rimuovere una rule referenziata altrove.
meta_attributes and instance_attributes as illustrated in the example below:
Esempio 9.9. Referencing attributes, options, and operations from other resources
<primitive id="mySpecialRsc" class="ocf" type="Special" provider="me"> <instance_attributes id="mySpecialRsc-attrs" score="1" > <nvpair id="default-interface" name="interface" value="eth0"/> <nvpair id="default-port" name="port" value="9999"/> </instance_attributes> <meta_attributes id="mySpecialRsc-options"> <nvpair id="failure-timeout" name="failure-timeout" value="5m"/> <nvpair id="migration-threshold" name="migration-threshold" value="1"/> <nvpair id="stickiness" name="resource-stickiness" value="0"/> </meta_attributes> <operations id="health-checks"> <op id="health-check" name="monitor" interval="60s"/> <op id="health-check" name="monitor" interval="30min"/> </operations> </primitive> <primitive id="myOtherlRsc" class="ocf" type="Other" provider="me"> <instance_attributes id-ref="mySpecialRsc-attrs"/> <meta_attributes id-ref="mySpecialRsc-options"/> <operations id-ref="health-checks"/> </primitive>
reload operation and perform any required actions. The steps required here depend completely on your application!
Esempio 9.10. The DRBD Agent’s Control logic for Supporting the reload Operation
case $1 in start) drbd_start ;; stop) drbd_stop ;; reload) drbd_reload ;; monitor) drbd_monitor ;; *) drbd_usage exit $OCF_ERR_UNIMPLEMENTED ;; esac exit $?
reload nella sezione actions dei metadata
Esempio 9.11. La logica di controllo dell'operazione di reload implementata dall'agente DRBD
<?xml version="1.0"?> <!DOCTYPE resource-agent SYSTEM "ra-api-1.dtd"> <resource-agent name="drbd"> <version>1.1</version> <longdesc> Master/Slave OCF Resource Agent for DRBD </longdesc> ... <actions> <action name="start" timeout="240" /> <action name="reload" timeout="240" /> <action name="promote" timeout="90" /> <action name="demote" timeout="90" /> <action name="notify" timeout="90" /> <action name="stop" timeout="100" /> <action name="meta-data" timeout="5" /> <action name="validate-all" timeout="30" /> </actions> </resource-agent>
reload.
unique set to 0 is eligible to be used in this way.
Esempio 9.12. Paramtro modificabile utilizzando reload
<parameter name="drbdconf" unique="0"> <longdesc>Full path to the drbd.conf file.</longdesc> <shortdesc>Path to drbd.conf</shortdesc> <content type="string" default="${OCF_RESKEY_drbdconf_default}"/> </parameter>
Nota
unique=0
Nota
Indice
Esempio 10.1. Un esempio di gruppo
<group id="shortcut"> <primitive id="Public-IP" class="ocf" type="IPaddr" provider="heartbeat"> <instance_attributes id="params-public-ip"> <nvpair id="public-ip-addr" name="ip" value="1.2.3.4"/> </instance_attributes> </primitive> <primitive id="Email" class="lsb" type="exim"/> </group>
Public-IP first, then Email)
Email first, then Public-IP)
Public-IP can’t run anywhere, neither can Email;
Email can’t run anywhere, this does not affect Public-IP in any way
Esempio 10.2. Come il gruppo di risorse è visto dal cluster
<configuration> <resources> <primitive id="Public-IP" class="ocf" type="IPaddr" provider="heartbeat"> <instance_attributes id="params-public-ip"> <nvpair id="public-ip-addr" name="ip" value="1.2.3.4"/> </instance_attributes> </primitive> <primitive id="Email" class="lsb" type="exim"/> </resources> <constraints> <rsc_colocation id="xxx" rsc="Email" with-rsc="Public-IP" score="INFINITY"/> <rsc_order id="yyy" first="Public-IP" then="Email"/> </constraints> </configuration>
priority, target-role, is-managed
Esempio 10.3. Esempio di constraint che coinvolgono i gruppi
<constraints> <rsc_location id="group-prefers-node1" rsc="shortcut" node="node1" score="500"/> <rsc_colocation id="webserver-with-group" rsc="Webserver" with-rsc="shortcut"/> <rsc_order id="start-group-then-webserver" first="Webserver" then="shortcut"/> </constraints>
resource-stickiness is 100, and a group has seven members, five of which are active, then the group as a whole will prefer its current location with a score of 500.
Esempio 10.4. Un esempio di risorsa clonata
<clone id="apache-clone"> <meta_attributes id="apache-clone-meta"> <nvpair id="apache-unique" name="globally-unique" value="false"/> </meta_attributes> <primitive id="apache" class="lsb" type="apache"/> </clone>
priority, target-role, is-managed
Tabella 10.3. Opzioni specifiche di configurazione per le risorse Clone
| Campo | Descrizione |
|---|---|
clone-max
| |
clone-node-max
| |
notify
| |
globally-unique
| |
ordered
| |
interleave
|
Avvertimento
apache-stats will wait until all copies of the clone that need to be started have done so before being started itself. Only if no copies can be started apache-stats will be prevented from being active. Additionally, the clone will wait for apache-stats to be stopped before stopping the clone.
Esempio 10.5. Esempi di constraint che coinvolgono cloni
<constraints> <rsc_location id="clone-prefers-node1" rsc="apache-clone" node="node1" score="500"/> <rsc_colocation id="stats-with-clone" rsc="apache-stats" with="apache-clone"/> <rsc_order id="start-clone-then-stats" first="apache-clone" then="apache-stats"/> </constraints>
resource-stickiness, la risorsa clone utilizzerà il valore di 1. Essendo un valore ridotto, esso causa il disturbo minimo nel calcolo del punteggio delle altre risorse, ma è sufficiente per prevenire Pacemaker dal muovere inutilmente copie delle risorse nel cluster.
apache:2.
OCF_RESKEY_CRM_meta_clone_max environment variable and which copy it is by examining OCF_RESKEY_CRM_meta_clone.
OCF_RESKEY_CRM_meta_clone) about which copies are active. In particular, the list of active copies will not always be an unbroken sequence, nor always start at 0.
notify sia implementata. Una volta che questa è supportata all'azione notify verranno passate un numero di variabili extra che, quando combinate con le informazioni aggiuntive, potranno essere utilizzate per calcolare lo stato attuale del cluster e cosa sta per succedere ad esso.
Tabella 10.4. Variabili d'ambiente fornite alle azioni notify delle risorse clone
| Variabile | Descrizione |
|---|---|
|
OCF_RESKEY_CRM_meta_notify_type
| |
|
OCF_RESKEY_CRM_meta_notify_operation
| |
|
OCF_RESKEY_CRM_meta_notify_start_resource
| |
|
OCF_RESKEY_CRM_meta_notify_stop_resource
| |
|
OCF_RESKEY_CRM_meta_notify_active_resource
| |
|
OCF_RESKEY_CRM_meta_notify_inactive_resource
| |
|
OCF_RESKEY_CRM_meta_notify_start_uname
| |
|
OCF_RESKEY_CRM_meta_notify_stop_uname
| |
|
OCF_RESKEY_CRM_meta_notify_active_uname
| |
|
OCF_RESKEY_CRM_meta_notify_inactive_uname
|
OCF_RESKEY_CRM_meta_notify_start_resource and OCF_RESKEY_CRM_meta_notify_start_uname and should be treated as an array of whitespace separated elements.
clone:0 will be started on sles-1, clone:2 will be started on sles-3, and clone:3 will be started on sles-2, the cluster would set
Esempio 10.6. Esempio di variabili notifica
OCF_RESKEY_CRM_meta_notify_start_resource="clone:0 clone:2 clone:3" OCF_RESKEY_CRM_meta_notify_start_uname="sles-1 sles-3 sles-2"
Pre-notification (stop):
$OCF_RESKEY_CRM_meta_notify_active_resource
$OCF_RESKEY_CRM_meta_notify_inactive_resource
$OCF_RESKEY_CRM_meta_notify_start_resource
$OCF_RESKEY_CRM_meta_notify_stop_resource
Post-notification (stop) / Pre-notification (start):
$OCF_RESKEY_CRM_meta_notify_active_resource
$OCF_RESKEY_CRM_meta_notify_stop_resource
$OCF_RESKEY_CRM_meta_notify_inactive_resource
$OCF_RESKEY_CRM_meta_notify_stop_resource
$OCF_RESKEY_CRM_meta_notify_start_resource
$OCF_RESKEY_CRM_meta_notify_stop_resource
Post-notification (start):
$OCF_RESKEY_CRM_meta_notify_active_resource
$OCF_RESKEY_CRM_meta_notify_stop_resource
$OCF_RESKEY_CRM_meta_notify_start_resource
$OCF_RESKEY_CRM_meta_notify_inactive_resource
$OCF_RESKEY_CRM_meta_notify_stop_resource
$OCF_RESKEY_CRM_meta_notify_start_resource
$OCF_RESKEY_CRM_meta_notify_start_resource
$OCF_RESKEY_CRM_meta_notify_stop_resource
Master and Slave, but can mean whatever you wish them to mean. The only limitation is that when an instance is started, it must come up in the Slave state.
clone-max, clone-node-max, notify, globally-unique, ordered, interleave
Avvertimento
Master state. To detect failures of the Master instance, you need to define an additional monitor action with role="Master".
Importante
Esempio 10.7. Monitorare entrambi gli stati di una risorsa multi-state
<master id="myMasterRsc"> <primitive id="myRsc" class="ocf" type="myApp" provider="myCorp"> <operations> <op id="public-ip-slave-check" name="monitor" interval="60"/> <op id="public-ip-master-check" name="monitor" interval="61" role="Master"/> </operations> </primitive> </master>
rsc-role and/or with-rsc-role fields (for colocation constraints) and first-action and/or then-action fields (for ordering constraints) are used.
Tabella 10.7. Opzioni aggiuntive per le constraint relative alle risorse multi-state
| Campo | Descrizione |
|---|---|
rsc-role
| |
with-rsc-role
| |
first-action
| |
then-action
|
myApp will wait until one of the database copies has been started and promoted to master before being started itself. Only if no copies can be promoted will apache-stats be prevented from being active. Additionally, the database will wait for myApp to be stopped before it is demoted.
Esempio 10.8. Esempio di constraint che coinvolge risorse multi-state
<constraints> <rsc_location id="db-prefers-node1" rsc="database" node="node1" score="500"/> <rsc_colocation id="backup-with-db-slave" rsc="backup" with-rsc="database" with-rsc-role="Slave"/> <rsc_colocation id="myapp-with-db-master" rsc="myApp" with-rsc="database" with-rsc-role="Master"/> <rsc_order id="start-db-before-backup" first="database" then="backup"/> <rsc_order id="promote-db-then-app" first="database" first-action="promote" then="myApp" then-action="start"/> </constraints>
Master or Slave). In the example, the cluster will choose a location based on where database is running as a Master, and if there are multiple Master instances it will also factor in myApp's own location preferences when deciding which location to choose.
rsc clone is (after role filtering) limited to nodes on which the with-rsc multi-state resource is (or will be) in the specified role. Allocation is then performed as-per-normal.
resource-stickiness is provided, the multi-state resource will use a value of 1. Being a small value, it causes minimal disturbance to the score calculations of other resources but is enough to prevent Pacemaker from needlessly moving copies around the cluster.
crm_master utility. This tool automatically detects both the resource and host and should be used to set a preference for being promoted. Based on this, master-max, and master-node-max, the instance(s) with the highest preference will be promoted.
Esempio 10.9. Specificare manualmente quale nodo dovrebbe essere promosso
<rsc_location id="master-location" rsc="myMasterRsc"> <rule id="master-rule" score="100" role="Master"> <expression id="master-exp" attribute="#uname" operation="eq" value="node1"/> </rule> </rsc_location>
demote and promote; these actions are responsible for changing the state of the resource. Like start and stop, they should return OCF_SUCCESS if they completed successfully or a relevant error code if they did not.
Slave. From there the cluster will then decide which instances to promote to Master.
notify action to be implemented. Once supported the notify action will be passed a number of extra variables which, when combined with additional context, can be used to calculate the current state of the cluster and what is about to happen to it.
Tabella 10.9. Environment variables supplied with Master notify actions [a]
| Variabile | Descrizione |
|---|---|
|
OCF_RESKEY_CRM_meta_notify_type
| |
|
OCF_RESKEY_CRM_meta_notify_operation
| |
|
OCF_RESKEY_CRM_meta_notify_active_resource
| |
|
OCF_RESKEY_CRM_meta_notify_inactive_resource
| |
|
OCF_RESKEY_CRM_meta_notify_master_resource
| |
|
OCF_RESKEY_CRM_meta_notify_slave_resource
| |
|
OCF_RESKEY_CRM_meta_notify_start_resource
| |
|
La risorsa da stoppare
| |
|
OCF_RESKEY_CRM_meta_notify_promote_resource
| |
|
OCF_RESKEY_CRM_meta_notify_demote_resource
| |
|
OCF_RESKEY_CRM_meta_notify_start_uname
| |
|
OCF_RESKEY_CRM_meta_notify_stop_uname
| |
|
OCF_RESKEY_CRM_meta_notify_promote_uname
| |
|
OCF_RESKEY_CRM_meta_notify_demote_uname
| |
|
OCF_RESKEY_CRM_meta_notify_active_uname
| |
|
OCF_RESKEY_CRM_meta_notify_inactive_uname
| |
|
OCF_RESKEY_CRM_meta_notify_master_uname
| |
|
OCF_RESKEY_CRM_meta_notify_slave_uname
|
Pre-notification (demote):
Active resources: $OCF_RESKEY_CRM_meta_notify_active_resource
Master resources: $OCF_RESKEY_CRM_meta_notify_master_resource
Slave resources: $OCF_RESKEY_CRM_meta_notify_slave_resource
$OCF_RESKEY_CRM_meta_notify_inactive_resource
$OCF_RESKEY_CRM_meta_notify_start_resource
$OCF_RESKEY_CRM_meta_notify_promote_resource
$OCF_RESKEY_CRM_meta_notify_demote_resource
$OCF_RESKEY_CRM_meta_notify_stop_resource
Post-notification (demote) / Pre-notification (stop):
Active resources: $OCF_RESKEY_CRM_meta_notify_active_resource
Master resources:
$OCF_RESKEY_CRM_meta_notify_master_resource
$OCF_RESKEY_CRM_meta_notify_demote_resource
Slave resources: $OCF_RESKEY_CRM_meta_notify_slave_resource
$OCF_RESKEY_CRM_meta_notify_inactive_resource
$OCF_RESKEY_CRM_meta_notify_start_resource
$OCF_RESKEY_CRM_meta_notify_promote_resource
$OCF_RESKEY_CRM_meta_notify_demote_resource
$OCF_RESKEY_CRM_meta_notify_stop_resource
$OCF_RESKEY_CRM_meta_notify_demote_resource
Post-notification (stop) / Pre-notification (start)
Active resources:
$OCF_RESKEY_CRM_meta_notify_active_resource
$OCF_RESKEY_CRM_meta_notify_stop_resource
Master resources:
$OCF_RESKEY_CRM_meta_notify_master_resource
$OCF_RESKEY_CRM_meta_notify_demote_resource
Slave resources:
$OCF_RESKEY_CRM_meta_notify_slave_resource
$OCF_RESKEY_CRM_meta_notify_stop_resource
$OCF_RESKEY_CRM_meta_notify_inactive_resource
$OCF_RESKEY_CRM_meta_notify_stop_resource
$OCF_RESKEY_CRM_meta_notify_start_resource
$OCF_RESKEY_CRM_meta_notify_promote_resource
$OCF_RESKEY_CRM_meta_notify_demote_resource
$OCF_RESKEY_CRM_meta_notify_stop_resource
$OCF_RESKEY_CRM_meta_notify_demote_resource
$OCF_RESKEY_CRM_meta_notify_stop_resource
Post-notification (start) / Pre-notification (promote)
Active resources:
$OCF_RESKEY_CRM_meta_notify_active_resource
$OCF_RESKEY_CRM_meta_notify_stop_resource
$OCF_RESKEY_CRM_meta_notify_start_resource
Master resources:
$OCF_RESKEY_CRM_meta_notify_master_resource
$OCF_RESKEY_CRM_meta_notify_demote_resource
Slave resources:
$OCF_RESKEY_CRM_meta_notify_slave_resource
$OCF_RESKEY_CRM_meta_notify_stop_resource
$OCF_RESKEY_CRM_meta_notify_start_resource
$OCF_RESKEY_CRM_meta_notify_inactive_resource
$OCF_RESKEY_CRM_meta_notify_stop_resource
$OCF_RESKEY_CRM_meta_notify_start_resource
$OCF_RESKEY_CRM_meta_notify_start_resource
$OCF_RESKEY_CRM_meta_notify_promote_resource
$OCF_RESKEY_CRM_meta_notify_demote_resource
$OCF_RESKEY_CRM_meta_notify_stop_resource
$OCF_RESKEY_CRM_meta_notify_start_resource
$OCF_RESKEY_CRM_meta_notify_demote_resource
$OCF_RESKEY_CRM_meta_notify_stop_resource
Post-notification (promote)
Active resources:
$OCF_RESKEY_CRM_meta_notify_active_resource
$OCF_RESKEY_CRM_meta_notify_stop_resource
$OCF_RESKEY_CRM_meta_notify_start_resource
Master resources:
$OCF_RESKEY_CRM_meta_notify_master_resource
$OCF_RESKEY_CRM_meta_notify_demote_resource
$OCF_RESKEY_CRM_meta_notify_promote_resource
Slave resources:
$OCF_RESKEY_CRM_meta_notify_slave_resource
$OCF_RESKEY_CRM_meta_notify_stop_resource
$OCF_RESKEY_CRM_meta_notify_start_resource
$OCF_RESKEY_CRM_meta_notify_promote_resource
$OCF_RESKEY_CRM_meta_notify_inactive_resource
$OCF_RESKEY_CRM_meta_notify_stop_resource
$OCF_RESKEY_CRM_meta_notify_start_resource
$OCF_RESKEY_CRM_meta_notify_start_resource
$OCF_RESKEY_CRM_meta_notify_promote_resource
$OCF_RESKEY_CRM_meta_notify_demote_resource
$OCF_RESKEY_CRM_meta_notify_stop_resource
$OCF_RESKEY_CRM_meta_notify_start_resource
$OCF_RESKEY_CRM_meta_notify_promote_resource
$OCF_RESKEY_CRM_meta_notify_demote_resource
$OCF_RESKEY_CRM_meta_notify_stop_resource
Indice
default placement strategy, Pacemaker will choose a node with the least number of allocated resources for balancing the load. If the number of resources on each node is equal, the first eligible node listed in cib will be chosen to run the resource.
capacity a certain node provides.
capacity a certain resource requires.
strategy for placement of resources.
utilization attributes. You can name the utilization attributes according to your preferences and define as many name/value pairs as your configuration needs. However, the attribute’s values must be integers.
<node id="node1" type="normal" uname="node1"> <utilization id="node1-utilization"> <nvpair id="node1-utilization-cpu" name="cpu" value="2"/> <nvpair id="node1-utilization-memory" name="memory" value="2048"/> </utilization> </node> <node id="node2" type="normal" uname="node2"> <utilization id="node2-utilization"> <nvpair id="node2-utilization-cpu" name="cpu" value="4"/> <nvpair id="node2-utilization-memory" name="memory" value="4096"/> </utilization> </node>
<primitive id="rsc-small" class="ocf" provider="pacemaker" type="Dummy"> <utilization id="rsc-small-utilization"> <nvpair id="rsc-small-utilization-cpu" name="cpu" value="1"/> <nvpair id="rsc-small-utilization-memory" name="memory" value="1024"/> </utilization> </primitive> <primitive id="rsc-medium" class="ocf" provider="pacemaker" type="Dummy"> <utilization id="rsc-medium-utilization"> <nvpair id="rsc-medium-utilization-cpu" name="cpu" value="2"/> <nvpair id="rsc-medium-utilization-memory" name="memory" value="2048"/> </utilization> </primitive> <primitive id="rsc-large" class="ocf" provider="pacemaker" type="Dummy"> <utilization id="rsc-large-utilization"> <nvpair id="rsc-large-utilization-cpu" name="cpu" value="3"/> <nvpair id="rsc-large-utilization-memory" name="memory" value="3072"/> </utilization> </primitive>
placement-strategy in the global cluster options, otherwise the capacity configurations have no effect.
placement-strategy:
defaultutilizationbalancedminimalplacement-strategy with crm_attribute:
# crm_attribute --attr-name placement-strategy --attr-value balancedplacement-strategy="default|utilization", the node that has the least number of allocated resources gets consumed first.
placement-strategy="balanced", the node that has more free capacity gets consumed first.
placement-strategy="minimal", the first eligible node listed in cib gets consumed first.
capacity. While if we define multiple types of capacity, for example:
nodeA has more free cpus, nodeB has more free memory, their free capacities are equal.
nodeA has more free cpus, while nodeB has more free memory and storage, nodeB has more free capacity.
rsc-small would be allocated to node1
rsc-medium would be allocated to node2
rsc-large would remain inactive
all the time. This practice is also known as over commit.
Indice
<template id="vm-template" class="ocf" provider="heartbeat" type="Xen"> <meta_attributes id="vm-template-meta_attributes"> <nvpair id="vm-template-meta_attributes-allow-migrate" name="allow-migrate" value="true"/> </meta_attributes> <utilization id="vm-template-utilization"> <nvpair id="vm-template-utilization-memory" name="memory" value="512"/> </utilization> <operations> <op id="vm-template-monitor-15s" interval="15s" name="monitor" timeout="60s"/> <op id="vm-template-start-0" interval="0" name="start" timeout="60s"/> </operations> </template>
<primitive id="vm1" template="vm-template"> <instance_attributes id="vm1-instance_attributes"> <nvpair id="vm1-instance_attributes-name" name="name" value="vm1"/> <nvpair id="vm1-instance_attributes-xmfile" name="xmfile" value="/etc/xen/shared-vm/vm1"/> </instance_attributes> </primitive>
vm1 is going to inherit everything from the vm-template. For example, the equivalent of the above two would be:
<primitive id="vm1" class="ocf" provider="heartbeat" type="Xen"> <meta_attributes id="vm-template-meta_attributes"> <nvpair id="vm-template-meta_attributes-allow-migrate" name="allow-migrate" value="true"/> </meta_attributes> <utilization id="vm-template-utilization"> <nvpair id="vm-template-utilization-memory" name="memory" value="512"/> </utilization> <operations> <op id="vm-template-monitor-15s" interval="15s" name="monitor" timeout="60s"/> <op id="vm-template-start-0" interval="0" name="start" timeout="60s"/> </operations> <instance_attributes id="vm1-instance_attributes"> <nvpair id="vm1-instance_attributes-name" name="name" value="vm1"/> <nvpair id="vm1-instance_attributes-xmfile" name="xmfile" value="/etc/xen/shared-vm/vm1"/> </instance_attributes> </primitive>
vm2 has special attribute values. Its monitor operation has a longer timeout and interval, and the primitive has an additional stop operation.
<primitive id="vm2" template="vm-template"> <meta_attributes id="vm2-meta_attributes"> <nvpair id="vm2-meta_attributes-allow-migrate" name="allow-migrate" value="false"/> </meta_attributes> <utilization id="vm2-utilization"> <nvpair id="vm2-utilization-memory" name="memory" value="1024"/> </utilization> <instance_attributes id="vm2-instance_attributes"> <nvpair id="vm2-instance_attributes-name" name="name" value="vm2"/> <nvpair id="vm2-instance_attributes-xmfile" name="xmfile" value="/etc/xen/shared-vm/vm2"/> </instance_attributes> <operations> <op id="vm2-monitor-30s" interval="30s" name="monitor" timeout="120s"/> <op id="vm2-stop-0" interval="0" name="stop" timeout="60s"/> </operations> </primitive>
# crm_resource --query-xml --resource vm2# crm_resource --query-xml-raw --resource vm2order constraints
colocation constraints,
rsc_ticket constraints (for multi-site clusters).
<rsc_colocation id="vm-template-colo-base-rsc" rsc="vm-template" rsc-role="Started" with-rsc="base-rsc" score="INFINITY"/>
<rsc_colocation id="vm-colo-base-rsc" score="INFINITY"> <resource_set id="vm-colo-base-rsc-0" sequential="false" role="Started"> <resource_ref id="vm1"/> <resource_ref id="vm2"/> </resource_set> <resource_set id="vm-colo-base-rsc-1"> <resource_ref id="base-rsc"/> </resource_set> </rsc_colocation>
Nota
rsc or with-rsc, and the other reference must be a regular resource.
<rsc_order id="order1" score="INFINITY"> <resource_set id="order1-0"> <resource_ref id="base-rsc"/> <resource_ref id="vm-template"/> <resource_ref id="top-rsc"/> </resource_set> </rsc_order>
<rsc_order id="order1" score="INFINITY"> <resource_set id="order1-0"> <resource_ref id="base-rsc"/> <resource_ref id="vm1"/> <resource_ref id="vm2"/> <resource_ref id="top-rsc"/> </resource_set> </rsc_order>
<rsc_order id="order2" score="INFINITY"> <resource_set id="order2-0"> <resource_ref id="base-rsc"/> </resource_set> <resource_set id="order2-1" sequential="false"> <resource_ref id="vm-template"/> </resource_set> <resource_set id="order2-2"> <resource_ref id="top-rsc"/> </resource_set> </rsc_order>
<rsc_order id="order2" score="INFINITY"> <resource_set id="order2-0"> <resource_ref id="base-rsc"/> </resource_set> <resource_set id="order2-1" sequential="false"> <resource_ref id="vm1"/> <resource_ref id="vm2"/> </resource_set> <resource_set id="order2-2"> <resource_ref id="top-rsc"/> </resource_set> </rsc_order>
Indice
stonith_admin --list-installed
stonith_admin --metadata --agent type
The output should be XML formatted text containing additional parameter descriptions. We will endevor to make the output more friendly in a later version.
cib new stonith Create a fencing resource containing a primitive resource with a class of stonith, a type of type and a parameter for each of the values returned in step 2: configure primitive …
pcmk_host_map parameter. See man stonithd for details.
pcmk_host_list and/or pcmk_host_check parameters. See man stonithd for details.
pcmk_host_argument parameter. See man stonithd for details.
cib commit stonith
stonith_admin --reboot nodename. Although you might want to stop the cluster on that machine first.
# stonith_admin --metadata -a fence_ipmilan
<?xml version="1.0" ?> <resource-agent name="fence_ipmilan" shortdesc="Fence agent for IPMI over LAN"> <longdesc> fence_ipmilan is an I/O Fencing agent which can be used with machines controlled by IPMI. This agent calls support software using ipmitool (http://ipmitool.sf.net/). To use fence_ipmilan with HP iLO 3 you have to enable lanplus option (lanplus / -P) and increase wait after operation to 4 seconds (power_wait=4 / -T 4)</longdesc> <parameters> <parameter name="auth" unique="1"> <getopt mixed="-A" /> <content type="string" /> <shortdesc>IPMI Lan Auth type (md5, password, or none)</shortdesc> </parameter> <parameter name="ipaddr" unique="1"> <getopt mixed="-a" /> <content type="string" /> <shortdesc>IPMI Lan IP to talk to</shortdesc> </parameter> <parameter name="passwd" unique="1"> <getopt mixed="-p" /> <content type="string" /> <shortdesc>Password (if required) to control power on IPMI device</shortdesc> </parameter> <parameter name="passwd_script" unique="1"> <getopt mixed="-S" /> <content type="string" /> <shortdesc>Script to retrieve password (if required)</shortdesc> </parameter> <parameter name="lanplus" unique="1"> <getopt mixed="-P" /> <content type="boolean" /> <shortdesc>Use Lanplus</shortdesc> </parameter> <parameter name="login" unique="1"> <getopt mixed="-l" /> <content type="string" /> <shortdesc>Username/Login (if required) to control power on IPMI device</shortdesc> </parameter> <parameter name="action" unique="1"> <getopt mixed="-o" /> <content type="string" default="reboot"/> <shortdesc>Operation to perform. Valid operations: on, off, reboot, status, list, diag, monitor or metadata</shortdesc> </parameter> <parameter name="timeout" unique="1"> <getopt mixed="-t" /> <content type="string" /> <shortdesc>Timeout (sec) for IPMI operation</shortdesc> </parameter> <parameter name="cipher" unique="1"> <getopt mixed="-C" /> <content type="string" /> <shortdesc>Ciphersuite to use (same as ipmitool -C parameter)</shortdesc> </parameter> <parameter name="method" unique="1"> <getopt mixed="-M" /> <content type="string" default="onoff"/> <shortdesc>Method to fence (onoff or cycle)</shortdesc> </parameter> <parameter name="power_wait" unique="1"> <getopt mixed="-T" /> <content type="string" default="2"/> <shortdesc>Wait X seconds after on/off operation</shortdesc> </parameter> <parameter name="delay" unique="1"> <getopt mixed="-f" /> <content type="string" /> <shortdesc>Wait X seconds before fencing is started</shortdesc> </parameter> <parameter name="verbose" unique="1"> <getopt mixed="-v" /> <content type="boolean" /> <shortdesc>Verbose mode</shortdesc> </parameter> </parameters> <actions> <action name="on" /> <action name="off" /> <action name="reboot" /> <action name="status" /> <action name="diag" /> <action name="list" /> <action name="monitor" /> <action name="metadata" /> </actions> </resource-agent>
# crm crm(live)# cib new stonith INFO: stonith shadow CIB created crm(stonith)# configure primitive impi-fencing stonith::fence_ipmilan \ params pcmk_host_list="pcmk-1 pcmk-2" ipaddr=10.0.0.1 login=testuser passwd=abc123 \ op monitor interval="60s"
crm(stonith)# configure property stonith-enabled="true" crm(stonith)# configure shownode pcmk-1 node pcmk-2 primitive WebData ocf:linbit:drbd \ params drbd_resource="wwwdata" \ op monitor interval="60s" primitive WebFS ocf:heartbeat:Filesystem \ params device="/dev/drbd/by-res/wwwdata" directory="/var/www/html" fstype="gfs2" primitive WebSite ocf:heartbeat:apache \ params configfile="/etc/httpd/conf/httpd.conf" \ op monitor interval="1min" primitive ClusterIP ocf:heartbeat:IPaddr2 \ params ip="192.168.122.101" cidr_netmask="32" clusterip_hash="sourceip" \ op monitor interval="30s"primitive ipmi-fencing stonith::fence_ipmilan \ params pcmk_host_list="pcmk-1 pcmk-2" ipaddr=10.0.0.1 login=testuser passwd=abc123 \ op monitor interval="60s"ms WebDataClone WebData \ meta master-max="2" master-node-max="1" clone-max="2" clone-node-max="1" notify="true" clone WebFSClone WebFS clone WebIP ClusterIP \ meta globally-unique="true" clone-max="2" clone-node-max="2" clone WebSiteClone WebSite colocation WebSite-with-WebFS inf: WebSiteClone WebFSClone colocation fs_on_drbd inf: WebFSClone WebDataClone:Master colocation website-with-ip inf: WebSiteClone WebIP order WebFS-after-WebData inf: WebDataClone:promote WebFSClone:start order WebSite-after-WebFS inf: WebFSClone WebSiteClone order apache-after-ip inf: WebIP WebSiteClone property $id="cib-bootstrap-options" \ dc-version="1.1.5-bdd89e69ba545404d02445be1f3d72e6a203ba2f" \ cluster-infrastructure="openais" \ expected-quorum-votes="2" \ stonith-enabled="true" \ no-quorum-policy="ignore" rsc_defaults $id="rsc-options" \ resource-stickiness="100" crm(stonith)# cib commit stonithINFO: commited 'stonith' shadow CIB to the cluster crm(stonith)# quit bye
Indice
crm_mon.
Esempio 14.1. A bare-bones status entry for a healthy node called cl-virt-1
<node_state id="cl-virt-1" uname="cl-virt-2" ha="active" in_ccm="true" crmd="online" join="member" expected="member" crm-debug-origin="do_update_resource"> <transient_attributes id="cl-virt-1"/> <lrm id="cl-virt-1"/> </node_state>
Tabella 14.1. Sorgenti autoritative per le informazioni di stato
| Dataset | Sorgente autoritativa |
|---|---|
node_state fields
|
crmd
|
transient_attributes tag
|
attrd
|
lrm tag
|
lrmd
|
node_state objects are named as they are largely for historical reasons and are rooted in Pacemaker’s origins as the Heartbeat resource manager.
Tabella 14.2. Campi relativi allo status dei nodi
| Campo | Descrizione |
|---|---|
id
| |
uname
| |
ha
| |
in_ccm
| |
crmd
| |
join
| |
expected
| |
crm-debug-origin
|
Esempio 14.2. Example set of transient node attributes for node "cl-virt-1"
<transient_attributes id="cl-virt-1"> <instance_attributes id="status-cl-virt-1"> <nvpair id="status-cl-virt-1-pingd" name="pingd" value="3"/> <nvpair id="status-cl-virt-1-probe_complete" name="probe_complete" value="true"/> <nvpair id="status-cl-virt-1-fail-count-pingd:0" name="fail-count-pingd:0" value="1"/> <nvpair id="status-cl-virt-1-last-failure-pingd:0" name="last-failure-pingd:0" value="1239009742"/> </instance_attributes> </transient_attributes>
pingd:0 resource has failed once, at Mon Apr 6 11:22:22 2009. [15] We also see that the node is connected to three "pingd" peers and that all known resources have been checked for on this machine (probe_complete).
lrm_resources tag (a child of the lrm tag). The information stored here includes enough information for the cluster to stop the resource safely if it is removed from the configuration section. Specifically the resource’s id, class, type and provider are stored.
Esempio 14.3. Un record della risorsa apcstonith
<lrm_resource id="apcstonith" type="apcmastersnmp" class="stonith"/>
resource, action e interval. La concatenazione di valori in questa tupla viene usata per creare l'id dell'oggetto lrm_rsc_op.
Tabella 14.3. Contents of an lrm_rsc_op job
| Campo | Descrizione |
|---|---|
id
|
Identifier for the job constructed from the resource’s
id, operation and interval.
|
call-id
|
The job’s ticket number. Used as a sort key to determine the order in which the jobs were executed.
|
operation
|
L'azione con cui il resource agent è stato invocato.
|
interval
|
The frequency, in milliseconds, at which the operation will be repeated. A one-off job is indicated by 0.
|
op-status
|
The job’s status. Generally this will be either 0 (done) or -1 (pending). Rarely used in favor of
rc-code.
|
rc-code
|
The job’s result. Refer to Sezione B.4, «OCF Return Codes» for details on what the values here mean and how they are interpreted.
|
last-run
|
Indicatore diagnostico. Data/ora locale della macchina in cui il job è stato eseguito, in secondi da epoch (00:00:00 UTC on 1 January 1970).
|
last-rc-change
|
Diagnostic indicator. Machine local date/time, in seconds since epoch, at which the job first returned the current value of
rc-code.
|
exec-time
|
Diagnostic indicator. Time, in milliseconds, that the job was running for.
|
queue-time
|
Diagnostic indicator. Time, in seconds, that the job was queued for in the LRMd.
|
crm_feature_set
|
The version which this job description conforms to. Used when processing
op-digest.
|
transition-key
|
A concatenation of the job’s graph action number, the graph number, the expected result and the UUID of the crmd instance that scheduled it. This is used to construct
transition-magic (below).
|
transition-magic
|
A concatenation of the job’s
op-status, rc-code and transition-key. Guaranteed to be unique for the life of the cluster (which ensures it is part of CIB update notifications) and contains all the information needed for the crmd to correctly analyze and process the completed job. Most importantly, the decomposed elements tell the crmd if the job entry was expected and whether it failed.
|
op-digest
|
An MD5 sum representing the parameters passed to the job. Used to detect changes to the configuration, to restart resources if necessary.
|
crm-debug-origin
|
Indicatore diagnostico. L'originie degli attuali valori.
|
Esempio 14.4. A monitor operation (determines current state of the apcstonith resource)
<lrm_resource id="apcstonith" type="apcmastersnmp" class="stonith"> <lrm_rsc_op id="apcstonith_monitor_0" operation="monitor" call-id="2" rc-code="7" op-status="0" interval="0" crm-debug-origin="do_update_resource" crm_feature_set="3.0.1" op-digest="2e3da9274d3550dc6526fb24bfcbcba0" transition-key="22:2:7:2668bbeb-06d5-40f9-936d-24cb7f87006a" transition-magic="0:7;22:2:7:2668bbeb-06d5-40f9-936d-24cb7f87006a" last-run="1239008085" last-rc-change="1239008085" exec-time="10" queue-time="0"/> </lrm_resource>
apcstonith resource.
transition-key, we can see that this was the 22nd action of the 2nd graph produced by this instance of the crmd (2668bbeb-06d5-40f9-936d-24cb7f87006a).
transition-key contains a 7, this indicates that the job expects to find the resource inactive.
rc-code property, we see that this was the case.
Esempio 14.5. Storico di una risorsa clone pingd con job multipli
<lrm_resource id="pingd:0" type="pingd" class="ocf" provider="pacemaker"> <lrm_rsc_op id="pingd:0_monitor_30000" operation="monitor" call-id="34" rc-code="0" op-status="0" interval="30000" crm-debug-origin="do_update_resource" crm_feature_set="3.0.1" transition-key="10:11:0:2668bbeb-06d5-40f9-936d-24cb7f87006a" ... last-run="1239009741" last-rc-change="1239009741" exec-time="10" queue-time="0"/> <lrm_rsc_op id="pingd:0_stop_0" operation="stop" crm-debug-origin="do_update_resource" crm_feature_set="3.0.1" call-id="32" rc-code="0" op-status="0" interval="0" transition-key="11:11:0:2668bbeb-06d5-40f9-936d-24cb7f87006a" ... last-run="1239009741" last-rc-change="1239009741" exec-time="10" queue-time="0"/> <lrm_rsc_op id="pingd:0_start_0" operation="start" call-id="33" rc-code="0" op-status="0" interval="0" crm-debug-origin="do_update_resource" crm_feature_set="3.0.1" transition-key="31:11:0:2668bbeb-06d5-40f9-936d-24cb7f87006a" ... last-run="1239009741" last-rc-change="1239009741" exec-time="10" queue-time="0" /> <lrm_rsc_op id="pingd:0_monitor_0" operation="monitor" call-id="3" rc-code="0" op-status="0" interval="0" crm-debug-origin="do_update_resource" crm_feature_set="3.0.1" transition-key="23:2:7:2668bbeb-06d5-40f9-936d-24cb7f87006a" ... last-run="1239008085" last-rc-change="1239008085" exec-time="20" queue-time="0"/> </lrm_resource>
call-id before interpreting them.
call-id of 3
call-id of 32
call-id of 33
call-id of 34
stop operation with a lower call-id than that of the start operation, we can conclude that the resource has been restarted. Specifically this occurred as part of actions 11 and 31 of transition 11 from the crmd instance with the key 2668bbeb…. This information can be helpful for locating the relevant section of the logs when looking for the source of a failure.
date command to print a human readable of any seconds-since-epoch value: # date -d @<parameter>number</parameter>
Indice
CTR (Cluster Ticket Registry).
CTR (Cluster Ticket Registry) mechanism. It guarantees that the cluster resources will be highly available across different cluster sites. This is achieved by using so-called tickets that are treated as failover domain between cluster sites, in case a site should be down.
rsc_ticket dependencies. Only if the ticket is available at a site, the respective resources are started. Vice versa, if the ticket is revoked, the resources depending on that ticket need to be stopped.
have-quorum flag as a special, cluster-wide ticket that is granted in case of node majority.)
CTR mechanism described further below.
true (the site has the ticket) or false (the site does not have the ticket). The absence of a certain ticket (during the initial state of the multi-site cluster) is also reflected by the value false.
Dead Man Dependency was introduced:
loss-policy="fence" in rsc_ticket constraints.
CTR is a network daemon that handles granting, revoking, and timing out "tickets". The participating clusters would run the daemons that would connect to each other, exchange information on their connectivity details, and vote on which site gets which ticket(s).
rsc_ticket constraint lets you specify the resources depending on a certain ticket. Together with the constraint, you can set a loss-policy that defines what should happen to the respective resources if the ticket is revoked.
loss-policy can have the following values:
rsc_ticket constraint:
<rsc_ticket id="rsc1-req-ticketA" rsc="rsc1" ticket="ticketA" loss-policy="fence"/>
rsc1-req-ticketA. It defines that the resource rsc1 depends on ticketA and that the node running the resource should be fenced in case ticketA is revoked.
rsc1 was a multi-state resource that can run in master or slave mode, you may want to configure that only rsc1's master mode depends on ticketA. With the following configuration, rsc1 will be demoted to slave mode if ticketA is revoked:
<rsc_ticket id="rsc1-req-ticketA" rsc="rsc1" rsc-role="Master" ticket="ticketA" loss-policy="demote"/>
rsc_ticket constraints to let multiple resources depend on the same ticket.
rsc_ticket also supports resource sets. So one can easily list all the resources in one rsc_ticket constraint. For example:
<rsc_ticket id="resources-dep-ticketA" ticket="ticketA" loss-policy="fence"> <resource_set id="resources-dep-ticketA-0" role="Started"> <resource_ref id="rsc1"/> <resource_ref id="group1"/> <resource_ref id="clone1"/> </resource_set> <resource_set id="resources-dep-ticketA-1" role="Master"> <resource_ref id="ms1"/> </resource_set> </rsc_ticket>
roles in one rsc_ticket constraint. There’s no dependency between the two resource sets. And there’s no dependency among the resources within a resource set. Each of the resources just depends on ticketA.
rsc_ticket constraints, and even referencing them within resource sets, is also supported.
rsc_ticket.
crm_ticket command line tool to grant and revoke tickets.
# crm_ticket --ticket ticketA --grant# crm_ticket --ticket ticketA --revokeImportante
crm_ticket command with great care as they cannot help verify if the same ticket is already granted elsewhere.
Cluster Ticket Registry or so-called Cluster Ticket Manager.
loss-policy you set within the rsc_ticket constraint.
booth client command. After you have initially granted a ticket to a site, the booth mechanism will take over and manage the ticket automatically.
Importante
booth client command line tool can be used to grant, list, or revoke tickets. The booth client commands work on any machine where the booth daemon is running.
Booth, only use booth client for manual intervention instead of crm_ticket. That can make sure the same ticket will only be owned by one cluster site at a time.
Nota
Arbitrator
A can no longer communicate with site B, there are two possible causes for that:
A network failure between A and B.
B is down.
C (the arbitrator) can still communicate with site B, site B must still be up and running.
# crm_ticket --info# crm_mon --tickets# crm_ticket --ticket ticketA --constraintsloss-policy="fence", the dependent resources could not be gracefully stopped/demoted, and even, other unrelated resources could be impacted.
standby first with:
# crm_ticket --ticket ticketA --standby# crm_ticket --ticket ticketA --activateIndice
<primitive id="custom-app" class="ocf" provider="bigCorp" type="bigApp"/>
Tabella B.1. Azioni richieste per gli agenti OCF
| Azione | Descrizione | Istruzioni |
|---|---|---|
start
|
Avvia la risorsa
| |
stop
|
Ferma la risorsa
| |
monitor
|
Check the resource’s state
|
NOTA: Lo script di monitor dovrebbe controllare lo stato della risorsa solo sulla macchina locale.
|
meta-data
|
Descrive la risorsa
|
NOTE: This is not performed as root.
|
validate-all
|
Verify the supplied parameters
|
Tabella B.2. Azioni facoltative per gli agent OCF
| Azione | Descrizione | Istruzioni |
|---|---|---|
promote
|
Promote the local instance of a multi-state resource to the master/primary state.
| |
demote
|
Demote the local instance of a multi-state resource to the slave/secondary state.
| |
notify
|
Used by the cluster to send the agent pre and post notification events telling the resource what has happened and will happen.
|
recover - a variant of the start action, this should try to recover a resource locally.
Tabella B.3. Tipi di ripristino effettuati dal cluster
| Type | Descrizione | Azione intrapresa dal cluster |
|---|---|---|
soft
|
Si è verificato un errore transitorio
| |
hard
|
Si è verificato un errore non transitorio che potrebbe essere specificamente correlato al nodo attuale
| |
fatal
|
A non-transient error that will be common to all cluster nodes (eg. a bad configuration was specified)
|
Tabella B.4. OCF Return Codes and their Recovery Types
| RC | OCF Alias | Descrizione | RT |
|---|---|---|---|
0
|
OCF_SUCCESS
|
soft
| |
1
|
OCF_ERR_GENERIC
|
soft
| |
2
|
OCF_ERR_ARGS
|
hard
| |
3
|
OCF_ERR_UNIMPLEMENTED
|
hard
| |
4
|
OCF_ERR_PERM
|
hard
| |
5
|
OCF_ERR_INSTALLED
|
hard
| |
6
|
OCF_ERR_CONFIGURED
|
fatal
| |
7
|
OCF_NOT_RUNNING
|
N/A
| |
8
|
OCF_RUNNING_MASTER
|
soft
| |
9
|
OCF_FAILED_MASTER
|
soft
| |
other
|
NA
|
soft
|
OCF_SUCCESS) can be considered to have failed.
OCF_ERR_UNIMPLEMENTED do not cause any type of recovery
Rules, instance_attributes, meta_attributes ed i set di operazioni possono essere definiti inizialmente e referenziati in diversi posti. Vedere Sezione 9.4, «Riutilizzare regole, opzioni e set di operazioni»
cibadmin
master_slave è stato rinominato in master
attributes è stato rimosso
pre-req è stato rinominato in requires
interval, start/stop must have it set to zero
stonith-enabled ora per default è true
stonith-enabled è true (o non valorizzato) e non è stata definita nessuna risorsa STONITH
resource-failure-stickiness è stata rimpiazzata da migration-threshold. Vedere Sezione 9.3.2, «Spostare risorse in seguito ad un fallimento»
crm_config. Vedere invece Sezione 5.5, «Settaggio dei valori di default globali per le opzioni delle risorse» e Sezione 5.7.2, «Settaggio dei valori di default globali per le operazioni».
Indice
Avvertimento
1.2.3.4 in a cluster communicating on port 1234 (without peer authentication and message encryption) is shown below.
totem {
version: 2
secauth: off
threads: 0
interface {
ringnumber: 0
bindnetaddr: 1.2.3.4
mcastaddr: 239.255.1.1
mcastport: 1234
}
}
logging {
fileline: off
to_syslog: yes
syslog_facility: daemon
}
amf {
mode: disabled
}
bindnetaddr and mcastaddr with their IPv6 equivalents, eg.
bindnetaddr: fec0::1:a800:4ff:fe00:20 mcastaddr: ff05::1
aisexec {
user: root
group: root
}
service {
name: pacemaker
ver: 0
}
lrmd in particular) have sufficient privileges to perform the actions requested of it. After all, a cluster manager that can’t add an IP address or start apache is of little use.
Indice
Tabella E.1. Riepilogo delle metodologie di aggiornamento
| Tipo | Disponibile fra tutte le versioni del software | Interruzione del servizio in fase di aggiornamento | Ripristino del servizio in fase di aggiornamento | Esercizi di Logica Di Failover/Configurazione | Allows change of cluster stack type [a] |
|---|---|---|---|---|---|
|
sì
|
sempre
|
N/A
|
no
|
sì
| |
|
no
|
sempre
|
sì
|
sì
|
no
| |
|
sì
|
solo in seguito a fallimenti
|
no
|
no
|
sì
| |
[a]
For example, switching from Heartbeat to Corosync. Consult the Heartbeat or Corosync documentation to see if upgrading them to a newer version is also supported.
| |||||
crm_verify tool if available.
Importante
crm_verify tool if available. .. Start the cluster stack.
Tabella E.2. Tabella della compatibilità delle versioni
| Versione da installare | Ultima versione compatibile |
|---|---|
|
Pacemaker 1.0.x
|
Pacemaker 1.0.0
|
|
Pacemaker 0.7.x
|
Pacemaker 0.6 o Heartbeat 2.1.3
|
|
Pacemaker 0.6.x
|
Heartbeat 2.0.8
|
|
Heartbeat 2.1.3 (o precedenti)
|
Heartbeat 2.0.4
|
|
Heartbeat 2.0.4 (o precedenti)
|
Heartbeat 2.0.0
|
|
Heartbeat 2.0.0
|
Nessuna. Utilizzare una diversa strategia di aggiornamento.
|
# crm_attribute -t crm_config -n is-managed-default -v falseis-managed, make sure it is set to false (so that the cluster will not stop it)
# crm_resource -t primitive -r $rsc_id -p is-managed -v falsecrm_verify tool if available.
# crm_attribute -t crm_config -n is-managed-default -v trueis-managed reset it to true (so the cluster can recover the service if it fails) if desired:
# crm_resource -t primitive -r $rsc_id -p is-managed -v trueIndice
# crm_shadow --create upgrade06# crm_verify --live-check# cibadmin --upgrade# crm_shadow --diff# crm_shadow --edit$EDITOR environment variable)
# crm_simulate --live-check --save-dotfile upgrade06.dot -S # graphviz upgrade06.dot
crm_simulate
# crm_shadow --commit upgrade06 --force# xsltproc /path/to/upgrade06.xsl config06.xml > config10.xml# xmllint --relaxng /path/to/pacemaker.rng config10.xmlsome_service is configured correctly and currently not active, the following sequence will help you determine if it is LSB compatible:
# /etc/init.d/some_service start ; echo "result: $?"# /etc/init.d/some_service status ; echo "result: $?"# /etc/init.d/some_service start ; echo "result: $?"# /etc/init.d/some_service stop ; echo "result: $?"# /etc/init.d/some_service status ; echo "result: $?"# /etc/init.d/some_service stop ; echo "result: $?"Esempio H.1. Una configurazione vuota
<cib admin_epoch="0" epoch="0" num_updates="0" have-quorum="false"> <configuration> <crm_config/> <nodes/> <resources/> <constraints/> </configuration> <status/> </cib>
Esempio H.2. Simple Configuration - 2 nodes, some cluster options and a resource
<cib admin_epoch="0" epoch="1" num_updates="0" have-quorum="false" validate-with="pacemaker-1.0"> <configuration> <crm_config> <nvpair id="option-1" name="symmetric-cluster" value="true"/> <nvpair id="option-2" name="no-quorum-policy" value="stop"/> </crm_config> <op_defaults> <nvpair id="op-default-1" name="timeout" value="30s"/> </op_defaults> <rsc_defaults> <nvpair id="rsc-default-1" name="resource-stickiness" value="100"/> <nvpair id="rsc-default-2" name="migration-threshold" value="10"/> </rsc_defaults> <nodes> <node id="xxx" uname="c001n01" type="normal"/> <node id="yyy" uname="c001n02" type="normal"/> </nodes> <resources> <primitive id="myAddr" class="ocf" provider="heartbeat" type="IPaddr"> <operations> <op id="myAddr-monitor" name="monitor" interval="300s"/> </operations> <instance_attributes> <nvpair name="ip" value="10.0.200.30"/> </instance_attributes> </primitive> </resources> <constraints> <rsc_location id="myAddr-prefer" rsc="myAddr" node="c001n01" score="INFINITY"/> </constraints> </configuration> <status/> </cib>
c001n01 until either the resource fails 10 times or the host shuts down.
Esempio H.3. Advanced configuration - groups and clones with stonith
<cib admin_epoch="0" epoch="1" num_updates="0" have-quorum="false" validate-with="pacemaker-1.0"> <configuration> <crm_config> <nvpair id="option-1" name="symmetric-cluster" value="true"/> <nvpair id="option-2" name="no-quorum-policy" value="stop"/> <nvpair id="option-3" name="stonith-enabled" value="true"/> </crm_config> <op_defaults> <nvpair id="op-default-1" name="timeout" value="30s"/> </op_defaults> <rsc_defaults> <nvpair id="rsc-default-1" name="resource-stickiness" value="100"/> <nvpair id="rsc-default-2" name="migration-threshold" value="10"/> </rsc_defaults> <nodes> <node id="xxx" uname="c001n01" type="normal"/> <node id="yyy" uname="c001n02" type="normal"/> <node id="zzz" uname="c001n03" type="normal"/> </nodes> <resources> <primitive id="myAddr" class="ocf" provider="heartbeat" type="IPaddr"> <operations> <op id="myAddr-monitor" name="monitor" interval="300s"/> </operations> <instance_attributes> <nvpair name="ip" value="10.0.200.30"/> </instance_attributes> </primitive> <group id="myGroup"> <primitive id="database" class="lsb" type="oracle"> <operations> <op id="database-monitor" name="monitor" interval="300s"/> </operations> </primitive> <primitive id="webserver" class="lsb" type="apache"> <operations> <op id="webserver-monitor" name="monitor" interval="300s"/> </operations> </primitive> </group> <clone id="STONITH"> <meta_attributes id="stonith-options"> <nvpair id="stonith-option-1" name="globally-unique" value="false"/> </meta_attributes> <primitive id="stonithclone" class="stonith" type="external/ssh"> <operations> <op id="stonith-op-mon" name="monitor" interval="5s"/> </operations> <instance_attributes id="stonith-attrs"> <nvpair id="stonith-attr-1" name="hostlist" value="c001n01,c001n02"/> </instance_attributes> </primitive> </clone> </resources> <constraints> <rsc_location id="myAddr-prefer" rsc="myAddr" node="c001n01" score="INFINITY"/> <rsc_colocation id="group-with-ip" rsc="myGroup" with-rsc="myAddr" score="INFINITY"/> </constraints> </configuration> <status/> </cib>
| Diario delle Revisioni | ||||
|---|---|---|---|---|
| Revisione 1-1 | 19 Oct 2009 | |||
| ||||
| Revisione 2-1 | 26 Oct 2009 | |||
| ||||
| Revisione 3-1 | Tue Nov 12 2009 | |||
| ||||
| Revisione 4-1 | Mon Oct 8 2012 | |||
| ||||